 innobead
commented
3 years ago
innobead
commented
3 years ago Hey team! Please add your planning poker estimate with ZenHub @jenting @joshimoo @PhanLe1010 @shuo-wu
Open yasker opened 3 years ago
innobead
commented
3 years ago Hey team! Please add your planning poker estimate with ZenHub @jenting @joshimoo @PhanLe1010 @shuo-wu
innobead
commented
3 years ago cc @keithalucas @derekbit
 derekbit
commented
3 years ago
derekbit
commented
3 years ago Rough design note
a LRU cache
IO path
handleRead
-> s.data.ReadAt
-> foreach block
-> cache.ReadAt(offset)
-> hit, read data from cache
-> miss, read data from replica (generic read path)
-> cache.Update
-> merge and truncate block data to the request size
-> return datahandleWrite
-> s.data.WritedAt
-> cache.Invalidate(offset, size)
-> generic write pathTBD
 keithalucas
commented
2 years ago
keithalucas
commented
2 years ago Rough design note
- a LRU cache
It seems like we want to have this cache in the longhorn-engine controller process not the replica, correct? @yasker did some analysis of other storage solutions and found that they do caching. It might be useful to look at several them to see if they use LRU caching or one of the other caching approaches.
We should investigate implementing the cache with lock free algorithm because the cache will be accessed by multiple goroutines constantly.
- configurable cache size
I think we will need to determine a default cache size eventually.
key: offset, value: block
- IO path
read
handleRead -> s.data.ReadAt -> foreach block -> cache.ReadAt(offset) -> hit, read data from cache -> miss, read data from replica (generic read path) -> cache.Update
The longhorn-engine controller doesn't have a fixed block size; it can handle ReadAt and WriteAts with any offset and length. The longhorn-engine controller currently requests the same offset and length from the longhorn-engine replica that it receives from tgtd. One of the bottlenecks in the longhorn-engine is the communication between the longhorn-engine controller and the longhorn-engine replicas.
I don't think it should have break up that ReadAt received by the longhorn-engine controller into multiple ReadAt messages with the cache block size to be sent to the longhorn-engine replica; we should find which intervals in the request are not covered by the cache (i.e. the biggest offset length pairs that aren't covered by the cache). For example, if our cache block size is 100, and the controller receives a ReadAt at offset 0 and length of 1000. If offset 100 is in the cache, we should send the replica ReadAt(0, 100) and ReadAt(200, 800) not ReadAt(0, 100), ReadAt(200, 100), ReadAt(300, 100), ReadAt(400, 100), etc.
With the current design, there are a maximum of sixteen goroutines for handling ReadAt or WriteAt operations in the longhorn-engine controller. The controller makes a new goroutine for each message received from tgtd, and tgtd has sixteen threads. When a ReadAts received by the controller is broken up into multiple ReadAts to be sent to the replica, I'm not sure if we should use goroutines to send the individual ReadAts to the replica simultaneously or not use goroutine and send them sequentially. Depending on the how much ReadAts are broken up, if they are sent simultaneously, it could result in a replica handling many more simultaneous operations being handled by a replica.
I think it does make sense to have the longhorn-engine controller have a fixed block size if we are going to add read side caching. I feel like it may make sense to have the block size that is used for the cache to be big, maybe 4MiB to 16MiB. I don't think we should make this configurable. This will result in reading more than the ReadAt requests. Hopefully this could almost predict the next ReadAts; if data is being read sequentially, we may have the data for the next read operation in the cache already. However, in this scenario, the multiple requests being processes at the same time may result in the same expanded ReadAt being sent to the replica. For example, if the controller receives a ReadAt(0, 100) and a ReadAt(100, 100), if our block size was 1000, we could generated a ReadAt(0, 1000) for the replica for both of those operations. Somehow we should have a mechanism to not send duplicate requests to the replica and have the second request use the result of the expanded ReadAt. If we have to break up a ReadAt operation, a bigger block size in the cache will minimize how much we have to break it up.
-> merge and truncate block data to the request size -> return data ```
- write
handleWrite -> s.data.WritedAt -> cache.Invalidate(offset, size)
Should put the WriteAt in the cache if we have enough to fill a block in the cache?
-> generic write path ```
TBD
- cache drop, need or not?
In generally, I think this is a good idea. I think we need to have tests to demonstrate the amount of improvement this causes. https://github.com/yasker/kbench was used to compare the performance between longhorn and other storage solutions.
derekbit
commented
2 years ago It seems like we want to have this cache in the longhorn-engine controller process not the replica, correct?
@keithalucas If the node where the app pod resides has a replica, should it need a read side cache? Seems there is no any benefit in this case.
derekbit
commented
2 years ago After investigation the cache design in the open source storage projects, I found we need to pay lots of effort if we'd like to implement a read side cache logic in the longhorn-engine controller side. Thus, I plan to introduce the dm-cache as our cache solution.
To achieve the read side cache, the steps are:
dm-cache supports writeback, writethrough and passthrough modes now, so the writethrought mode is suitable for our read side cache. I'm implementing the PoC and will update the preliminary performance results.
@joshimoo @keithalucas Do you have any suggestions and something I need to pay attention to?
 yasker
commented
2 years ago
yasker
commented
2 years ago @derekbit is it ok to lose the device for dm-cache? The engine is designed to be stateless so losing the engine should result in no data loss.
innobead
commented
2 years ago We need to have an LEP for future reference as well.
derekbit
commented
2 years ago @yasker
Yes. I will use the writethrough mode, so the cache device is dedicated for the read cache. Each write is simultaneously updated to the cache device and replicas. Thus, losing the device is okay.
@innobead No prob. After having the preliminary results, I'll draft the overall design.
derekbit
commented
2 years ago Here are my setup and preliminary results.
Environment
Volume setting
Cache setting
Fio test Refer to the test steps in https://lkml.org/lkml/2013/6/11/333
Warm up Read the data into cache.
fio --direct=1 --size=90% --filesize=20G --blocksize=4K --ioengine=libaio --rw=rw --rwmixread=100 --rwmixwrite=0 --iodepth=64 --filename=/data/file --name=WarmUp --output=/tmp/warm-up.txtMeasure
fio --direct=1 --size=100% --filesize=20G --blocksize=4K --ioengine=libaio --rw=randrw --rwmixread=90 --rwmixwrite=10 --iodepth=64 --numjob=4 --group_reporting --filename=/data/file --name=Measure --random_distribution=zipf:1.2 --output=/tmp/fio-result.txtResult

cc. @yasker @joshimoo @keithalucas
yasker
commented
2 years ago 25G from memory is really big. We need to design a way to make it usable to the end user.
Also, does the result from kbench change? By design, it shouldn't. But we can add more benchmarks to it with the cache considered.
As you mentioned, we need to figure out what happened with the write. That's a bit of surprise there.
derekbit
commented
2 years ago @yasker
25G from memory is really big. We need to design a way to make it usable to the end user.
25G is not from the memory. It's a file on engine node's filesystem and mounted as a loop device. The cache design mainly aims to leverage the host's filesystem as our cache. There are usually many engine processes in one node, so using the memories as cache devices is a bit of infeasible. But if the user has a big memory pool, using the memory as a cache device is also an option in the future.
In this test, the advantages of the cache
does the result from kbench change?
No. Because the cache test needs a warm up phase and is different from the kbench test, I didn't use the kbench to test the performance. I also plan to add the cache test part in kbench.
derekbit
commented
2 years ago LEP is proposed. https://github.com/longhorn/longhorn/pull/3448
derekbit
commented
2 years ago Did a benchmark comparing the 100% rand read/write performance using ramdisk/SSD as a cache device.
The randwrite results were different from previous tests (randread:randwrite = 90:10), which might have been affected by read operations.
#!/bin/bashsource_device="/data/file" fio_blocksize="4K" file_size="10G" iodepth="16" numjob="4" output_path="fio-result" hit="90" loops=3
for ((i=0; i<${loops}; i++)); do
fio --direct=1 --size=${hit}% --filesize=${file_size} --blocksize=${fio_blocksize} --ioengine=libaio --rw=rw --rwmixread=100 --rwmixwrite=0 --iodepth=${iodepth} --filename=${source_device} --name=${hit}_Hit_${fio_blocksize}_WarmUp --output-format=json --output=/tmp/WarmUp.${i}.txt
# Run test
fio --direct=1 --size=100% --filesize=${file_size} --blocksize=${fio_blocksize} --ioengine=libaio --rw=randrw --rwmixread=100 --rwmixwrite=0 --iodepth=${iodepth} --numjob=${numjob} --group_reporting --filename=${source_device} --name=${hit}_Hit_${fio_blocksize} --random_distribution=zipf:1.2 --output-format=json --output=/tmp/${output_path}.${i}.txt
rm -rf ${source_device}done
- Randwrite (bs=4K, iodepth=16, numjobs=4)
Set --rwmixread=0 and --rwmixwrite=100
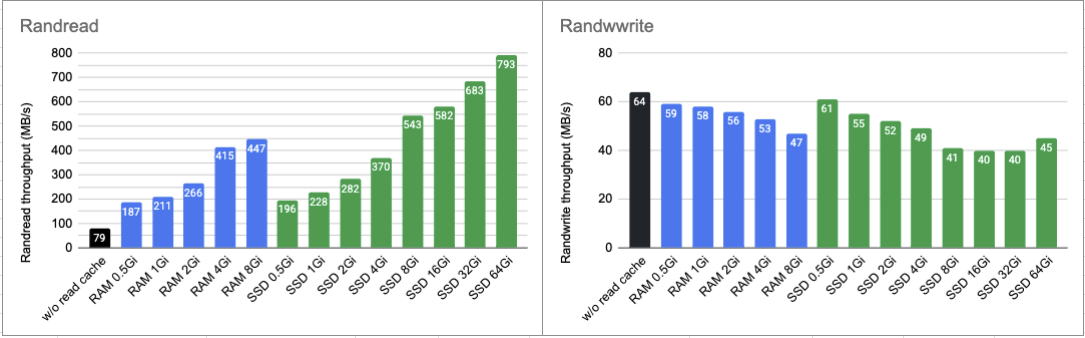
Then, check whether the sequential write performance degrades using bs=1M, iodepth=16, numjobs=1
<img src="https://user-images.githubusercontent.com/12527233/147929176-a9526f62-41c3-46a1-a740-911b13a192de.png" width="300">
#### Summary
- Randread performs as expected.
- Larger cache device enhances the randread performance because of the avoidance of the demotion/promotion operations.
- Randwrite performance degrades.
- Both the cache device and the iSCSI block device are updated in `writethrough` mode.
- Another possible factor is the demotion/promotion operations of dm-cache.
- Seqwrite performance does not degrade because dm-cache detects the sequential write and does not write data to the cache device. liyimeng
commented
2 years ago
liyimeng
commented
2 years ago @derekbit it is sat that write get negative impacted. READ normally not an issue for longhorn, write is the real problem in my use cases for longhorn.
derekbit
commented
2 years ago @liyimeng Thanks for your feedback. This is a preliminary investigation/study internally. The read-side cache targets some cases/scenarios such as low storage/network bandwidth or multiple applications contentions for storage resources. But as you mentioned, the Longhorn's write performance is not outstanding enough.
innobead
commented
2 years ago Moving back to the backlog, and will revisit in the future.
We can implement a read side caching in the engine, to increase the read performance and lower the latency if the data was cached.