 xsacha
commented
7 years ago
xsacha
commented
7 years ago Assuming the code isn't multi-threaded (I think it uses CBLAS by default which only uses one core?), a 1.6GHz Cortex-A15 armv7 and the 1.2GHz cortex-a57 armv8 ('cyclone') could have massively different performance.
Probably not as much as you see there, but enough to make up for the clock speed for sure: http://images.anandtech.com/doci/7995/Screen%20Shot%202014-05-06%20at%202.59.56%20AM.png
 davisking
davisking waterball2016
waterball2016 waterball
waterball ZipperDeng
ZipperDeng e-fominov
e-fominov jgoenetxea
jgoenetxea annerajb
annerajb dlib-issue-bot
dlib-issue-bot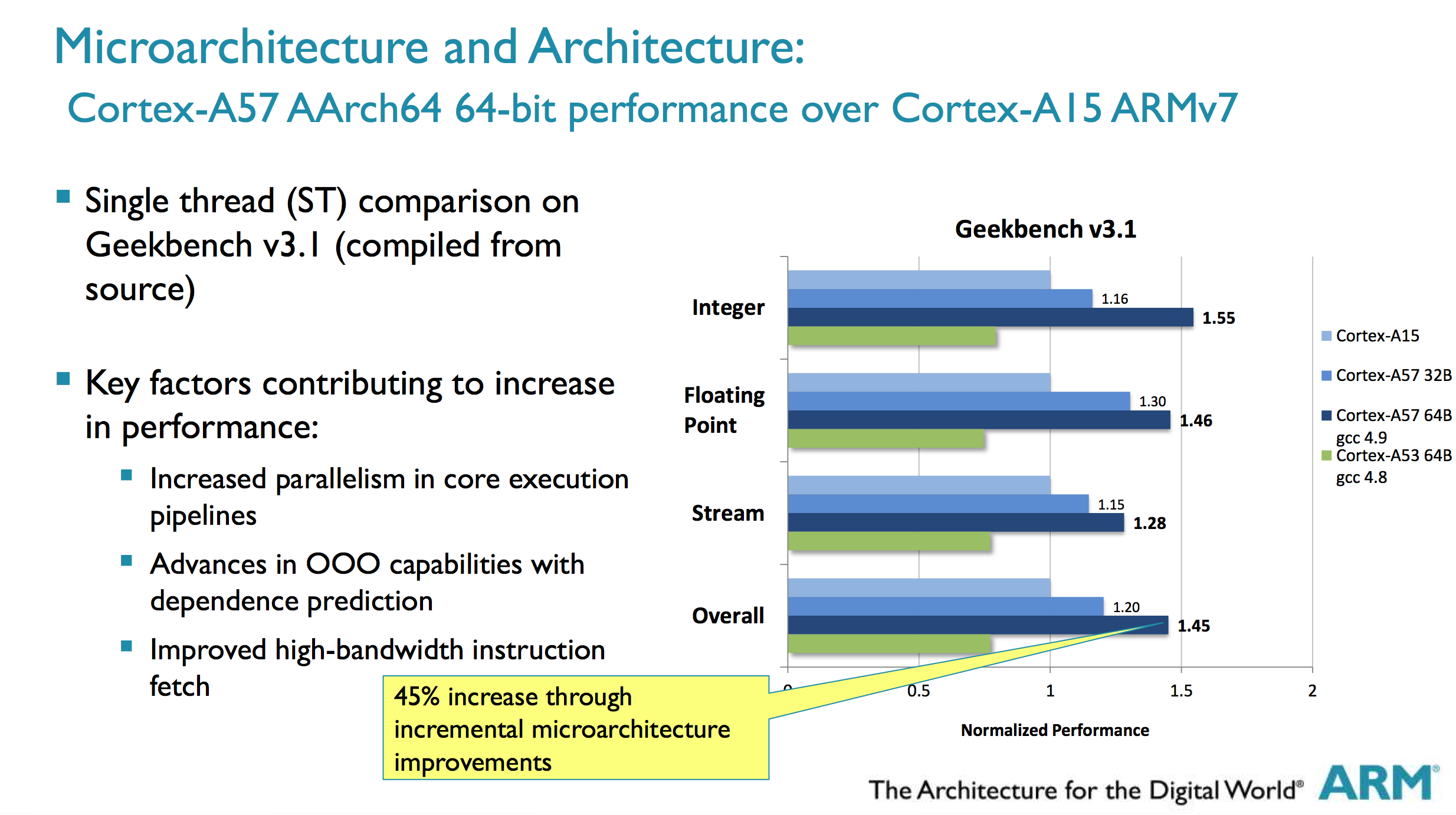{kind=link}
I tried the same piece of code on both Android and iOS. I got the following results:
This is a pretty odd results. The efficiency of iOS is almost five times of that of Android. By the way, for both OS I enable NEON optimization and shorten the pyramid of scanner from 6 to 3.