 github-actions[bot]
commented
3 years ago
github-actions[bot]
commented
3 years ago 《深度剖析CPython解释器》33. 为什么 obj == obj 为 False、[obj] == [obj] 为 True - 古明地盆 - 博客园
《深度剖析CPython解释器》33. 为什么 obj == obj 为 False、[obj] == [obj] 为 True
楔子
今天同事在用 pandas 做数据处理的时候,不小心被 nan 坑了一下,他当时被坑的原因类似下面:
import numpy as np
print(np.nan == np.nan) # False
print([np.nan] == [np.nan]) # True为了严谨,我们再举个栗子:
class A:
def __eq__(self, other):
return False
a1 = A()
a2 = A()
print(a1 == a1, a2 == a2) # False False
print([a1, a2] == [a1, a2]) # True为什么会出现这个结果呢?我们知道两个列表(元组也是同理)如果相等,那么首先列表里面的元素个数要相同、并且相同索引对应的元素也要相等。但问题是这里的 a1 不等于 a1、a2 也不等于 a2,那为啥 [a1, a2] 和 [a1, a2] 就相等了呢?
其实原因很好想,那就是 Python 解释器在比较两个列表中的元素的时候,会先比较它们的引用的对象的地址是否相等,也就是看它们是否引用了同一个对象,如果是同一个对象,那么直接得到 True,然后比较下一个,如果不是同一个对象,那么再比较对应的值是否相同。所以这里 a1 == a1 明明返回 False,但是放在列表中就变成了 True,原因就在于它们引用的是同一个对象。
那么下面就来从解释器源代码的角度来验证这一结论(版本为 3.9.0),其实后续涉及到的内容在之前就已经说过了,只不过因为比较简单就一笔带过了,所以这次就针对这个例子专门分析一下。
Python 的列表之间是如何比较的
要想知道底层是如何比较的,那么最好的办法就是先看一下字节码。
import dis
code = "[] == []"
dis.dis(compile(code, "<file>", "exec"))
"""
1 0 BUILD_LIST 0
2 BUILD_LIST 0
4 COMPARE_OP 2 (==)
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
"""第一列:表示源代码的行号,我们这里只有一行代码。
第二列:表示指令的偏移量,每一条指令都占两个字节,第一个字节存放指令序列本身,第二个字节存放指令所需要的参数。所以指令从上到下的偏移量是 0 2 4 6 8 ......。
第三列:表示指令序列,在 C 中就是一个宏,会被替换为一个整数。Python 底层总共定义 120 多个指令序列,可以在 Include/opcode.h 头文件中查看。
第四列:表示指令参数。
所以开头的两个 BUILD_LIST 表示构建列表,后面的指令参数表示元素个数,因为是空列表,所以为 0。两个列表构建完毕显然就要进行比较了,因此指令序列是 COMPARE_OP,而后面的指令参数是 2,代表啥含义呢?

COMPARE_OP 表示比较,但是比较也分为:小于、小于等于、等于、不等于、大于、大于等于,那么到底是哪一种呢?显然要通过指零参数给出,而这里指定的是等于,所以指令参数是 2。至于指令参数后面的 (==) 则是 dis 模块帮你添加的,告诉你该指令参数的含义,方便理解。
因此我们的关注点就在 COMPARE_OP 这条指令序列对应的实现当中,而 Python 底层的指令序列对应的实现都位于 Python/ceval.c 中,在里面有一个 _PyEval_EvalFrameDefault 函数,以栈帧(PyFrameObject)为单位。该函数里面有一个无限的 for 循环,会不断地循环取出字节码中每一条指令序列和指令参数进行执行,直到将该栈帧内部的字节码全部执行完毕,然后退出循环。因此执行逻辑也是在这个 for 循环里面的,没错,for 循环里面有一个巨型的 switch,每一个指令序列都对应一个 case 语句,所以这个 switch 里面有 120 多个 case 语句,然后不同的指令序列走不同的 case,因此 _PyEval_EvalFrameDefault 这个函数非常长,总共多达 3000 行。
那么下面我们就来看看 COMPARE_OP 对应的指令实现,不过这里多提一句:不光是列表,其它对象进行比较的时候对应的指令序列也是 COMPARE_OP。
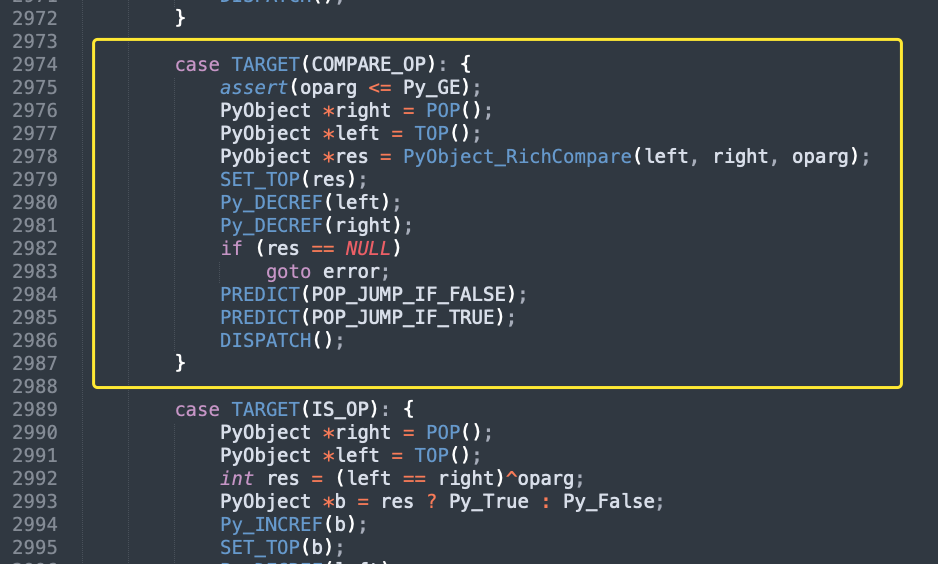
我们来分析一下:
case TARGET(COMPARE_OP): {
// 这里的 oparg 表示的就是指令参数,显然它和指令序列(opcode)在进入 switch 语句之前就已经被获取
// 然后这里断言 oparg 必须要小于等于 Py_GE,因为比较操作符中最大的就是 Py_GE,而我们这里是 ==,所以 oparg 的值等于 2
assert(oparg <= Py_GE);
// BUILD_LIST 构建的两个列表(指针)会被压入运行时栈,然后这里再将其获取
// 当然这里只是以列表为例,但我们说进行比较的不一定是列表,可以是任意对象
// 因此 right 就是比较操作符(我们这里是 ==)右边的变量,left 就是左边的变量
PyObject *right = POP(); // 元素会从栈中弹出
PyObject *left = TOP(); // 注意这里是 TOP(),不是 POP(),所以操作符左边的变量还留在栈里面
// 调用 PyObject_RichCompare,传入 left、right、oparg 进行调用,得到返回结果 res
// 显然具体的比较逻辑就在 PyObject_RichCompare 里面
PyObject *res = PyObject_RichCompare(left, right, oparg);
// 用 res 将栈顶的元素替换掉,所以操作符左边的变量不需要从栈里面弹出,直接将结果与之替换即可
// 最后再返回
SET_TOP(res);
Py_DECREF(left);
Py_DECREF(right);
if (res == NULL)
goto error;
PREDICT(POP_JUMP_IF_FALSE);
PREDICT(POP_JUMP_IF_TRUE);
DISPATCH();
}这里涉及到了运行时栈,具体细节就不再赘述了,总之运行时栈是必不可少的,因为 Python 的指令只能有一个指令参数,但是 PyObject_RichCompare 函数需要三个参数,因此其它的参数只能通过运行时栈给出。
我们这里只需要知道,Python 中的比较,在底层会调用 PyObject_RichCompare 函数即可:
a == b # PyObject_RichCompare(a, b, Py_EQ)
a >= b # PyObject_RichCompare(a, b, Py_GE)
a != b # PyObject_RichCompare(a, b, Py_NE)
...下面来看看 PyObject_RichCompare 里面的逻辑,该函数藏身于 Objects/object.c 中。
PyObject *
PyObject_RichCompare(PyObject *v, PyObject *w, int op)
{ // 参数 v 就是上面的 left、w 就是 right、op 就是 oparg
// 获取线程状态对象,这里不需要关注
PyThreadState *tstate = _PyThreadState_GET();
// 0 <= op <= 5
assert(Py_LT <= op && op <= Py_GE);
// 如果有一方为 NULL,则调用失败
if (v == NULL || w == NULL) {
if (!_PyErr_Occurred(tstate)) {
PyErr_BadInternalCall();
}
return NULL;
}
// 这里的 _Py_EnterRecursiveCall 和结尾的 _Py_LeaveRecursiveCall 会成对出现,主要是用于递归比较的,举个栗子
/*
a = [None]
a.append(a)
print(a) # [None, [...]]
print(a[1][1][1][1][1][1][1][1][1][1]) # [None, [...]]
print(a[1][1][1][1][1][1][1][1][1][0]) # None
print(a == a) # True
*/
// 显然 a 后面无论接多少个 [1] 都是合法的,因此就意味着要无限地比较下去,而 Python 显然不会允许这种情况发生
// 因此这一步就是为了应对这种情况出现
if (_Py_EnterRecursiveCall(tstate, " in comparison")) {
return NULL;
}
// 调用 do_richcompare,得到返回结果
PyObject *res = do_richcompare(tstate, v, w, op);
_Py_LeaveRecursiveCall(tstate);
return res;
}可以看到 PyObject_RichCompare 里面也不是真正负责执行比较逻辑的,该函数相当于做了一些检测,而比较的结果是调用 do_richcompare 得到的,显然我们需要到这个函数中查看,该函数同样位于 Objects/object.c 中。
static PyObject *
do_richcompare(PyThreadState *tstate, PyObject *v, PyObject *w, int op)
{
// richcmpfunc f 相当于声明一个比较函数,因为 Python 将每个比较操作都抽象成了一个魔法方法,比如:__ge__、__eq__ 等等
// 虽然在 Python 中不同的比较操作对应不同的魔法方法,但底层对应的都是 PyTypeObject 的 tp_richcompare 成员
// 该成员负责所有的比较操作,至于到底是哪一种,则由参数来控制
/* 因此我们看到具体的比较逻辑,还是定义在对应的类对象中
比如:
list 对象的比较逻辑定义在 PyList_Type -> tp_richcompare 中
tuple 对象的比较逻辑定义在 PyTuple_Type -> tp_richcompare 中
Dict 对象的比较逻辑定义在 PyDict_Type -> tp_richcompare 中
Set 对象的比较逻辑定义在 PySet_Type -> tp_richcompare 中
*/
richcmpfunc f;
// 用于存储比较之后的结果
PyObject *res;
int checked_reverse_op = 0;
/* Py_TYPE(obj) 表示获取 obj 的类型;
Py_IS_TYPE(obj, cls) 则是判断 obj 的类型是否为 cls
PyType_IsSubtype(cls1, cls2) 负责判断 cls1 是否是 cls2 的子类
所以下面 if 语句的含义就是:当 v 和 w 的类型不同、并且 w 的类型是 v 的类型的子类、
并且 w 的类型对象内部的 tp_richcompare 成员不为 NULL,然后走这个分支。
直接说的话,可能不是很好解释这个 if 语句到底在做什么,我们可以用一个 Python 测试用例解释一下:
class A:
def __eq__(self, other):
return "A"
class B(A):
def __eq__(self, other):
return "B"
print(A() == B()) # B
我们知道默认情况下,如果操作符左边的两个对象之间没有任何关系,那么比较的时候优先会找操作符左边的对象的魔法方法
所以如果 B 不继承 A,也就是 A 和 B 自己没有任何关系,那么按照优先级,A() == B() 就会返回字符串 "A"
但如果操作符 "右侧的对象的类对象" 是 "左侧的对象的类对象" 的子类,那么这个规则就会被打破
解释器就会执行操作符右侧的对象的魔法方法,所以这里 B 继承 A,A() == B() 返回了字符串 "B"
这个 if 语句就是来干这件事的,因此这里的 f 等于 Py_TYPE(w)->tp_richcompare
*/
if (!Py_IS_TYPE(v, Py_TYPE(w)) &&
PyType_IsSubtype(Py_TYPE(w), Py_TYPE(v)) &&
(f = Py_TYPE(w)->tp_richcompare) != NULL) {
checked_reverse_op = 1;
// 会取出 w 对应的 tp_richcompare,将参数传递进去,进行调用
// 其中 _Py_SwappedOp[op] 是负责将 op 以宏的形式传递,比如 op 是 2,那么 _Py_SwappedOp[op] 就是 Py_EQ,不过结果也是 2
// 调用之后将结果保存起来
res = (*f)(w, v, _Py_SwappedOp[op]);
/* 然后这里对 res 有一个判断,它是做什么的呢?
首先我们上面说了,==、!=、>=、<=、<、> 在 Python 中对应不同的魔法方法
但在底层解释器的角度而言,对应的都是类型对象的 tp_richcompare
至于底层执行这个函数的时候,到底执行哪一个比较操作,则是由参数控制
比如我们上面实现了 __eq__,意味着 tp_richcompare 不为 NULL,那么进行比较的时候毫无疑问肯定会走这个分支
但如果我们执行的不是 A() == B(),而是 A() != B(),那么这里的 res 就返回 Py_NotImplemented
因为 A 和 B 内部都没有定义 __ne__,因此 tp_richcompare 内部也就不包含处理比较操作为 != 时的逻辑
所以这个分支一定会走,但返回的 res 会等于 Py_NotImplemented
*/
if (res != Py_NotImplemented)
// 返回了 res,并且不等于 Py_NotImplemented,才会返回
return res;
Py_DECREF(res);
}
// 如果不是上面那种情况,那么就看 v 是否定义了相应的魔法方法,也就是 Py_TYPE(v) 的 tp_richcompare 成员是否不为 NULL
// 如果有的话就取出,然后传递参数进行调用,其它逻辑类似
if ((f = Py_TYPE(v)->tp_richcompare) != NULL) {
res = (*f)(v, w, op);
if (res != Py_NotImplemented)
return res;
Py_DECREF(res);
}
// 如果 Py_TYPE(v) 的 tp_richcompare 成员为 NULL,或者 res 为 Py_NotImplemented
// 就意味着在 Python 的层面,操作符左边的对象内部没有定义该操作符对应的魔法方法(可能定义了别的)
// 那么此时会去看操作符右侧的对象内部是否有相应的魔法方法,所以这里会看 Py_TYPE(w) 的 tp_richcompare 是否不为 NULL
if (!checked_reverse_op && (f = Py_TYPE(w)->tp_richcompare) != NULL) {
res = (*f)(w, v, _Py_SwappedOp[op]);
if (res != Py_NotImplemented)
return res;
Py_DECREF(res);
}
/* 走到这里说明,要么上面的三个 if 分支一个都没有通过,即操作两边的对象的内部都没有定义任何关于比较操作的魔法方法
或者通过了,但返回的 res 等于 Py_NotImplemented,也就是定义了比较操作的魔法方法,
但是当前执行的操作符对应的魔法方法没有实现 */
// 不过对于 Python 而言,== 和 != 是永远不会报错的,所以还要检测操作符是不是 == 或 !=
switch (op) {
/* 尽管指定的操作符没有实现,但如果操作符是 == 或者 !=,也就是 op 为 Py_EQ 或者 Py_NE 时
那么就比较两个对象的内存地址,比如 class A: pass
A 里面没有实现任何的魔法方法,但 a = A(); a == a 就是 True,因为对象的内存地址是一样的
这里说明一下,Python 中的变量在 C 的层面就是一个泛型指针(PyObject *),它存储的不是对象(PyObject),而是对象的地址
变量在传递的时候会传递地址,但是在操作一个变量时会自动操作变量指向的内存
所以在判断两个变量是否指向同一个对象的时候(相当于 is),在 C 的层面只需要比较两个指针是否相等即可
而在比较两个变量指向的对象是否相等(也就是 == ),那么会将两个变量指向的对象所维护的值取出来,调用 PyObject_RichCompare 进行比较
*/
case Py_EQ:
// 这里的 v 和 w 显然就相当于 Python 中的变量,就是一个指针
// 因此判断两个变量是否指向同一个对象,直接判断这两个指针存的地址是否相等即可
res = (v == w) ? Py_True : Py_False;
break;
case Py_NE:
// 同理
res = (v != w) ? Py_True : Py_False;
break;
// 如果比较操作符不是 == 或者 !=,那么就不好意思了,这两个实例之间不允许执行当前的比较操作
default:
_PyErr_Format(tstate, PyExc_TypeError,
"'%s' not supported between instances of '%.100s' and '%.100s'",
opstrings[op],
Py_TYPE(v)->tp_name,
Py_TYPE(w)->tp_name);
return NULL;
}
// 增加引用计数,返回
Py_INCREF(res);
return res;
}以上就是 do_richcompare 的逻辑,它里面干了哪些事情呢?我们说里面三个 if 语句,主要用于确定到底该执行谁的魔法方法,比如 A 和 B 的实例进行比较:
1. 如果 A 和 B 是不同的类、并且 B 还是 A 的子类,那么 "A() 操作符 B()" 会优先去 B 中查找操作符对应的魔法方法2. 否则的话,会按照优先级,先找 A(操作符左边)的魔法方法3. 如果左边没有,那么就最后再找右边
如果成功执行则直接返回,否则的话再对操作符进行判定,如果是 == 或者 != ,那么就比较两个对象是否是同一个对象。
虽然花了一定的笔墨解释完了比较操作在底层的逻辑,但是我们上面的问题本质上依旧没有得到解决,我们还是不知道列表是如何比较的。因为很明显,比较的核心在于类型对象的 tp_richcompare 中,它返回的结果就是这里的 res,所以如果我们想知道列表是如何比较的,那么就去 PyList_Type 的 tp_richcompare 成员中查看即可。
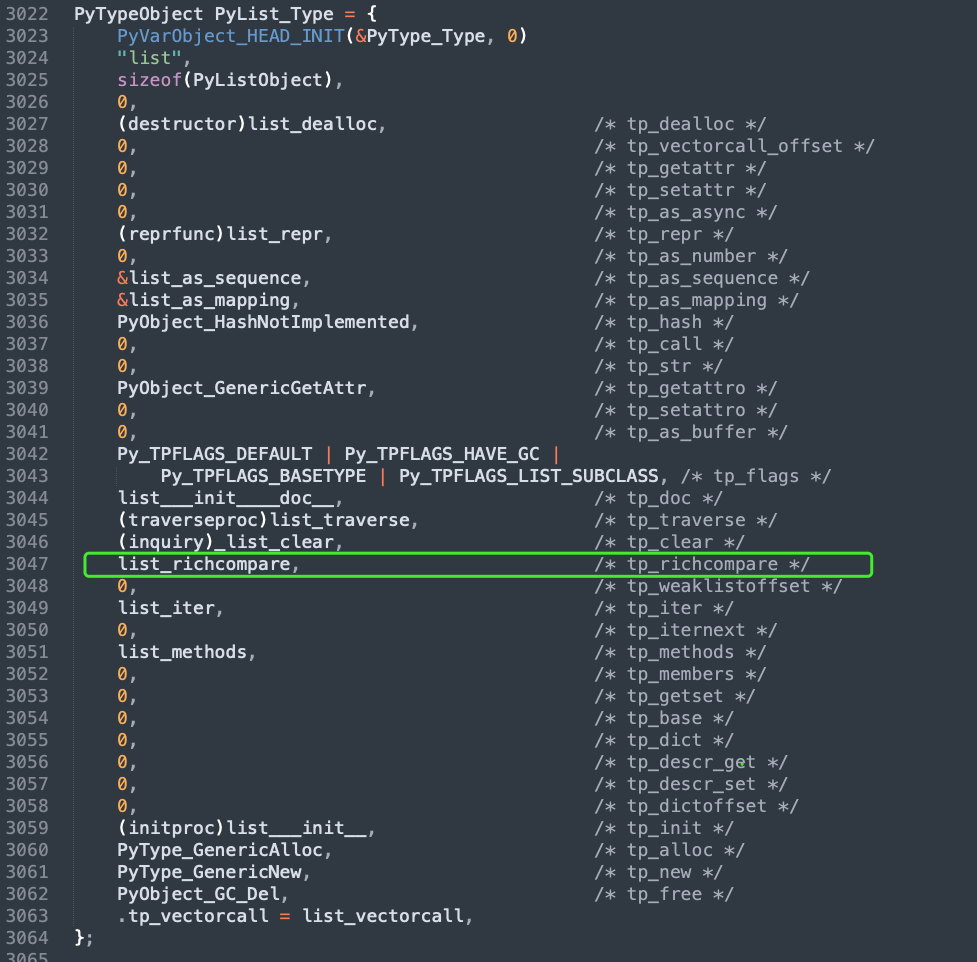
而 PyList_Type 的 tp_richcompare 成员对应的是 list_richcompare 函数,我们来看一下,其藏身于 Objects/listobject.c 中。
static PyObject *
list_richcompare(PyObject *v, PyObject *w, int op)
{
PyListObject *vl, *wl;
Py_ssize_t i;
// v 和 w 一定是 PyListObject *
if (!PyList_Check(v) || !PyList_Check(w))
Py_RETURN_NOTIMPLEMENTED;
// 将 PyObject * 转成 PyListObject *
vl = (PyListObject *)v;
wl = (PyListObject *)w;
// 快分支:如果两个列表连长度都不相等,那么当比较操作符是 == 或 != 的时候可以直接出结果
if (Py_SIZE(vl) != Py_SIZE(wl) && (op == Py_EQ || op == Py_NE)) {
// op 是 ==,返回 False
// op 是 !=,返回 True
if (op == Py_EQ)
Py_RETURN_FALSE;
else
Py_RETURN_TRUE;
}
// 当列表长度相等,或者操作不是 == 或者 !=,那么就需要将两个列表中的元素进行逐个比较了
for (i = 0; i < Py_SIZE(vl) && i < Py_SIZE(wl); i++) {
PyObject *vitem = vl->ob_item[i];
PyObject *witem = wl->ob_item[i];
/*我们说 Python 中变量本质上是一个指针,当然不光是变量,列表、元组、字典等容器里面容纳的也是指针
如果 vitem == witem,说明这两个列表存储的是同一个对象的指针(在 Python 里面也可以说引用)
所以直接就 continue 了,说明当前位置的两个元素是相等的
因此我们就解释了在最开始的问题中,为什么 a1 != a1、np.nan != np.nan,但 [a1] == [a1] 和 [np.nan] == [np.nan] 却都是成立的
再比如 None > None 会报错,但是 [None] > [None] 却不会,原因就在于 None 是单例的,地址相同
而地址相同,那么就不比了(不管这两个对象能不能比),而是直接看下一个元素 */
if (vitem == witem) {
continue;
}
// 增加引用计数
Py_INCREF(vitem);
Py_INCREF(witem);
/*当不是同一个对象时,那就比较对象维护的值是否相同,这里又出现了一个 PyObject_RichCompareBool
它在底层会调用之前说的 PyObject_RichCompare,只不过在调用之前会先检测对象的地址是否相同
如果是同一个对象,并且操作符是 ==、!=,那么会直接根据对象的地址判断
如果不是同一个对象,或者操作符不是 == 或者 !=,再调用 PyObject_RichCompare 比较对象维护的值之间的关系,
此外该函数返回的是整型,为真返回 1、为假返回 0,报错了返回 -1 */
int k = PyObject_RichCompareBool(vitem, witem, Py_EQ);
Py_DECREF(vitem);
Py_DECREF(witem);
if (k < 0)
return NULL;
// 为假直接 break,否则继续下一轮循环
if (!k)
break;
}
// 两个列表如果长度不相等,那么不断遍历的话,肯定有一方先结束
// 下面逻辑就是处理长度不相等的情况,比较简单,可以自己看一下
if (i >= Py_SIZE(vl) || i >= Py_SIZE(wl)) {
/* No more items to compare -- compare sizes */
Py_RETURN_RICHCOMPARE(Py_SIZE(vl), Py_SIZE(wl), op);
}
/* We have an item that differs -- shortcuts for EQ/NE */
if (op == Py_EQ) {
Py_RETURN_FALSE;
}
if (op == Py_NE) {
Py_RETURN_TRUE;
}
/* Compare the final item again using the proper operator */
return PyObject_RichCompare(vl->ob_item[i], wl->ob_item[i], op);
}因此到这里我们才算真正解释了最开始的问题,在调用 PyObject_RichCompare 进行比较的时候,a1 == a1 会走内部的 __eq__,而在里面返回的 False。而 [a1] == [a1] 会走列表的 __eq__,而里面在比较元素的时候会先比较地址是否一样,如果一样直接就过了,根本不会走 type(a1) 里面的 __eq__。
Python 中的 in 也是同理,我们知道 a in b 等价于 b.__contains__(a),逻辑就是不断地对 b 进行迭代,将得到的元素依次和 a 进行比较,如果相等则直接返回 True;如果迭代结束时一直没有找到和 a 相等的元素,那么返回 False。所以逻辑很简单,但我想说的是,这里比较相等的逻辑也会先比较对象的地址是否相同,如果地址相同直接为 True,当地址不同时,才会比较值是否一致。而从底层来看的话,这里的比较会调用 PyObject_RichCompareBool,而我们知道在这个函数里面会先比较地址是否一样,地址不一样再比较维护的值是否一样(调用对应的 __eq__)。
class A:
def __eq__(self, other):
return False
a = A()
# 底层调用 PyObject_RichCompare,然后调用 __eq__
print(a == a) # False
# 底层会调用 PyObject_RichCompareBool,会先判断两者是不是同一个对象
print(a in (a,)) # True
print(a in [a]) # True以上就是由 nan 引发的一些思考,当然还是比较简单的,因为是一些之前说过的内容。
static PyObject do_richcompare(PyThreadState tstate, PyObject v, PyObject w, int op) { // richcmpfunc f 相当于声明一个比较函数,因为 Python 将每个比较操作都抽象成了一个魔法方法,比如:ge、eq 等等 // 虽然在 Python 中不同的比较操作对应
Tags: python
via Pocket https://ift.tt/2WlIjlu original site
August 24, 2021 at 03:49PM