 Kuifje02
commented
4 years ago
Kuifje02
commented
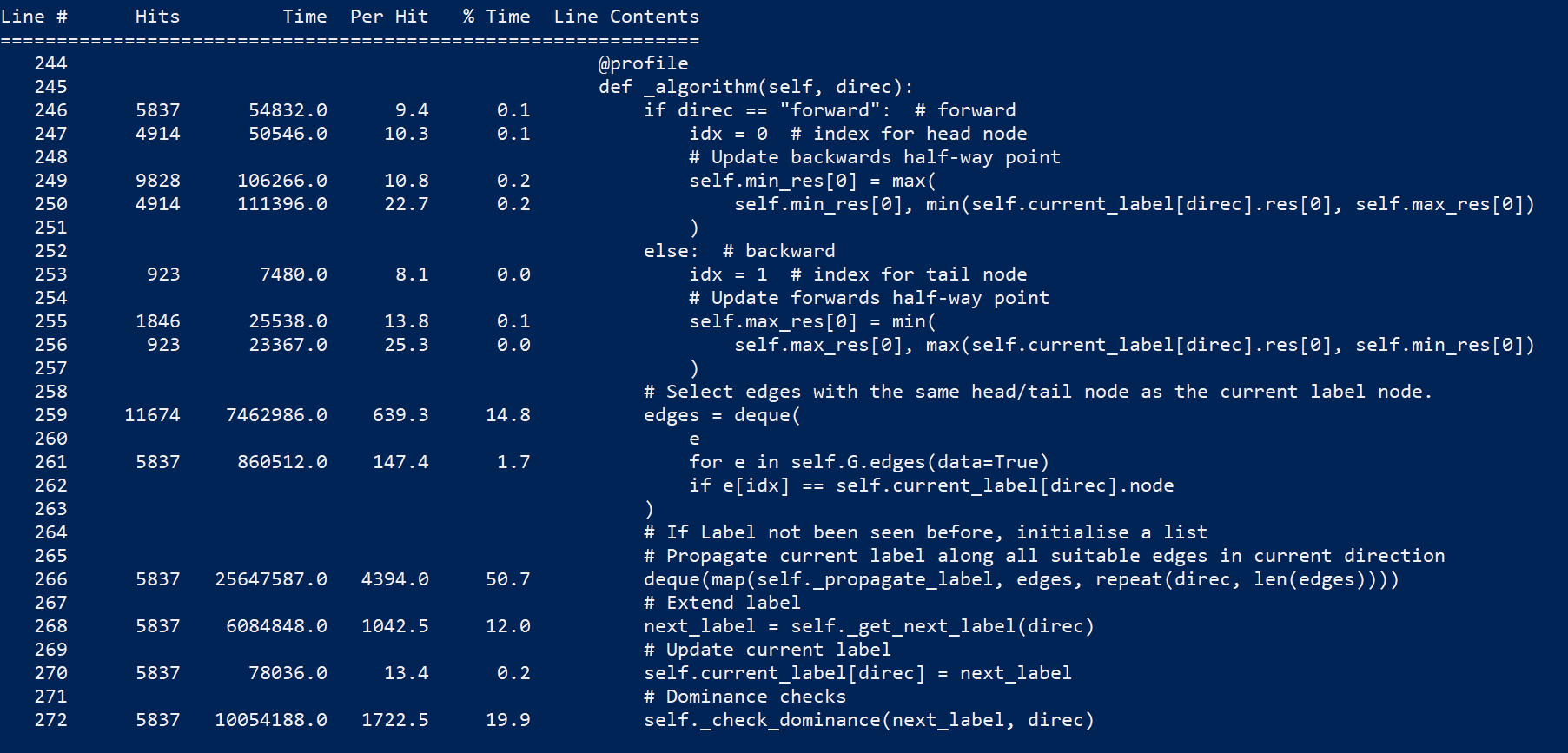
4 years ago Some profiling with line_profiler (cspy.BiDirectional) :
~77% of the time is consumed by self._algorithm(direct)
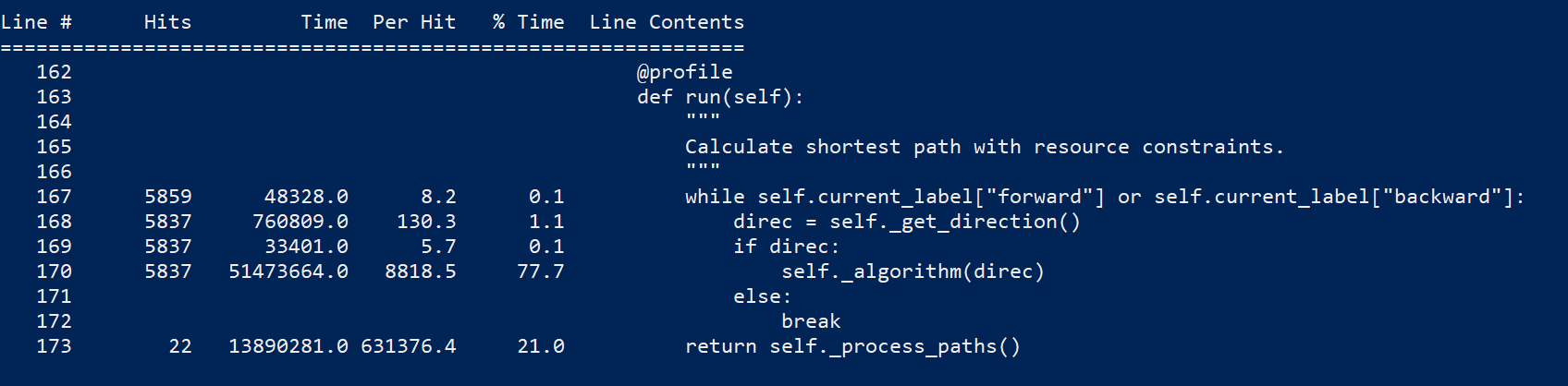
~50% consumed by deque(map(self._propagate_label, edges, repeat(direc, len(edges))))
~20% consumed by self._check_dominance(next_label, direc)
 torressa
torressa



Not really an issue, just a place to keep track of our ideas to speed up execution of the code.