 hollobit
commented
3 years ago
hollobit
commented
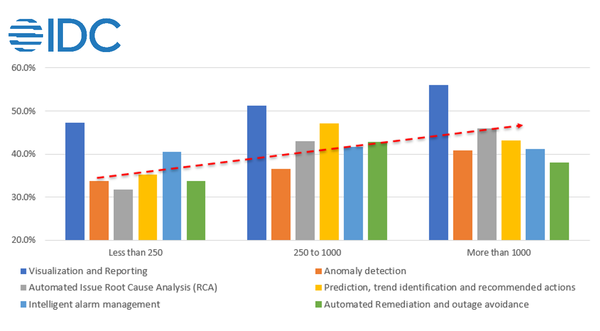
3 years ago “AI옵스(AIOps)가 대세”…IDC, 2023년 기업 75%, AIOps 채택 전망
Facebook Apologizes After A.I. Puts ‘Primates’ Label on Video of Black Men
Only Humans, Not AI Machines, Get a U.S. Patent, Judge Says
- https://www.bloomberg.com/news/articles/2021-09-03/only-humans-not-ai-machines-can-get-a-u-s-patent-judge-rules Federal judge says AI can’t be listed as inventor on patents Case is first U.S. ruling in global dispute over AI inventions
The term AI overpromises. Let's make machine learning work better for humans instead
How open-source software shapes AI policy
- https://www.brookings.edu/research/how-open-source-software-shapes-ai-policy/
- OSS SPEEDS AI ADOPTION
- OSS HELPS REDUCE AI BIAS
- OSS AI TOOLS ADVANCE SCIENCE
- OSS AI HELPS AND HINDERS TECHNOLOGY SECTOR COMPETITION
- OSS CREATES DEFAULT AI STANDARDS
AI Weekly: An outline for government regulation of AI
- https://venturebeat.com/2021/09/03/ai-weekly-an-outline-for-government-regulation-of-ai/ WHY AND HOW GOVERNMENTS SHOULD MONITOR AI DEVELOPMENT - https://arxiv.org/pdf/2108.12427.pdf
Sanas aims to convert one accent to another in real time for smoother customer service calls
Understanding, explaining, and utilizing medical artificial intelligence (Nature Human Behaviour)
AIMe – A standard for artificial intelligence in biomedicine
Maastricht University (UM)를 비롯한 여러 대학의 국제 연구에서 생물 의학 분야의 인공 지능(AI) 작업에 대한 표준화된 레지스트리를 제안
 ghlee3401
ghlee3401.PNG?raw=true)
 Kyung-Min
Kyung-Min

News
ArXiv
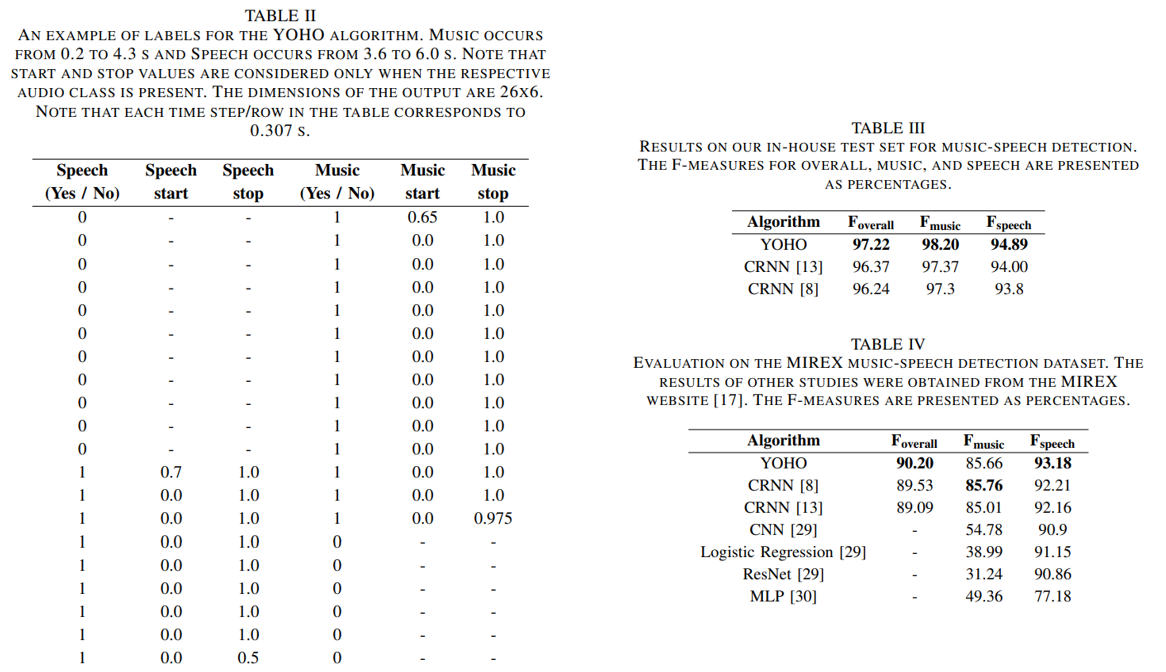
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
이미지-텍스트 멀디모달 러닝 (from Google Brain, UW)
이미지 패치 + 텍스트 토큰 (prefix) --> output: Autoregressive seq2seq
Conv (Res101/152의 stem빼고 첫 3블럭) + ViT 구조를 image encoder에 활용
ALIGN에 사용했던 1.8B noisy dataset 활용, Text only: C4 800GB
Downstream: VQA v2, SNLI-VE (entailment), NLVR2 (reasoning), COCO-caption, etc.


SHIFT15M: Multiobjective Large-Scale Fashion Dataset with Distributional Shifts
15M개의 fashion images from 일본 Zozo (패션 e-commerce: IQON- 야후재팬) Research
훈련/테스트 데이터 분포 차이에 중점을 둔 데이터셋이지만 (2013 ~ 2020)
태스크는 좋아요, 가격합, 상품가격 regression, 카테고리 분류, set2set 매칭 등
초대량의 패션데이터, Multi object, 여러 분포상 변화, 다양한 메타데이터 (사용자 id, set id, 좋아요 숫자) 등으로 꽤 유용해 보일 듯
https://github.com/st-tech/zozo-shift15m
A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP
Conv, Transformer, MLP를 동일한 framework 구성에서 비교 평가 (SPACH 제안) (from MSRA)
Single stage / Multi stage (downsample), Mixing block을 각 컴포넌트로 구현
Data aug는 DeiT 세팅을 따름.
결론은 Conv+Transformer 하이브리다가 젤 낫더라? (ImageNet-1k에서 일관성있는...)
파라미터크기, FLOP, throughput 관점에서 비교해보기 좋아 보임.

ASR-GLUE: A New Multi-task Benchmark for ASR-Robust Natural Language Understanding
음성인식 환경에서의 안정적인 NLU 벤치마크 (from Tencent AI) --> 스피커, 음성인식 분야의 중요한 이슈
ASR error가 포함된 GLUE task
https://drive.google.com/drive/folders/1slqI6pUiab470vCxQBZemQZN-a_ssv1Q

Whole Brain Vessel Graphs: A Dataset and Benchmark for Graph Learning and Neuroscience (VesselGraph)
전체 3d 뇌 혈관 그래프 데이터 (그래프 러닝용) (from TUM, Helmhotz, U of Zurich)
뇌연구 혹은 graph representation learning 하시는 연구자분들께
https://github.com/jocpae/VesselGraph
Self-training Improves Pre-training for Few-shot Learning in Task-oriented Dialog Systems
Task-oriented dialog pretraining 에 Noisy student 스타일의 self-training 적용 (from Huawei, EMNLP 2021)
pseudo-labeling 기반의 semi-super + regularization by GradAug (data aug) --> label 정보를 반영하여 semantic 해치지 않는 aug 기법
ToD 4가지 downstream task 에서 BERT, ToD-BERT를 활용해서 few-shot 세팅으로 성능 측정

AMMUS : A Survey of Transformer-based Pretrained Models in Natural Language Processing
Transformer 기반의 Pretrained LM 관련 연구들을 다양한 기준으로 정리한 논문
입문하시는 분들 / 강의 하시는 분들께 유용할 듯
https://mr-nlp.github.io/posts/2021/05/tptlms-list/