String Grouper
![]()
Click to see image

string_grouper is a library that makes finding groups of similar strings within a single, or multiple, lists of strings easy — and fast. string_grouper uses tf-idf to calculate cosine similarities within a single list or between two lists of strings. The full process is described in the blog Super Fast String Matching in Python.
Installing
pip install string-grouper
Usage
import pandas as pd
from string_grouper import match_strings, match_most_similar, \
group_similar_strings, compute_pairwise_similarities, \
StringGrouperAs shown above, the library may be used together with pandas, and contains four high level functions (match_strings, match_most_similar, group_similar_strings, and compute_pairwise_similarities) that can be used directly, and one class (StringGrouper) that allows for a more interactive approach.
The permitted calling patterns of the four functions, and their return types, are:
| Function | Parameters | pandas Return Type |
|---|---|---|
match_strings |
(master, **kwargs) |
DataFrame |
match_strings |
(master, duplicates, **kwargs) |
DataFrame |
match_strings |
(master, master_id=id_series, **kwargs) |
DataFrame |
match_strings |
(master, duplicates, master_id, duplicates_id, **kwargs) |
DataFrame |
match_most_similar |
(master, duplicates, **kwargs) |
Series (if kwarg ignore_index=True) otherwise DataFrame (default) |
match_most_similar |
(master, duplicates, master_id, duplicates_id, **kwargs) |
DataFrame |
group_similar_strings |
(strings_to_group, **kwargs) |
Series (if kwarg ignore_index=True) otherwise DataFrame (default) |
group_similar_strings |
(strings_to_group, strings_id, **kwargs) |
DataFrame |
compute_pairwise_similarities |
(string_series_1, string_series_2, **kwargs) |
Series |
In the rest of this document the names, Series and DataFrame, refer to the familiar pandas object types.
Parameters:
| Name | Description |
|---|---|
master |
A Series of strings to be matched with themselves (or with those in duplicates). |
duplicates |
A Series of strings to be matched with those of master. |
master_id (or id_series) |
A Series of IDs corresponding to the strings in master. |
duplicates_id |
A Series of IDs corresponding to the strings in duplicates. |
strings_to_group |
A Series of strings to be grouped. |
strings_id |
A Series of IDs corresponding to the strings in strings_to_group. |
string_series_1(_2) |
A Series of strings each of which is to be compared with its corresponding string in string_series_2(_1). |
| `kwargs`** | Keyword arguments (see below). |
New in version 0.6.0: each of the high-level functions listed above also has a StringGrouper method counterpart of the same name and parameters. Calling such a method of any instance of StringGrouper will not rebuild the instance's underlying corpus to make string-comparisons but rather use it to perform the string-comparisons. The input Series to the method (master, duplicates, and so on) will thus be encoded, or transformed, into tf-idf matrices, using this corpus. For example:
# Build a corpus using strings in the pandas Series master:
sg = StringGrouper(master)
# The following method-calls will compare strings first in
# pandas Series new_master_1 and next in new_master_2
# using the corpus already built above without rebuilding or
# changing it in any way:
matches1 = sg.match_strings(new_master_1)
matches2 = sg.match_strings(new_master_2)Functions:
-
match_stringsReturns a
DataFramecontaining similarity-scores of all matching pairs of highly similar strings frommaster(andduplicatesif given). Each matching pair in the output appears in its own row/record consisting of- its "left" part: a string (with/without its index-label) from
master, - its similarity score, and
- its "right" part: a string (with/without its index-label) from
duplicates(ormasterifduplicatesis not given),
in that order. Thus the column-names of the output are a collection of three groups:
- The name of
masterand the name(s) of its index (or index-levels) all prefixed by the string'left_', 'similarity'whose column has the similarity-scores as values, and- The name of
duplicates(ormasterifduplicatesis not given) and the name(s) of its index (or index-levels) prefixed by the string'right_'.
Indexes (or their levels) only appear when the keyword argument
ignore_index=False(the default). (See tutorials/ignore_index_and_replace_na.md for a demonstration.)If either
masterorduplicateshas no name, it assumes the name'side'which is then prefixed as described above. Similarly, if any of the indexes (or index-levels) has no name it assumes itspandasdefault name ('index','level_0', and so on) and is then prefixed as described above.In other words, if only parameter
masteris given, the function will return pairs of highly similar strings withinmaster. This can be seen as a self-join where both'left_'and'right_'prefixed columns come frommaster. If both parametersmasterandduplicatesare given, it will return pairs of highly similar strings betweenmasterandduplicates. This can be seen as an inner-join where'left_'and'right_'prefixed columns come frommasterandduplicatesrespectively.The function also supports optionally inputting IDs (
master_idandduplicates_id) corresponding to the strings being matched. In which case, the output includes two additional columns whose names are the names of these optionalSeriesprefixed by'left_'and'right_'accordingly, and containing the IDs corresponding to the strings in the output. If any of theseSerieshas no name, then it assumes the name'id'and is then prefixed as described above. - its "left" part: a string (with/without its index-label) from
-
match_most_similarIf
ignore_index=True, returns aSeriesof strings, where for each string induplicatesthe most similar string inmasteris returned. If there are no similar strings inmasterfor a given string induplicates(because there is no potential match where the cosine similarity is above the threshold [default: 0.8]) then the original string induplicatesis returned. The outputSeriesthus has the same length and index asduplicates.For example, if an input
Serieswith the values\['foooo', 'bar', 'baz'\]is passed as the argumentmaster, and\['foooob', 'bar', 'new'\]as the values of the argumentduplicates, the function will return aSerieswith values:\['foooo', 'bar', 'new'\].The name of the output
Seriesis the same as that ofmasterprefixed with the string'most_similar_'. Ifmasterhas no name, it is assumed to have the name'master'before being prefixed.If
ignore_index=False(the default),match_most_similarreturns aDataFramecontaining the sameSeriesdescribed above as one of its columns. So it inherits the same index and length asduplicates. The rest of its columns correspond to the index (or index-levels) ofmasterand thus contain the index-labels of the most similar strings being output as values. If there are no similar strings inmasterfor a given string induplicatesthen the value(s) assigned to this index-column(s) for that string isNaNby default. However, if the keyword argumentreplace_na=True, then theseNaNvalues are replaced with the index-label(s) of that string induplicates. Note that such replacements can only occur if the indexes ofmasterandduplicateshave the same number of levels. (See tutorials/ignore_index_and_replace_na.md for a demonstration.)Each column-name of the output
DataFramehas the same name as its corresponding column, index, or index-level ofmasterprefixed with the string'most_similar_'.If both parameters
master_idandduplicates_idare also given, then aDataFrameis always returned with the same column(s) as described above, but with an additional column containing those IDs from these inputSeriescorresponding to the output strings. This column's name is the same as that ofmaster_idprefixed in the same way as described above. Ifmaster_idhas no name, it is assumed to have the name'master_id'before being prefixed. -
group_similar_stringsTakes a single
Seriesof strings (strings_to_group) and groups them by assigning to each string one string fromstrings_to_groupchosen as the group-representative for each group of similar strings found. (See tutorials/group_representatives.md for details on how the the group-representatives are chosen.)If
ignore_index=True, the output is aSeries(with the same name asstrings_to_groupprefixed by the string'group_rep_') of the same length and index asstrings_to_groupcontaining the group-representative strings. Ifstrings_to_grouphas no name then the name of the returnedSeriesis'group_rep'.For example, an input Series with values:
\['foooo', 'foooob', 'bar'\]will return\['foooo', 'foooo', 'bar'\]. Here'foooo'and'foooob'are grouped together into group'foooo'because they are found to be similar. Another example can be found below.If
ignore_index=False, the output is aDataFramecontaining the above outputSeriesas one of its columns with the same name. The remaining column(s) correspond to the index (or index-levels) ofstrings_to_groupand contain the index-labels of the group-representatives as values. These columns have the same names as their counterparts prefixed by the string'group_rep_'.If
strings_idis also given, then the IDs fromstrings_idcorresponding to the group-representatives are also returned in an additional column (with the same name asstrings_idprefixed as described above). Ifstrings_idhas no name, it is assumed to have the name'id'before being prefixed. -
compute_pairwise_similaritiesReturns a
Seriesof cosine similarity scores the same length and index asstring_series_1. Each score is the cosine similarity between the pair of strings in the same position (row) in the two inputSeries,string_series_1andstring_series_2, as the position of the score in the outputSeries. This can be seen as an element-wise comparison between the two inputSeries.
All functions are built using a class StringGrouper. This class can be used through pre-defined functions, for example the four high level functions above, as well as using a more interactive approach where matches can be added or removed if needed by calling the StringGrouper class directly.
Options:
-
kwargsAll keyword arguments not mentioned in the function definitions above are used to update the default settings. The following optional arguments can be used:
ngram_size: The amount of characters in each n-gram. Default is3.regex: The regex string used to clean-up the input string. Default isr"[,-./]|\s".ignore_case: Determines whether or not letter case in strings should be ignored. Defaults toTrue.tfidf_matrix_dtype: The datatype for the tf-idf values of the matrix components. Allowed values arenumpy.float32andnumpy.float64. Default isnumpy.float32. (Note:numpy.float32often leads to faster processing and a smaller memory footprint albeit less numerical precision thannumpy.float64.)max_n_matches: The maximum number of matching strings inmasterallowed per string induplicates. Default is the total number of strings inmaster.min_similarity: The minimum cosine similarity for two strings to be considered a match. Defaults to0.8number_of_processes: The number of processes used by the cosine similarity calculation. Defaults tonumber of cores on a machine - 1.ignore_index: Determines whether indexes are ignored or not. IfFalse(the default), index-columns will appear in the output, otherwise not. (See tutorials/ignore_index_and_replace_na.md for a demonstration.)replace_na: For functionmatch_most_similar, determines whetherNaNvalues in index-columns are replaced or not by index-labels fromduplicates. Defaults toFalse. (See tutorials/ignore_index_and_replace_na.md for a demonstration.)include_zeroes: Whenmin_similarity≤ 0, determines whether zero-similarity matches appear in the output. Defaults toTrue. (See tutorials/zero_similarity.md.) Note: Ifinclude_zeroesisTrueand the kwargmax_n_matchesis set then it must be sufficiently high to capture all nonzero-similarity-matches, otherwise an error is raised andstring_groupersuggests an alternative value formax_n_matches. To allowstring_grouperto automatically use the appropriate value formax_n_matchesthen do not set this kwarg at all.group_rep: For functiongroup_similar_strings, determines how group-representatives are chosen. Allowed values are'centroid'(the default) and'first'. See tutorials/group_representatives.md for an explanation.force_symmetries: In cases whereduplicatesisNone, specifies whether corrections should be made to the results to account for symmetry, thus compensating for those losses of numerical significance which violate the symmetries. Defaults toTrue.n_blocks: This parameter is a tuple of twoints provided to help boost performance, if possible, of processing large DataFrames (see Subsection Performance), by splitting the DataFrames inton_blocks[0]blocks for the left operand (of the underlying matrix multiplication) and inton_blocks[1]blocks for the right operand before performing the string-comparisons block-wise. Defaults to'guess', in which case the numbers of blocks are estimated based on previous empirical results. Ifn_blocks = 'auto', then splitting is done automatically in the event of anOverflowError.
Examples
In this section we will cover a few use cases for which string_grouper may be used. We will use the same data set of company names as used in: Super Fast String Matching in Python.
Find all matches within a single data set
import pandas as pd
import numpy as np
from string_grouper import match_strings, match_most_similar, \
group_similar_strings, compute_pairwise_similarities, \
StringGroupercompany_names = '/media/chris/data/dev/name_matching/data/sec_edgar_company_info.csv'
# We only look at the first 50k as an example:
companies = pd.read_csv(company_names)[0:50000]
# Create all matches:
matches = match_strings(companies['Company Name'])
# Look at only the non-exact matches:
matches[matches['left_Company Name'] != matches['right_Company Name']].head()| left_index | left_Company Name | similarity | right_Company Name | right_index | |
|---|---|---|---|---|---|
| 15 | 14 | 0210, LLC | 0.870291 | 90210 LLC | 4211 |
| 167 | 165 | 1 800 MUTUALS ADVISOR SERIES | 0.931615 | 1 800 MUTUALS ADVISORS SERIES | 166 |
| 168 | 166 | 1 800 MUTUALS ADVISORS SERIES | 0.931615 | 1 800 MUTUALS ADVISOR SERIES | 165 |
| 172 | 168 | 1 800 RADIATOR FRANCHISE INC | 1.000000 | 1-800-RADIATOR FRANCHISE INC. | 201 |
| 178 | 173 | 1 FINANCIAL MARKETPLACE SECURITIES LLC ... | 0.949364 | 1 FINANCIAL MARKETPLACE SECURITIES, LLC | 174 |
Find all matches in between two data sets.
The match_strings function finds similar items between two data sets as well. This can be seen as an inner join between two data sets:
# Create a small set of artificial company names:
duplicates = pd.Series(['S MEDIA GROUP', '012 SMILE.COMMUNICATIONS', 'foo bar', 'B4UTRADE COM CORP'])
# Create all matches:
matches = match_strings(companies['Company Name'], duplicates)
matches| left_index | left_Company Name | similarity | right_side | right_index | |
|---|---|---|---|---|---|
| 0 | 12 | 012 SMILE.COMMUNICATIONS LTD | 0.944092 | 012 SMILE.COMMUNICATIONS | 1 |
| 1 | 49777 | B.A.S. MEDIA GROUP | 0.854383 | S MEDIA GROUP | 0 |
| 2 | 49855 | B4UTRADE COM CORP | 1.000000 | B4UTRADE COM CORP | 3 |
| 3 | 49856 | B4UTRADE COM INC | 0.810217 | B4UTRADE COM CORP | 3 |
| 4 | 49857 | B4UTRADE CORP | 0.878276 | B4UTRADE COM CORP | 3 |
Out of the four company names in duplicates, three companies are found in the original company data set. One company is found three times.
Finding duplicates from a (database extract to) DataFrame where IDs for rows are supplied.
A very common scenario is the case where duplicate records for an entity have been entered into a database. That is, there are two or more records where a name field has slightly different spelling. For example, "A.B. Corporation" and "AB Corporation". Using the optional 'ID' parameter in the match_strings function duplicates can be found easily. A tutorial that steps though the process with an example data set is available.
For a second data set, find only the most similar match
In the example above, it's possible that multiple matches are found for a single string. Sometimes we just want a string to match with a single most similar string. If there are no similar strings found, the original string should be returned:
# Create a small set of artificial company names:
new_companies = pd.Series(['S MEDIA GROUP', '012 SMILE.COMMUNICATIONS', 'foo bar', 'B4UTRADE COM CORP'],\
name='New Company')
# Create all matches:
matches = match_most_similar(companies['Company Name'], new_companies, ignore_index=True)
# Display the results:
pd.concat([new_companies, matches], axis=1)| New Company | most_similar_Company Name | |
|---|---|---|
| 0 | S MEDIA GROUP | B.A.S. MEDIA GROUP |
| 1 | 012 SMILE.COMMUNICATIONS | 012 SMILE.COMMUNICATIONS LTD |
| 2 | foo bar | foo bar |
| 3 | B4UTRADE COM CORP | B4UTRADE COM CORP |
Deduplicate a single data set and show items with most duplicates
The group_similar_strings function groups strings that are similar using a single linkage clustering algorithm. That is, if item A and item B are similar; and item B and item C are similar; but the similarity between A and C is below the threshold; then all three items are grouped together.
# Add the grouped strings:
companies['deduplicated_name'] = group_similar_strings(companies['Company Name'],
ignore_index=True)
# Show items with most duplicates:
companies.groupby('deduplicated_name')['Line Number'].count().sort_values(ascending=False).head(10)deduplicated_name
ADVISORS DISCIPLINED TRUST 1824
AGL LIFE ASSURANCE CO SEPARATE ACCOUNT 183
ANGELLIST-ART-FUND, A SERIES OF ANGELLIST-FG-FUNDS, LLC 116
AMERICREDIT AUTOMOBILE RECEIVABLES TRUST 2001-1 87
ACE SECURITIES CORP. HOME EQUITY LOAN TRUST, SERIES 2006-HE2 57
ASSET-BACKED PASS-THROUGH CERTIFICATES SERIES 2004-W1 40
ALLSTATE LIFE GLOBAL FUNDING TRUST 2005-3 39
ALLY AUTO RECEIVABLES TRUST 2014-1 33
ANDERSON ROBERT E / 28
ADVENT INTERNATIONAL GPE VIII LIMITED PARTNERSHIP 28
Name: Line Number, dtype: int64The group_similar_strings function also works with IDs: imagine a DataFrame (customers_df) with the following content:
# Create a small set of artificial customer names:
customers_df = pd.DataFrame(
[
('BB016741P', 'Mega Enterprises Corporation'),
('CC082744L', 'Hyper Startup Incorporated'),
('AA098762D', 'Hyper Startup Inc.'),
('BB099931J', 'Hyper-Startup Inc.'),
('HH072982K', 'Hyper Hyper Inc.')
],
columns=('Customer ID', 'Customer Name')
).set_index('Customer ID')
# Display the data:
customers_df| Customer Name | |
|---|---|
| Customer ID | |
| BB016741P | Mega Enterprises Corporation |
| CC082744L | Hyper Startup Incorporated |
| AA098762D | Hyper Startup Inc. |
| BB099931J | Hyper-Startup Inc. |
| HH072982K | Hyper Hyper Inc. |
The output of group_similar_strings can be directly used as a mapping table:
# Group customers with similar names:
customers_df[["group-id", "name_deduped"]] = \
group_similar_strings(customers_df["Customer Name"])
# Display the mapping table:
customers_df| Customer Name | group-id | name_deduped | |
|---|---|---|---|
| Customer ID | |||
| BB016741P | Mega Enterprises Corporation | BB016741P | Mega Enterprises Corporation |
| CC082744L | Hyper Startup Incorporated | CC082744L | Hyper Startup Incorporated |
| AA098762D | Hyper Startup Inc. | AA098762D | Hyper Startup Inc. |
| BB099931J | Hyper-Startup Inc. | AA098762D | Hyper Startup Inc. |
| HH072982K | Hyper Hyper Inc. | HH072982K | Hyper Hyper Inc. |
Note that here customers_df initially had only one column "Customer Name" (before the group_similar_strings function call); and it acquired two more columns "group-id" (the index-column) and "name_deduped" after the call through a "setting with enlargement" (a pandas feature).
Simply compute the cosine similarities of pairs of strings
Sometimes we have pairs of strings that have already been matched but whose similarity scores need to be computed. For this purpose we provide the function compute_pairwise_similarities:
# Create a small DataFrame of pairs of strings:
pair_s = pd.DataFrame(
[
('Mega Enterprises Corporation', 'Mega Enterprises Corporation'),
('Hyper Startup Inc.', 'Hyper Startup Incorporated'),
('Hyper Startup Inc.', 'Hyper Startup Inc.'),
('Hyper Startup Inc.', 'Hyper-Startup Inc.'),
('Hyper Hyper Inc.', 'Hyper Hyper Inc.'),
('Mega Enterprises Corporation', 'Mega Enterprises Corp.')
],
columns=('left', 'right')
)
# Display the data:
pair_s| left | right | |
|---|---|---|
| 0 | Mega Enterprises Corporation | Mega Enterprises Corporation |
| 1 | Hyper Startup Inc. | Hyper Startup Incorporated |
| 2 | Hyper Startup Inc. | Hyper Startup Inc. |
| 3 | Hyper Startup Inc. | Hyper-Startup Inc. |
| 4 | Hyper Hyper Inc. | Hyper Hyper Inc. |
| 5 | Mega Enterprises Corporation | Mega Enterprises Corp. |
# Compute their cosine similarities and display them:
pair_s['similarity'] = compute_pairwise_similarities(pair_s['left'], pair_s['right'])
pair_s| left | right | similarity | |
|---|---|---|---|
| 0 | Mega Enterprises Corporation | Mega Enterprises Corporation | 1.000000 |
| 1 | Hyper Startup Inc. | Hyper Startup Incorporated | 0.633620 |
| 2 | Hyper Startup Inc. | Hyper Startup Inc. | 1.000000 |
| 3 | Hyper Startup Inc. | Hyper-Startup Inc. | 1.000000 |
| 4 | Hyper Hyper Inc. | Hyper Hyper Inc. | 1.000000 |
| 5 | Mega Enterprises Corporation | Mega Enterprises Corp. | 0.826463 |
The StringGrouper class
The four functions mentioned above all create a StringGrouper object behind the scenes and call different functions on it. The StringGrouper class keeps track of all tuples of similar strings and creates the groups out of these. Since matches are often not perfect, a common workflow is to:
- Create matches
- Manually inspect the results
- Add and remove matches where necessary
- Create groups of similar strings
The StringGrouper class allows for this without having to re-calculate the cosine similarity matrix. See below for an example.
company_names = '/media/chris/data/dev/name_matching/data/sec_edgar_company_info.csv'
companies = pd.read_csv(company_names)- Create matches
# Create a new StringGrouper
string_grouper = StringGrouper(companies['Company Name'], ignore_index=True)
# Check if the ngram function does what we expect:
string_grouper.n_grams('McDonalds')['McD', 'cDo', 'Don', 'ona', 'nal', 'ald', 'lds']# Now fit the StringGrouper - this will take a while since we are calculating cosine similarities on 600k strings
string_grouper = string_grouper.fit()# Add the grouped strings
companies['deduplicated_name'] = string_grouper.get_groups()Suppose we know that PWC HOLDING CORP and PRICEWATERHOUSECOOPERS LLP are the same company. StringGrouper will not match these since they are not similar enough.
companies[companies.deduplicated_name.str.contains('PRICEWATERHOUSECOOPERS LLP')]| Line Number | Company Name | Company CIK Key | deduplicated_name | |
|---|---|---|---|---|
| 478441 | 478442 | PRICEWATERHOUSECOOPERS LLP /TA | 1064284 | PRICEWATERHOUSECOOPERS LLP /TA |
| 478442 | 478443 | PRICEWATERHOUSECOOPERS LLP | 1186612 | PRICEWATERHOUSECOOPERS LLP /TA |
| 478443 | 478444 | PRICEWATERHOUSECOOPERS SECURITIES LLC | 1018444 | PRICEWATERHOUSECOOPERS LLP /TA |
companies[companies.deduplicated_name.str.contains('PWC')]| Line Number | Company Name | Company CIK Key | deduplicated_name | |
|---|---|---|---|---|
| 485535 | 485536 | PWC CAPITAL INC. | 1690640 | PWC CAPITAL INC. |
| 485536 | 485537 | PWC HOLDING CORP | 1456450 | PWC HOLDING CORP |
| 485537 | 485538 | PWC INVESTORS, LLC | 1480311 | PWC INVESTORS, LLC |
| 485538 | 485539 | PWC REAL ESTATE VALUE FUND I LLC | 1668928 | PWC REAL ESTATE VALUE FUND I LLC |
| 485539 | 485540 | PWC SECURITIES CORP /BD | 1023989 | PWC SECURITIES CORP /BD |
| 485540 | 485541 | PWC SECURITIES CORPORATION | 1023989 | PWC SECURITIES CORPORATION |
| 485541 | 485542 | PWCC LTD | 1172241 | PWCC LTD |
| 485542 | 485543 | PWCG BROKERAGE, INC. | 67301 | PWCG BROKERAGE, INC. |
We can add these with the add function:
string_grouper = string_grouper.add_match('PRICEWATERHOUSECOOPERS LLP', 'PWC HOLDING CORP')
companies['deduplicated_name'] = string_grouper.get_groups()
# Now lets check again:
companies[companies.deduplicated_name.str.contains('PRICEWATERHOUSECOOPERS LLP')]| Line Number | Company Name | Company CIK Key | deduplicated_name | |
|---|---|---|---|---|
| 478441 | 478442 | PRICEWATERHOUSECOOPERS LLP /TA | 1064284 | PRICEWATERHOUSECOOPERS LLP /TA |
| 478442 | 478443 | PRICEWATERHOUSECOOPERS LLP | 1186612 | PRICEWATERHOUSECOOPERS LLP /TA |
| 478443 | 478444 | PRICEWATERHOUSECOOPERS SECURITIES LLC | 1018444 | PRICEWATERHOUSECOOPERS LLP /TA |
| 485536 | 485537 | PWC HOLDING CORP | 1456450 | PRICEWATERHOUSECOOPERS LLP /TA |
This can also be used to merge two groups:
string_grouper = string_grouper.add_match('PRICEWATERHOUSECOOPERS LLP', 'ZUCKER MICHAEL')
companies['deduplicated_name'] = string_grouper.get_groups()
# Now lets check again:
companies[companies.deduplicated_name.str.contains('PRICEWATERHOUSECOOPERS LLP')]| Line Number | Company Name | Company CIK Key | deduplicated_name | |
|---|---|---|---|---|
| 478441 | 478442 | PRICEWATERHOUSECOOPERS LLP /TA | 1064284 | PRICEWATERHOUSECOOPERS LLP /TA |
| 478442 | 478443 | PRICEWATERHOUSECOOPERS LLP | 1186612 | PRICEWATERHOUSECOOPERS LLP /TA |
| 478443 | 478444 | PRICEWATERHOUSECOOPERS SECURITIES LLC | 1018444 | PRICEWATERHOUSECOOPERS LLP /TA |
| 485536 | 485537 | PWC HOLDING CORP | 1456450 | PRICEWATERHOUSECOOPERS LLP /TA |
| 662585 | 662586 | ZUCKER MICHAEL | 1629018 | PRICEWATERHOUSECOOPERS LLP /TA |
| 662604 | 662605 | ZUCKERMAN MICHAEL | 1303321 | PRICEWATERHOUSECOOPERS LLP /TA |
| 662605 | 662606 | ZUCKERMAN MICHAEL | 1496366 | PRICEWATERHOUSECOOPERS LLP /TA |
We can remove strings from groups in the same way:
string_grouper = string_grouper.remove_match('PRICEWATERHOUSECOOPERS LLP', 'ZUCKER MICHAEL')
companies['deduplicated_name'] = string_grouper.get_groups()
# Now lets check again:
companies[companies.deduplicated_name.str.contains('PRICEWATERHOUSECOOPERS LLP')]| Line Number | Company Name | Company CIK Key | deduplicated_name | |
|---|---|---|---|---|
| 478441 | 478442 | PRICEWATERHOUSECOOPERS LLP /TA | 1064284 | PRICEWATERHOUSECOOPERS LLP /TA |
| 478442 | 478443 | PRICEWATERHOUSECOOPERS LLP | 1186612 | PRICEWATERHOUSECOOPERS LLP /TA |
| 478443 | 478444 | PRICEWATERHOUSECOOPERS SECURITIES LLC | 1018444 | PRICEWATERHOUSECOOPERS LLP /TA |
| 485536 | 485537 | PWC HOLDING CORP | 1456450 | PRICEWATERHOUSECOOPERS LLP /TA |
Performance
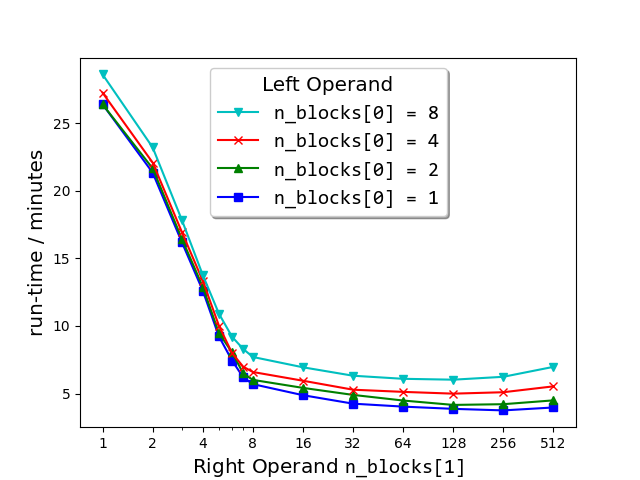
Semilogx plots of run-times of match_strings() vs the number of blocks (n_blocks[1]) into which the right matrix-operand of the dataset (663 000 strings from sec__edgar_company_info.csv) was split before performing the string comparison. As shown in the legend, each plot corresponds to the number n_blocks[0] of blocks into which the left matrix-operand was split.
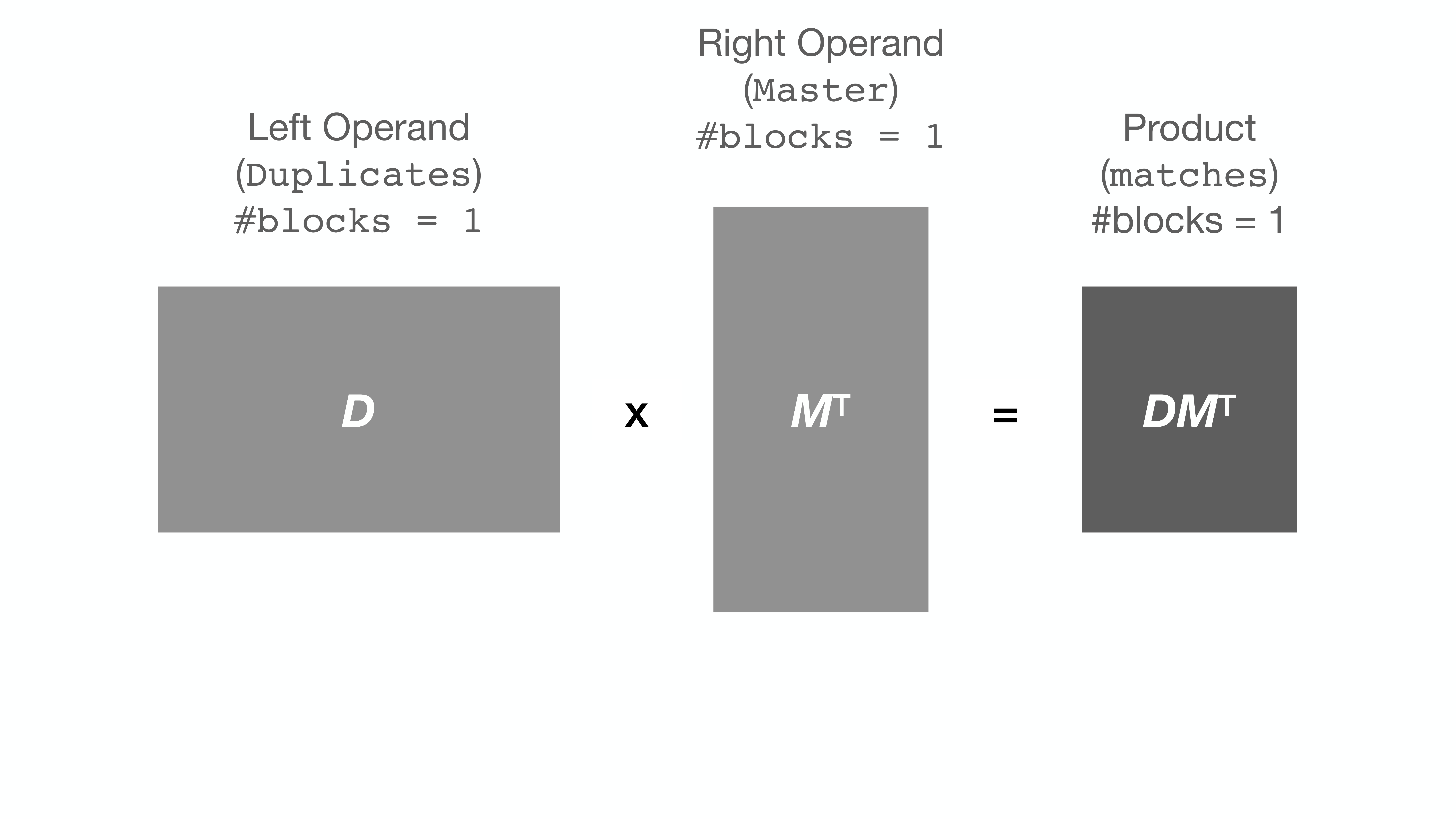
String comparison, as implemented by string_grouper, is essentially matrix
multiplication. A pandas Series of strings is converted (tokenized) into a
matrix. Then that matrix is multiplied by itself (or another) transposed.
Here is an illustration of multiplication of two matrices D and MT:
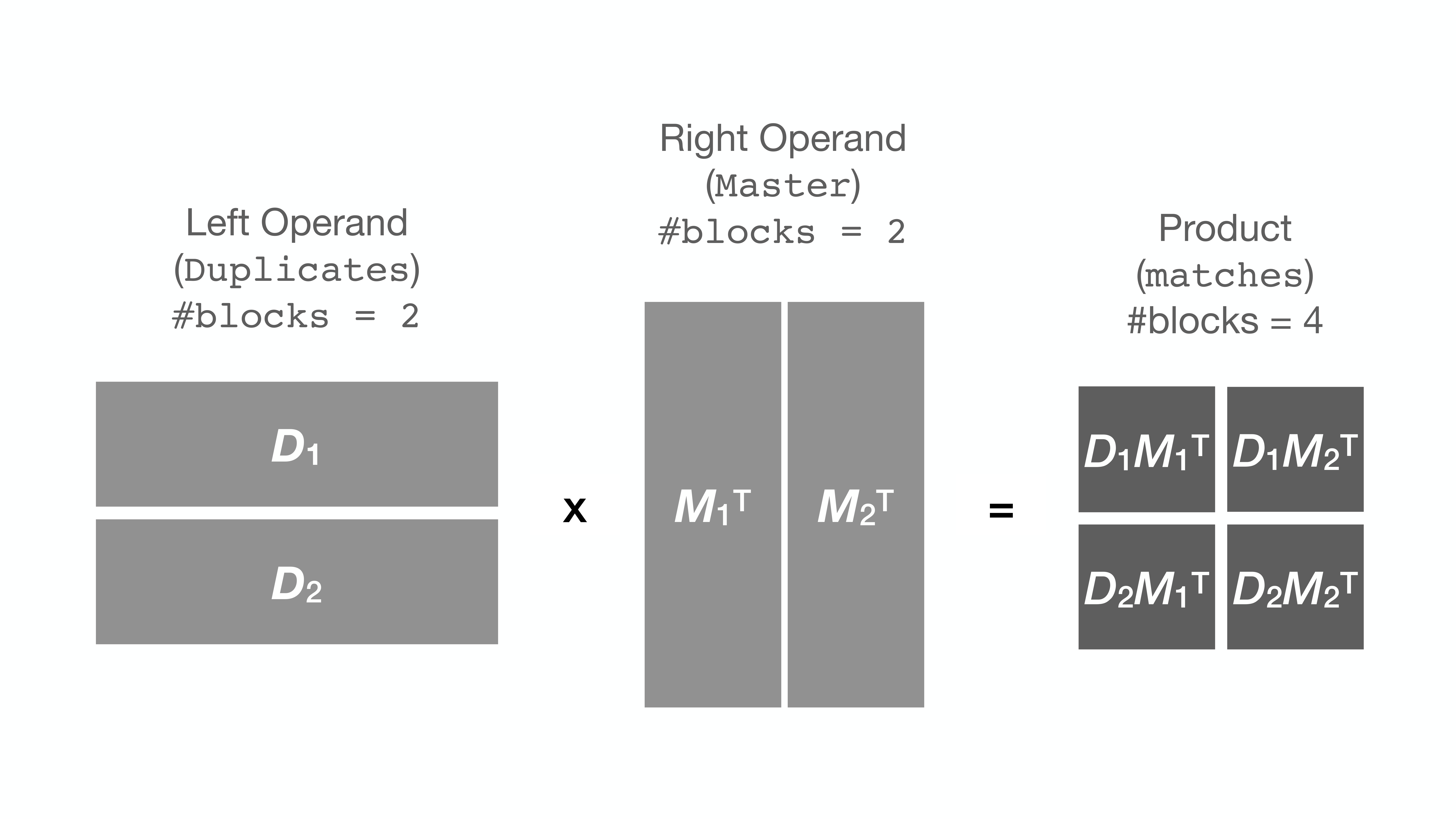
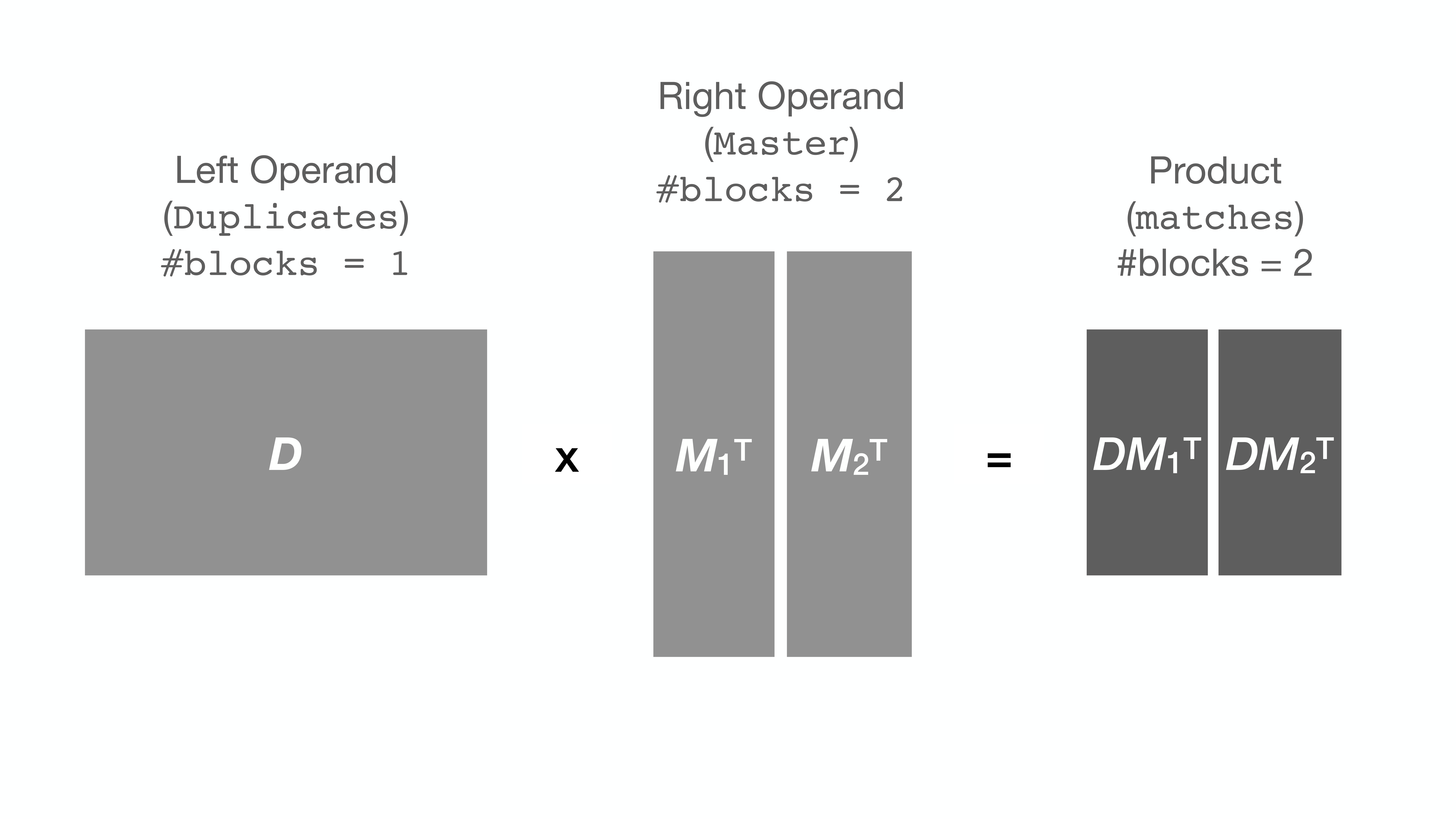
It turns out that when the matrix (or Series) is very large, the computer
proceeds quite slowly with the multiplication (apparently due to the RAM being
too full). Some computers give up with an OverflowError.
To circumvent this issue, string_grouper now allows the division of the Series
into smaller chunks (or blocks) and multiplies the chunks one pair at a time
instead to get the same result:
But surprise ... the run-time of the process is sometimes drastically reduced
as a result. For example, the speed-up of the following call is about 500%
(here, the Series is divided into 200 blocks on the right operand, that is,
1 block on the left × 200 on the right) compared to the same call with no
splitting [n_blocks=(1, 1), the default, which is what previous versions
(0.5.0 and earlier) of string_grouper did]:
# A DataFrame of 668 000 records:
companies = pd.read_csv('data/sec__edgar_company_info.csv')
# The following call is more than 6 times faster than earlier versions of
# match_strings() (that is, when n_blocks=(1, 1))!
match_strings(companies['Company Name')], n_blocks=(1, 200))Further exploration of the block number space (see plot above) has revealed that for any fixed number of right blocks, the run-time gets longer the larger the number of left blocks specified. For this reason, it is recommended not to split the left matrix.
In general,
total runtime = n_blocks[0] × n_blocks[1] × mean runtime per block-pair
= Left Operand Size × Right Operand Size ×
mean runtime per block-pair / (Left Block Size × Right Block Size)
So for given left and right operands, minimizing the total runtime is the same as minimizing the
runtime per string-pair comparison ≝
mean runtime per block-pair / (Left Block Size × Right Block Size)
Below is a log-log-log contour plot of the runtime per string-pair comparison scaled by its value at Left Block Size = Right Block Size = 5000. Here, Block Size is the number of strings in that block, and mean runtime per block-pair is the time taken for the following call to run:
# note the parameter order!
match_strings(right_Series, left_Series, n_blocks=(1, 1))where left_Series and right_Series, corresponding to Left Block and Right Block respectively, are random subsets of the Series companies['Company Name')] from the
sec__edgar_company_info.csv sample data file.
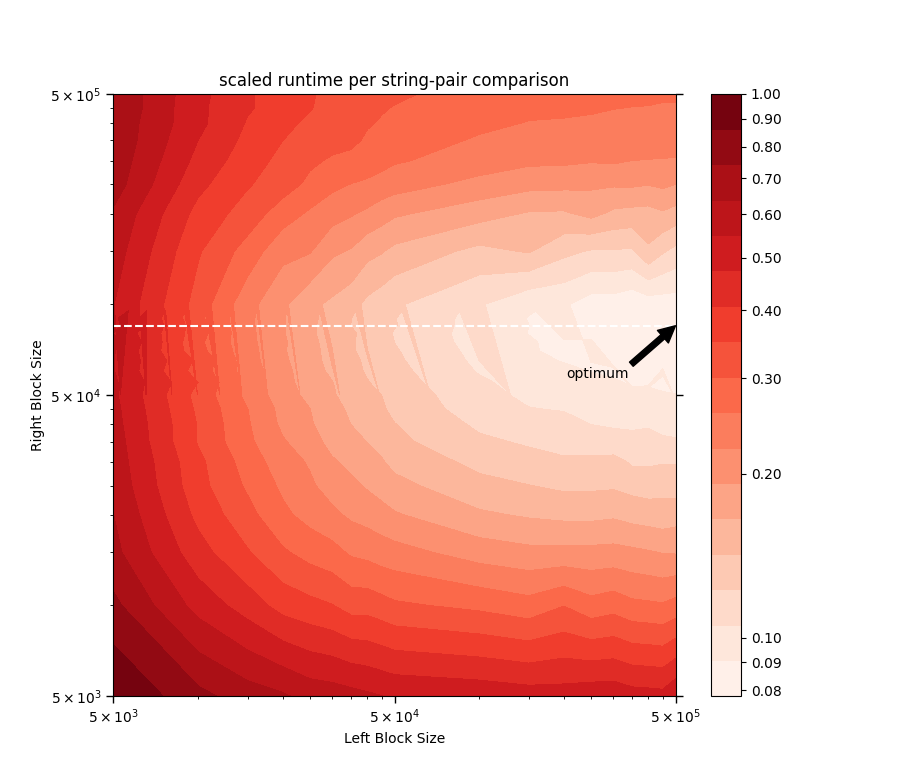
It can be seen that when right_Series is roughly the size of 80 000 (denoted by the
white dashed line in the contour plot above), the runtime per string-pair comparison is at
its lowest for any fixed left_Series size. Above Right Block Size = 80 000, the
matrix-multiplication routine begins to feel the limits of the computer's
available memory space and thus its performance deteriorates, as evidenced by the increase
in runtime per string-pair comparison there (above the white dashed line). This knowledge
could serve as a guide for estimating the optimum block numbers —
namely those that divide the Series into blocks of size roughly equal to
80 000 for the right operand (or right_Series).
So what are the optimum block number values for any given Series? That is anyone's guess, and may likely depend on the data itself. Furthermore, as hinted above, the answer may vary from computer to computer.
We however encourage the user to make judicious use of the n_blocks
parameter to boost performance of string_grouper whenever possible.