 OrkoHunter
commented
5 years ago
OrkoHunter
commented
5 years ago https://medium.com/kharagpur-open-source-society/breaking-github-down-fa981e6286e7
# Breaking GitHub Down
During my mid semester exams, one night I was getting bored so I decided to
check how to break the most used code hosting website
[GitHub](https://github.com/). I wrote a
script[[1]](https://github.com/DefCon-007/Commiter-source) to add infinite
commits to a repository named
“Commiter”[[2]](https://github.com/DefCon-007/Commiter). It added a dot at the
end of a text file after every commit. The script pushed to the master branch
after every 10,000 commits and then after 1,00,000 commits it deleted the
repository and then cloned it back with just the last commit. I had to do it
because after a large number of commits the directory size was quite
large(approx 7–9 GBs).
With the help of this script I was able to find three bugs on GitHub after which
they blocked my repository[[2]](https://github.com/DefCon-007/Commiter) .
1. **Z-index for commit label of contribution graph was not proper** :
Below is the screenshot of the issue I am talking about.

<span class="figcaption_hack">Issue #1</span>
The label for the commit number should be above the graph. I got the following
response for this issue.
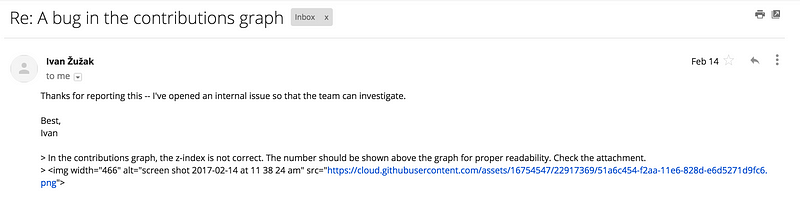
<span class="figcaption_hack">Reply for issue #3</span>
**2. Latest commit info was not loading :**
After some days the I noticed that the GitHub was failing to load the latest
commit information on the repository homepage.

<span class="figcaption_hack">Issue #2</span>
And for this issue I got the following reply.
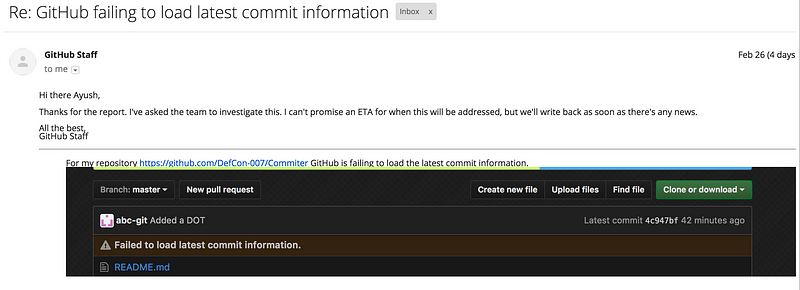
<span class="figcaption_hack">Reply for issue #2</span>
**3. Contributions graph failing to load :**
According to me this was a major bug. The contributions graph stopped loading.
It showed the below screen for hours and then the page said “Failed to load
contributions graph”.
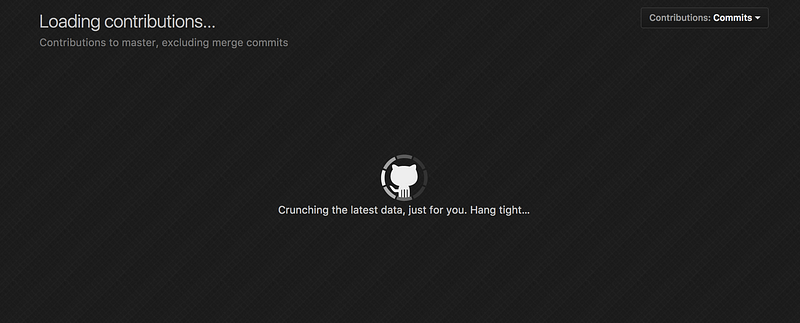
<span class="figcaption_hack">Issue #3</span>
Sadly this was the last issue I was able to track. After reporting this people
at GitHub disabled access to my repository. The reason stated by them was :
> The repository you’re inquiring about, DefCon-007/Commiter, has been deemed
> abusive to our system and we have disabled it.
> Large numbers of commits do not lend themselves well to versioning with Git and
> performance issues with a repository of this size can endanger the availability
of your repo as well as other user’s repositories. Additionally, the pattern of
your commits is very different than that which Git was meant to handle, and
therefore consumes far more resources than a normal Git repository of its size.
And at the end they clearly mentioned that the repository access will not
enabled again.
P.S. : I was able to reach around 6,567,567 commits.
So this was my story how I used my mid semester exam frustration to do some
mischief with GitHub.
References :
[1]
[https://github.com/DefCon-007/Commiter-source](https://github.com/DefCon-007/Commiter-source)
[2][https://github.com/DefCon-007/Commiter](https://github.com/DefCon-007/Commiter)
* [Github](https://medium.com/tag/github?source=post)
* [Git](https://medium.com/tag/git?source=post)
### [Ayush Goyal](https://medium.com/@DefCon_007)
Open Source Enthusiast | GSoC’17 at OpenMRS
I am on it.