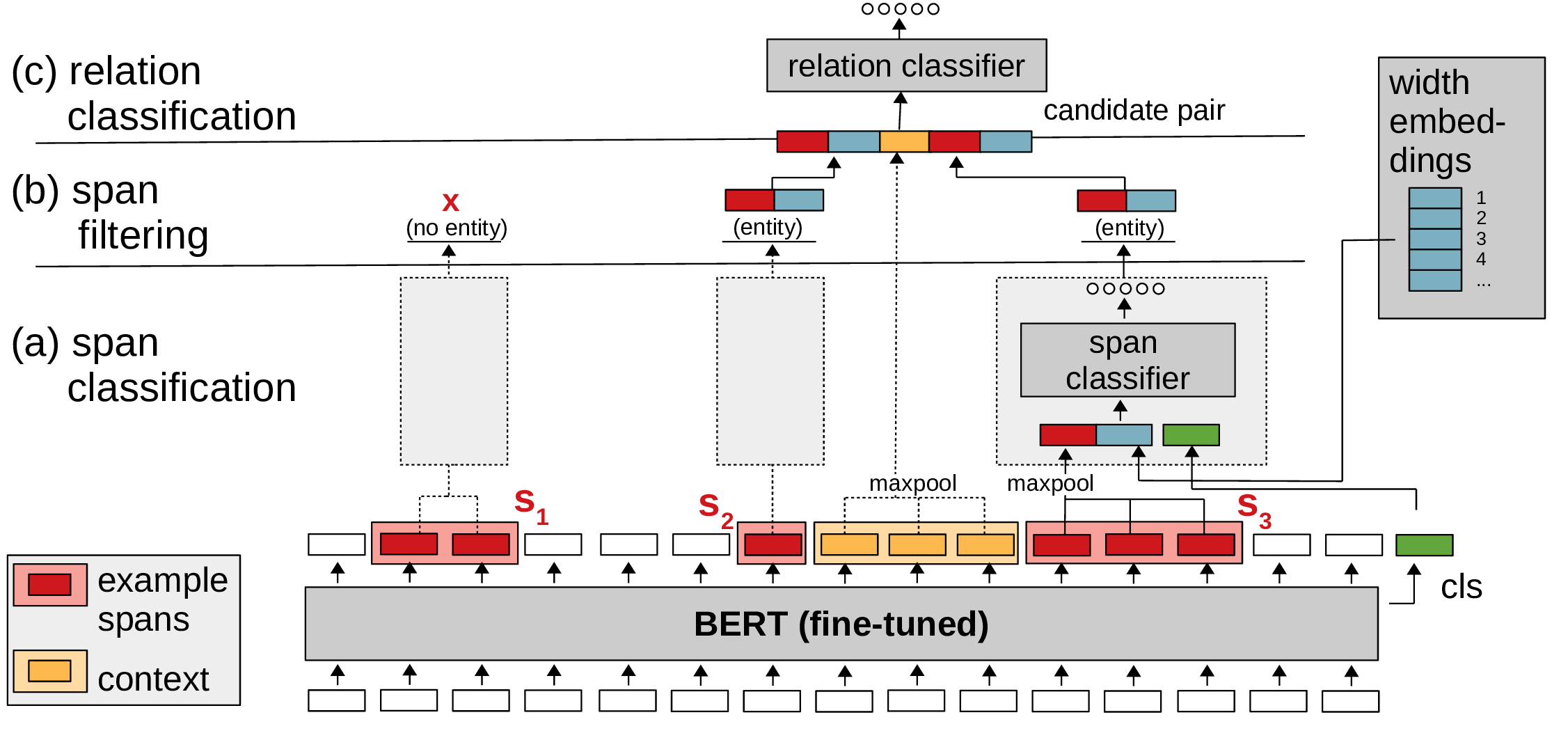
SpERT_chinese
基于论文SpERT: "Span-based Entity and Relation Transformer"的中文关系抽取,同时抽取实体、实体类别和关系类别。
原始论文地址: https://arxiv.org/abs/1909.07755 (published at ECAI 2020)
原始论文代码:https://github.com/lavis-nlp/spert
设置
Requirements
- Required
- Python 3.5+
- PyTorch (tested with version 1.4.0)
- transformers (+sentencepiece, e.g. with 'pip install transformers[sentencepiece]', tested with version 4.1.1)
- scikit-learn (tested with version 0.24.0)
- tqdm (tested with version 4.55.1)
- numpy (tested with version 1.17.4)
- Optional
- jinja2 (tested with version 2.10.3) - if installed, used to export relation extraction examples
- tensorboardX (tested with version 1.6) - if installed, used to save training process to tensorboard
- spacy (tested with version 3.0.1) - if installed, used to tokenize sentences for prediction
pip install transformers ==4.1.1
pip install tensorboardX
pip install tqdm
pip install jinja2
pip install spacy==3.3.1额外的,下载:https://github.com/explosion/spacy-models/releases/download/zh_core_web_sm-3.3.0/zh_core_web_sm-3.3.0.tar.gz 。执行:pip install zh_core_web_sm-3.3.0.tar.gz
还需要在huggingface上下载chinese-bert-wwm-ext到model_hub/chinese-bert-wwm-ext/下。
获取数据
这里使用的数据是千言数据中的信息抽取数据,可以去这里下载:千言(LUGE)| 全面的中文开源数据集合 。下载并解压获得duie_train.json、duie_dev.json、duie_schema.json,将它们放置在data/duie/下,然后运行那下面的process.py以获得:
train.json # 训练集
dev.json # 验证集,如果有测试集,也可以生成test.json
duie_prediction_example.json # 预测样本
duie_types.json # 存储的实体类型和关系类型
entity_types.txt # 实际上用不上,只是我们自己看看
relation_types.txt # 实际上用不上,只是我们自己看看train.json和dev.json里面的数据格式如下所示:
[
{"tokens": ["这", "件", "婚", "事", "原", "本", "与", "陈", "国", "峻", "无", "关", ",", "但", "陈", "国", "峻", "却", "“", "欲", "求", "配", "而", "无", "由", ",", "夜", "间", "乃", "潜", "入", "天", "城", "公", "主", "所", "居", "通", "之"], "entities": [{"type": "人物", "start": 8, "end": 10}, {"type": "人物", "start": 31, "end": 35}], "relations": [{"type": "丈夫", "tail": 0, "head": 1}, {"type": "妻子", "head": 0, "tail": 1}]},
......
]需要说明的是relations里面的head和tail对应的是entities里面实体的列表里的索引。
duie_types.json格式如下所示:
{"entities": {"行政区": {"short": "行政区", "verbose": "行政区"}, "人物": {"short": "人物", "verbose": "人物"}, "气候": {"short": "气候", "verbose": "气候"}, "文学作品": {"short": "文学作品", "verbose": "文学作品"}, "Text": {"short": "Text", "verbose": "Text"}, "学科专业": {"short": "学科专业", "verbose": "学科专业"}, "作品": {"short": "作品", "verbose": "作品"}, "奖项": {"short": "奖项", "verbose": "奖项"}, "国家": {"short": "国家", "verbose": "国家"}, "电视综艺": {"short": "电视综艺", "verbose": "电视综艺"}, "影视作品": {"short": "影视作品", "verbose": "影视作品"}, "企业": {"short": "企业", "verbose": "企业"}, "语言": {"short": "语言", "verbose": "语言"}, "歌曲": {"short": "歌曲", "verbose": "歌曲"}, "Date": {"short": "Date", "verbose": "Date"}, "企业/品牌": {"short": "企业/品牌", "verbose": "企业/品牌"}, "地点": {"short": "地点", "verbose": "地点"}, "Number": {"short": "Number", "verbose": "Number"}, "图书作品": {"short": "图书作品", "verbose": "图书作品"}, "景点": {"short": "景点", "verbose": "景点"}, "城市": {"short": "城市", "verbose": "城市"}, "学校": {"short": "学校", "verbose": "学校"}, "音乐专辑": {"short": "音乐专辑", "verbose": "音乐专辑"}, "机构": {"short": "机构", "verbose": "机构"}},
"relations": {"编剧": {"short": "编剧", "verbose": "编剧", "symmetric": false}, "修业年限": {"short": "修业年限", "verbose": "修业年限", "symmetric": false}, "毕业院校": {"short": "毕业院校", "verbose": "毕业院校", "symmetric": false}, "气候": {"short": "气候", "verbose": "气候", "symmetric": false}, "配音": {"short": "配音", "verbose": "配音", "symmetric": false}, "注册资本": {"short": "注册资本", "verbose": "注册资本", "symmetric": false}, "成立日期": {"short": "成立日期", "verbose": "成立日期", "symmetric": false}, "父亲": {"short": "父亲", "verbose": "父亲", "symmetric": false}, "面积": {"short": "面积", "verbose": "面积", "symmetric": false}, "专业代码": {"short": "专业代码", "verbose": "专业代码", "symmetric": false}, "作者": {"short": "作者", "verbose": "作者", "symmetric": false}, "首都": {"short": "首都", "verbose": "首都", "symmetric": false}, "丈夫": {"short": "丈夫", "verbose": "丈夫", "symmetric": false}, "嘉宾": {"short": "嘉宾", "verbose": "嘉宾", "symmetric": false}, "官方语言": {"short": "官方语言", "verbose": "官方语言", "symmetric": false}, "作曲": {"short": "作曲", "verbose": "作曲", "symmetric": false}, "号": {"short": "号", "verbose": "号", "symmetric": false}, "票房": {"short": "票房", "verbose": "票房", "symmetric": false}, "简称": {"short": "简称", "verbose": "简称", "symmetric": false}, "母亲": {"short": "母亲", "verbose": "母亲", "symmetric": false}, "制片人": {"short": "制片人", "verbose": "制片人", "symmetric": false}, "导演": {"short": "导演", "verbose": "导演", "symmetric": false}, "歌手": {"short": "歌手", "verbose": "歌手", "symmetric": false}, "改编自": {"short": "改编自", "verbose": "改编自", "symmetric": false}, "海拔": {"short": "海拔", "verbose": "海拔", "symmetric": false}, "占地面积": {"short": "占地面积", "verbose": "占地面积", "symmetric": false}, "出品公司": {"short": "出品公司", "verbose": "出品公司", "symmetric": false}, "上映时间": {"short": "上映时间", "verbose": "上映时间", "symmetric": false}, "所在城市": {"short": "所在城市", "verbose": "所在城市", "symmetric": false}, "主持人": {"short": "主持人", "verbose": "主持人", "symmetric": false}, "作词": {"short": "作词", "verbose": "作词", "symmetric": false}, "人口数量": {"short": "人口数量", "verbose": "人口数量", "symmetric": false}, "祖籍": {"short": "祖籍", "verbose": "祖籍", "symmetric": false}, "校长": {"short": "校长", "verbose": "校长", "symmetric": false}, "朝代": {"short": "朝代", "verbose": "朝代", "symmetric": false}, "主题曲": {"short": "主题曲", "verbose": "主题曲", "symmetric": false}, "获奖": {"short": "获奖", "verbose": "获奖", "symmetric": false}, "代言人": {"short": "代言人", "verbose": "代言人", "symmetric": false}, "主演": {"short": "主演", "verbose": "主演", "symmetric": false}, "所属专辑": {"short": "所属专辑", "verbose": "所属专辑", "symmetric": false}, "饰演": {"short": "饰演", "verbose": "饰演", "symmetric": false}, "董事长": {"short": "董事长", "verbose": "董事长", "symmetric": false}, "主角": {"short": "主角", "verbose": "主角", "symmetric": false}, "妻子": {"short": "妻子", "verbose": "妻子", "symmetric": false}, "总部地点": {"short": "总部地点", "verbose": "总部地点", "symmetric": false}, "国籍": {"short": "国籍", "verbose": "国籍", "symmetric": false}, "创始人": {"short": "创始人", "verbose": "创始人", "symmetric": false}, "邮政编码": {"short": "邮政编码", "verbose": "邮政编码", "symmetric": false}}}例子
(1) 在duie上使用训练集进行训练, 在验证集上进行评估。需要注意的是,这里我只使用了训练集的10000条数据和验证集的10000条数据训练了1个epoch。
python ./spert.py train --config configs/duie_train.conf--------------------------------------------------
Config:
{'label': 'duie_train', 'model_type': 'spert', 'model_path': 'model_hub/chinese-bert-wwm-ext', 'tokenizer_path': 'model_hub/chinese-bert-wwm-ext', 'train_path': 'data/duie/train.json', 'valid_path': 'data/duie/dev.json', 'types_path': 'data/duie/duie_types.json', 'train_batch_size': '2', 'eval_batch_size': '1', 'neg_entity_count': '100', 'neg_relation_count': '100', 'epochs': '1', 'lr': '5e-5', 'lr_warmup': '0.1', 'weight_decay': '0.01', 'max_grad_norm': '1.0', 'rel_filter_threshold': '0.4', 'size_embedding': '25', 'prop_drop': '0.1', 'max_span_size': '20', 'store_predictions': 'true', 'store_examples': 'true', 'sampling_processes': '2', 'max_pairs': '1000', 'final_eval': 'true', 'log_path': 'data/log/', 'save_path': 'data/save/'}
Repeat 1 times
--------------------------------------------------
Iteration 0
--------------------------------------------------
2022-11-17 06:48:16,488 [MainThread ] [INFO ] Datasets: data/duie/train.json, data/duie/dev.json
2022-11-17 06:48:16,489 [MainThread ] [INFO ] Model type: spert
Parse dataset 'train': 100% 10000/10000 [00:52<00:00, 189.61it/s]
<spert.entities.Dataset object at 0x7f24c8c19550>
Parse dataset 'valid': 100% 10000/10000 [00:52<00:00, 191.25it/s]
<spert.entities.Dataset object at 0x7f24c8c19250>
2022-11-17 06:50:02,108 [MainThread ] [INFO ] Relation type count: 49
2022-11-17 06:50:02,108 [MainThread ] [INFO ] Entity type count: 25
2022-11-17 06:50:02,108 [MainThread ] [INFO ] Entities:
2022-11-17 06:50:02,108 [MainThread ] [INFO ] No Entity=0
2022-11-17 06:50:02,108 [MainThread ] [INFO ] 行政区=1
2022-11-17 06:50:02,109 [MainThread ] [INFO ] 人物=2
2022-11-17 06:50:02,109 [MainThread ] [INFO ] 气候=3
2022-11-17 06:50:02,109 [MainThread ] [INFO ] 文学作品=4
2022-11-17 06:50:02,109 [MainThread ] [INFO ] Text=5
2022-11-17 06:50:02,109 [MainThread ] [INFO ] 学科专业=6
2022-11-17 06:50:02,109 [MainThread ] [INFO ] 作品=7
2022-11-17 06:50:02,109 [MainThread ] [INFO ] 奖项=8
2022-11-17 06:50:02,109 [MainThread ] [INFO ] 国家=9
2022-11-17 06:50:02,109 [MainThread ] [INFO ] 电视综艺=10
2022-11-17 06:50:02,110 [MainThread ] [INFO ] 影视作品=11
2022-11-17 06:50:02,110 [MainThread ] [INFO ] 企业=12
2022-11-17 06:50:02,110 [MainThread ] [INFO ] 语言=13
2022-11-17 06:50:02,110 [MainThread ] [INFO ] 歌曲=14
2022-11-17 06:50:02,110 [MainThread ] [INFO ] Date=15
2022-11-17 06:50:02,110 [MainThread ] [INFO ] 企业/品牌=16
2022-11-17 06:50:02,110 [MainThread ] [INFO ] 地点=17
2022-11-17 06:50:02,110 [MainThread ] [INFO ] Number=18
2022-11-17 06:50:02,111 [MainThread ] [INFO ] 图书作品=19
2022-11-17 06:50:02,111 [MainThread ] [INFO ] 景点=20
2022-11-17 06:50:02,111 [MainThread ] [INFO ] 城市=21
2022-11-17 06:50:02,111 [MainThread ] [INFO ] 学校=22
2022-11-17 06:50:02,111 [MainThread ] [INFO ] 音乐专辑=23
2022-11-17 06:50:02,111 [MainThread ] [INFO ] 机构=24
2022-11-17 06:50:02,111 [MainThread ] [INFO ] Relations:
2022-11-17 06:50:02,111 [MainThread ] [INFO ] No Relation=0
2022-11-17 06:50:02,112 [MainThread ] [INFO ] 编剧=1
2022-11-17 06:50:02,112 [MainThread ] [INFO ] 修业年限=2
2022-11-17 06:50:02,112 [MainThread ] [INFO ] 毕业院校=3
2022-11-17 06:50:02,112 [MainThread ] [INFO ] 气候=4
2022-11-17 06:50:02,112 [MainThread ] [INFO ] 配音=5
2022-11-17 06:50:02,112 [MainThread ] [INFO ] 注册资本=6
2022-11-17 06:50:02,112 [MainThread ] [INFO ] 成立日期=7
2022-11-17 06:50:02,112 [MainThread ] [INFO ] 父亲=8
2022-11-17 06:50:02,113 [MainThread ] [INFO ] 面积=9
2022-11-17 06:50:02,113 [MainThread ] [INFO ] 专业代码=10
2022-11-17 06:50:02,113 [MainThread ] [INFO ] 作者=11
2022-11-17 06:50:02,113 [MainThread ] [INFO ] 首都=12
2022-11-17 06:50:02,113 [MainThread ] [INFO ] 丈夫=13
2022-11-17 06:50:02,113 [MainThread ] [INFO ] 嘉宾=14
2022-11-17 06:50:02,113 [MainThread ] [INFO ] 官方语言=15
2022-11-17 06:50:02,113 [MainThread ] [INFO ] 作曲=16
2022-11-17 06:50:02,113 [MainThread ] [INFO ] 号=17
2022-11-17 06:50:02,114 [MainThread ] [INFO ] 票房=18
2022-11-17 06:50:02,114 [MainThread ] [INFO ] 简称=19
2022-11-17 06:50:02,114 [MainThread ] [INFO ] 母亲=20
2022-11-17 06:50:02,114 [MainThread ] [INFO ] 制片人=21
2022-11-17 06:50:02,114 [MainThread ] [INFO ] 导演=22
2022-11-17 06:50:02,114 [MainThread ] [INFO ] 歌手=23
2022-11-17 06:50:02,114 [MainThread ] [INFO ] 改编自=24
2022-11-17 06:50:02,114 [MainThread ] [INFO ] 海拔=25
2022-11-17 06:50:02,114 [MainThread ] [INFO ] 占地面积=26
2022-11-17 06:50:02,115 [MainThread ] [INFO ] 出品公司=27
2022-11-17 06:50:02,115 [MainThread ] [INFO ] 上映时间=28
2022-11-17 06:50:02,115 [MainThread ] [INFO ] 所在城市=29
2022-11-17 06:50:02,115 [MainThread ] [INFO ] 主持人=30
2022-11-17 06:50:02,115 [MainThread ] [INFO ] 作词=31
2022-11-17 06:50:02,115 [MainThread ] [INFO ] 人口数量=32
2022-11-17 06:50:02,115 [MainThread ] [INFO ] 祖籍=33
2022-11-17 06:50:02,115 [MainThread ] [INFO ] 校长=34
2022-11-17 06:50:02,116 [MainThread ] [INFO ] 朝代=35
2022-11-17 06:50:02,116 [MainThread ] [INFO ] 主题曲=36
2022-11-17 06:50:02,116 [MainThread ] [INFO ] 获奖=37
2022-11-17 06:50:02,116 [MainThread ] [INFO ] 代言人=38
2022-11-17 06:50:02,116 [MainThread ] [INFO ] 主演=39
2022-11-17 06:50:02,116 [MainThread ] [INFO ] 所属专辑=40
2022-11-17 06:50:02,116 [MainThread ] [INFO ] 饰演=41
2022-11-17 06:50:02,116 [MainThread ] [INFO ] 董事长=42
2022-11-17 06:50:02,117 [MainThread ] [INFO ] 主角=43
2022-11-17 06:50:02,117 [MainThread ] [INFO ] 妻子=44
2022-11-17 06:50:02,117 [MainThread ] [INFO ] 总部地点=45
2022-11-17 06:50:02,117 [MainThread ] [INFO ] 国籍=46
2022-11-17 06:50:02,117 [MainThread ] [INFO ] 创始人=47
2022-11-17 06:50:02,117 [MainThread ] [INFO ] 邮政编码=48
2022-11-17 06:50:02,117 [MainThread ] [INFO ] Dataset: train
2022-11-17 06:50:02,117 [MainThread ] [INFO ] Document count: 10000
2022-11-17 06:50:02,118 [MainThread ] [INFO ] Relation count: 18119
2022-11-17 06:50:02,118 [MainThread ] [INFO ] Entity count: 28033
2022-11-17 06:50:02,118 [MainThread ] [INFO ] Dataset: valid
2022-11-17 06:50:02,118 [MainThread ] [INFO ] Document count: 10000
2022-11-17 06:50:02,118 [MainThread ] [INFO ] Relation count: 18223
2022-11-17 06:50:02,118 [MainThread ] [INFO ] Entity count: 28071
2022-11-17 06:50:02,118 [MainThread ] [INFO ] Updates per epoch: 5000
2022-11-17 06:50:02,118 [MainThread ] [INFO ] Updates total: 5000
Some weights of the model checkpoint at model_hub/chinese-bert-wwm-ext were not used when initializing SpERT: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias']
- This IS expected if you are initializing SpERT from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing SpERT from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of SpERT were not initialized from the model checkpoint at model_hub/chinese-bert-wwm-ext and are newly initialized: ['rel_classifier.weight', 'rel_classifier.bias', 'entity_classifier.weight', 'entity_classifier.bias', 'size_embeddings.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
2022-11-17 06:50:07,261 [MainThread ] [INFO ] Train epoch: 0
Train epoch 0: 100% 5000/5000 [09:01<00:00, 9.24it/s]
2022-11-17 06:59:08,476 [MainThread ] [INFO ] Evaluate: valid
Evaluate epoch 1: 0% 0/10000 [00:00<?, ?it/s]/content/drive/MyDrive/spert/spert/prediction.py:84: UserWarning: __floordiv__ is deprecated, and its behavior will change in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values. To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor').
valid_rel_indices = rel_nonzero // rel_class_count
Evaluate epoch 1: 100% 10000/10000 [06:36<00:00, 25.20it/s]
Evaluation
--- Entities (named entity recognition (NER)) ---
An entity is considered correct if the entity type and span is predicted correctly
type precision recall f1-score support
语言 0.00 0.00 0.00 9
行政区 41.29 87.37 56.08 95
电视综艺 43.94 81.69 57.14 355
奖项 20.90 74.87 32.68 199
Text 42.69 78.23 55.23 634
学校 47.59 93.20 63.01 647
气候 69.64 79.59 74.29 49
Number 29.01 96.58 44.62 292
歌曲 54.55 87.14 67.10 1617
地点 26.25 57.58 36.06 264
影视作品 57.05 92.34 70.53 2704
城市 62.79 46.55 53.47 58
人物 60.93 95.98 74.54 14283
音乐专辑 54.75 79.34 64.79 334
文学作品 35.14 13.27 19.26 98
Date 47.23 97.15 63.56 1193
企业/品牌 26.88 46.30 34.01 54
作品 0.00 0.00 0.00 22
企业 35.62 73.86 48.07 1144
图书作品 64.91 87.12 74.39 1724
机构 39.45 79.37 52.70 1076
学科专业 0.00 0.00 0.00 2
景点 25.00 3.23 5.71 31
国家 29.92 93.28 45.31 640
micro 53.15 90.82 67.06 27524
macro 38.15 64.33 45.52 27524
--- Relations ---
Without named entity classification (NEC)
A relation is considered correct if the relation type and the spans of the two related entities are predicted correctly (entity type is not considered)
type precision recall f1-score support
成立日期 19.31 88.94 31.74 868
注册资本 9.57 87.50 17.25 56
主角 15.45 15.18 15.32 112
饰演 40.00 9.74 15.67 308
祖籍 20.98 73.17 32.61 82
作曲 22.67 59.92 32.90 484
编剧 47.27 7.22 12.53 360
修业年限 0.00 0.00 0.00 1
妻子 24.99 57.30 34.80 747
改编自 0.00 0.00 0.00 34
占地面积 20.69 29.27 24.24 41
主演 33.06 90.21 48.39 2574
气候 39.33 70.00 50.36 50
父亲 15.13 67.36 24.71 916
朝代 11.67 75.84 20.23 356
歌手 23.50 81.08 36.44 1221
导演 32.93 84.82 47.44 1179
面积 7.14 73.53 13.02 34
所在城市 3.12 3.23 3.17 31
海拔 57.14 66.67 61.54 24
票房 4.13 94.83 7.91 116
主持人 27.25 73.46 39.75 260
代言人 10.97 45.61 17.69 57
嘉宾 19.13 51.17 27.84 342
专业代码 0.00 0.00 0.00 1
创始人 19.10 46.22 27.03 119
所属专辑 33.30 81.21 47.23 431
人口数量 16.07 40.91 23.08 22
制片人 0.00 0.00 0.00 97
作者 35.77 83.67 50.11 1837
董事长 14.06 84.77 24.12 440
配音 8.77 46.35 14.74 233
作词 32.24 67.88 43.72 520
上映时间 12.87 92.70 22.60 356
毕业院校 31.41 91.05 46.71 503
获奖 3.66 71.14 6.96 201
官方语言 0.00 0.00 0.00 9
丈夫 24.59 55.96 34.16 747
邮政编码 0.00 0.00 0.00 1
首都 80.00 14.81 25.00 27
主题曲 19.35 64.17 29.74 187
号 34.08 79.17 47.65 96
母亲 14.44 36.99 20.77 519
简称 13.24 65.40 22.02 237
校长 16.77 93.92 28.45 148
总部地点 5.51 49.38 9.92 160
出品公司 18.49 77.78 29.87 405
国籍 11.03 87.44 19.59 661
micro 19.89 72.78 31.25 18210
macro 19.80 54.94 24.77 18210
With named entity classification (NEC)
A relation is considered correct if the relation type and the two related entities are predicted correctly (in span and entity type)
type precision recall f1-score support
成立日期 17.54 80.76 28.82 868
注册资本 8.20 75.00 14.79 56
主角 6.36 6.25 6.31 112
饰演 40.00 9.74 15.67 308
祖籍 20.98 73.17 32.61 82
作曲 22.67 59.92 32.90 484
编剧 47.27 7.22 12.53 360
修业年限 0.00 0.00 0.00 1
妻子 24.99 57.30 34.80 747
改编自 0.00 0.00 0.00 34
占地面积 20.69 29.27 24.24 41
主演 33.04 90.17 48.36 2574
气候 39.33 70.00 50.36 50
父亲 15.13 67.36 24.71 916
朝代 11.50 74.72 19.93 356
歌手 22.51 77.64 34.90 1221
导演 32.86 84.65 47.34 1179
面积 7.14 73.53 13.02 34
所在城市 0.00 0.00 0.00 31
海拔 14.29 16.67 15.38 24
票房 4.13 94.83 7.91 116
主持人 27.10 73.08 39.54 260
代言人 9.70 40.35 15.65 57
嘉宾 19.02 50.88 27.68 342
专业代码 0.00 0.00 0.00 1
创始人 10.42 25.21 14.74 119
所属专辑 26.93 65.66 38.19 431
人口数量 16.07 40.91 23.08 22
制片人 0.00 0.00 0.00 97
作者 35.19 82.31 49.30 1837
董事长 14.02 84.55 24.05 440
配音 8.77 46.35 14.74 233
作词 32.24 67.88 43.72 520
上映时间 12.16 87.64 21.36 356
毕业院校 31.41 91.05 46.71 503
获奖 3.64 70.65 6.92 201
官方语言 0.00 0.00 0.00 9
丈夫 24.59 55.96 34.16 747
邮政编码 0.00 0.00 0.00 1
首都 80.00 14.81 25.00 27
主题曲 19.19 63.64 29.49 187
号 34.08 79.17 47.65 96
母亲 14.44 36.99 20.77 519
简称 11.36 56.12 18.89 237
校长 16.77 93.92 28.45 148
总部地点 3.07 27.50 5.52 160
出品公司 18.31 77.04 29.59 405
国籍 10.97 86.99 19.49 661
micro 19.36 70.83 30.41 18210
macro 18.08 51.39 22.69 18210
2022-11-17 07:08:01,224 [MainThread ] [INFO ] Logged in: data/log/duie_train/2022-11-17_06:48:16.414088
2022-11-17 07:08:01,224 [MainThread ] [INFO ] Saved in: data/save/duie_train/2022-11-17_06:48:16.414088(2) 在测试集上进行评估,由于我们没有测试集,里面参数设置为验证集地址。我们要修改duie_eval.conf里面保存好的模型的地址,一般的,在data/save/duie_train/日期文件夹/final_model下。如果测试集和验证集一样,那么就是和上述一样的结果。
python ./spert.py eval --config configs/duie_eval.conf(3) 我们要修改duie_eval.conf里面保存好的模型的地址,一般的,在data/save/duie_train/日期文件夹/final_model下。进行预测使用的是duie_prediction_example.json,里面的格式是:
[{"tokens": ["《", "废", "物", "小", "说", "》", "是", "新", "片", "场", "出", "品", ",", "杜", "煜", "峰", "(", "东", "北", "花", "泽", "类", ")", "导", "演", "2", "的", "动", "画", "首", "作", ",", "作", "品", "延", "续", "了", "他", "一", "贯", "的", "脱", "力", "系", "搞", "笑", "风", "格"]}, ["《", "废", "物", "小", "说", "》", "是", "新", "片", "场", "出", "品", ",", "杜", "煜", "峰", "(", "东", "北", "花", "泽", "类", ")", "导", "演", "2", "的", "动", "画", "首", "作", ",", "作", "品", "延", "续", "了", "他", "一", "贯", "的", "脱", "力", "系", "搞", "笑", "风", "格"], "《 废 物 小 说 》 是 新 片 场 出 品 , 杜 煜 峰 ( 东 北 花 泽 类 ) 导 演 2 的 动 画 首 作 , 作 品 延 续 了 他 一 贯 的 脱 力 系 搞 笑 风 格"]python ./spert.py predict --config configs/example_predict.conf[{"tokens": ["《", "废", "物", "小", "说", "》", "是", "新", "片", "场", "出", "品", ",", "杜", "煜", "峰", "(", "东", "北", "花", "泽", "类", ")", "导", "演", "2", "的", "动", "画", "首", "作", ",", "作", "品", "延", "续", "了", "他", "一", "贯", "的", "脱", "力", "系", "搞", "笑", "风", "格"], "entities": [{"type": "影视作品", "start": 1, "end": 5}, {"type": "企业", "start": 7, "end": 10}, {"type": "人物", "start": 13, "end": 16}], "relations": [{"type": "出品公司", "head": 0, "tail": 1}, {"type": "导演", "head": 0, "tail": 2}]}, {"tokens": ["《", "废", "物", "小", "说", "》", "是", "新", "片", "场", "出", "品", ",", "杜", "煜", "峰", "(", "东", "北", "花", "泽", "类", ")", "导", "演", "2", "的", "动", "画", "首", "作", ",", "作", "品", "延", "续", "了", "他", "一", "贯", "的", "脱", "力", "系", "搞", "笑", "风", "格"], "entities": [{"type": "影视作品", "start": 1, "end": 5}, {"type": "企业", "start": 7, "end": 10}, {"type": "人物", "start": 13, "end": 16}], "relations": [{"type": "出品公司", "head": 0, "tail": 1}, {"type": "导演", "head": 0, "tail": 2}]}, {"tokens": ["《", "废", "物", "小", "说", "》", "是", "新", "片", "场", "出", "品", ",", "杜", "煜", "峰", "(", "东", "北", "花", "泽", "类", ")", "导", "演", "2", "的", "动", "画", "首", "作", ",", "作", "品", "延", "续", "了", "他", "一", "贯", "的", "脱", "力", "系", "搞", "笑", "风", "格"], "entities": [{"type": "影视作品", "start": 1, "end": 5}, {"type": "企业", "start": 7, "end": 10}, {"type": "人物", "start": 13, "end": 16}], "relations": [{"type": "出品公司", "head": 0, "tail": 1}, {"type": "导演", "head": 0, "tail": 2}]}]这里有三条结果,也就是说我们在duie_prediction_example.json里面任意一种格式都行。
补充
- 针对于中文数据集,将配置参数max_span_size = 20,这里是实体的最大长度,可酌情修改。
- 在处理duie数据集的时候进行了一些细微的处理,具体可参考process.py里面。
参考
lavis-nlp/spert: PyTorch code for SpERT: Span-based Entity and Relation Transformer (github.com)