ppwwyyxx
commented
4 years ago
ppwwyyxx
commented
4 years ago It's unlikely we'll add to existing models large features that are specifically tailored to properties of certain datasets. Such features are expected to be implemented separately as new modules in users' code, or potentially in detectron2/projects if they appear more popular and widely useful.
If there are any good utilities (e.g., IOU vs IOA) or more general improvements that can simplify the above process or are part of the abovementioned feature, they can be discussed separately as individual feature requests.
 Trouble404
Trouble404
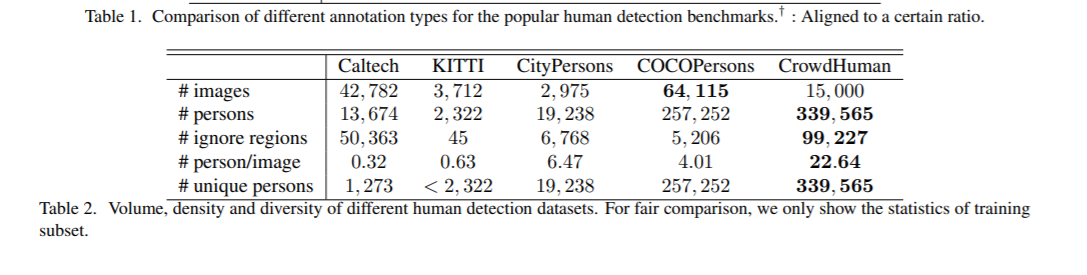
some datasets like CrowdHuman contains 'ignore regions' bounding boxes annotation, there are 100k ignore bounding boxes in CrowdHuman, when we train a detector based on this dataset, we may want to reduce the effect from human doll, human billboard or dense crowd human. these part of regions should not consider as positive and negative supervise, bug I notice Detectron2 don't have a feature to process 'ignore' annotation during dataloader and matcher, this feature cound be used for lots of projects which need ignore labels