 daedae-cc
commented
3 years ago
daedae-cc
commented
3 years ago Transformer
结构
轮廓
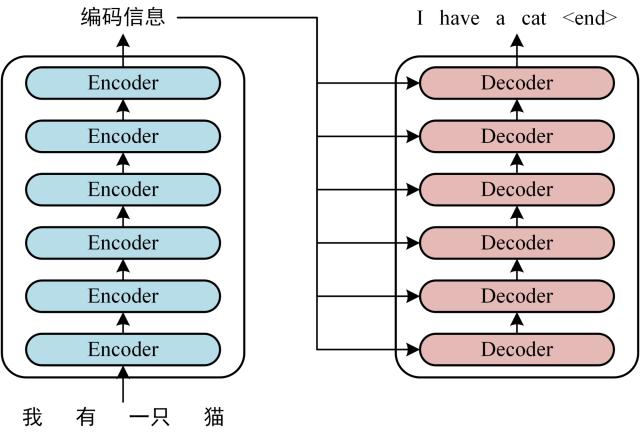
Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。
内部结构
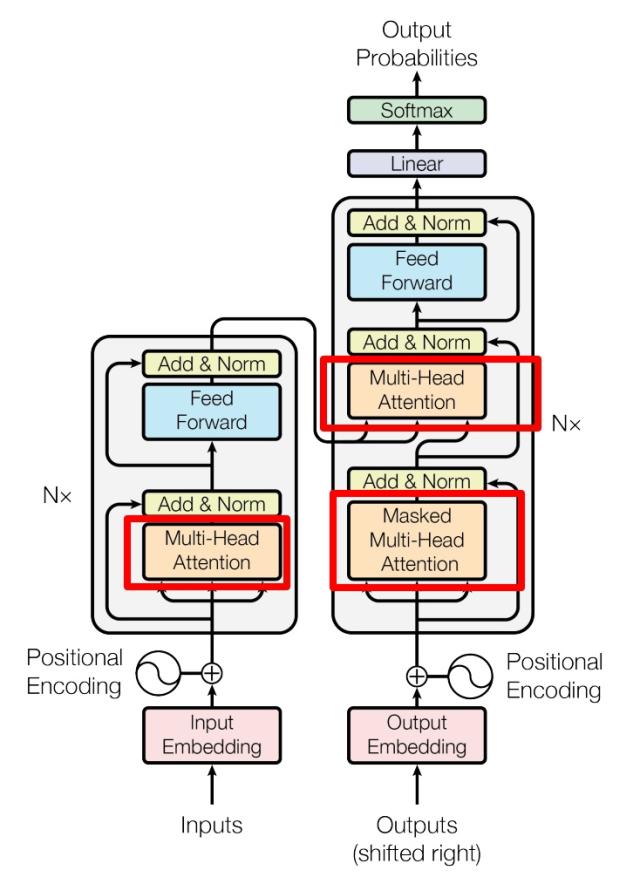
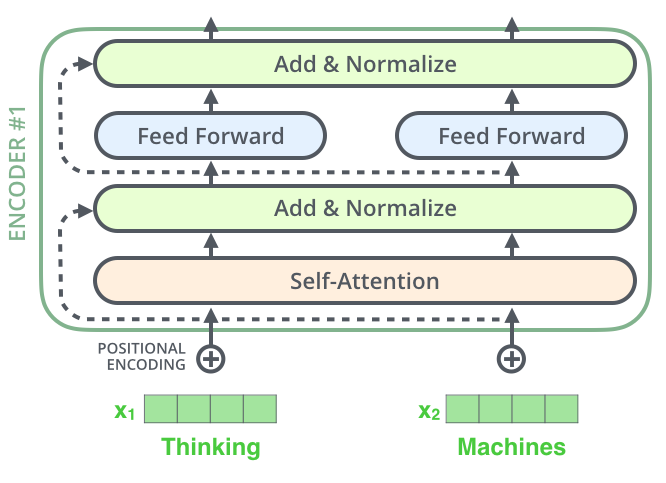
左侧为一个 Encoder block,右侧为一个 Decoder block。
红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention 组成的。
一个 Encoder block 包含一个 Multi-Head Attention,而一个 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。
Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接,用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
工作流程
- 获取输入句子的每一个单词的表示向量 $x$,$x$ 由单词的 Embedding 和单词位置的 Embedding 相加得到。
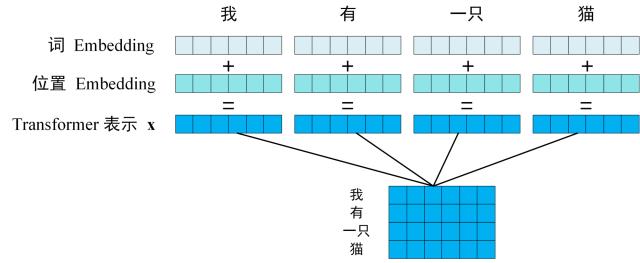
位置 Embedding:表示单词出现在句子中的位置。
-
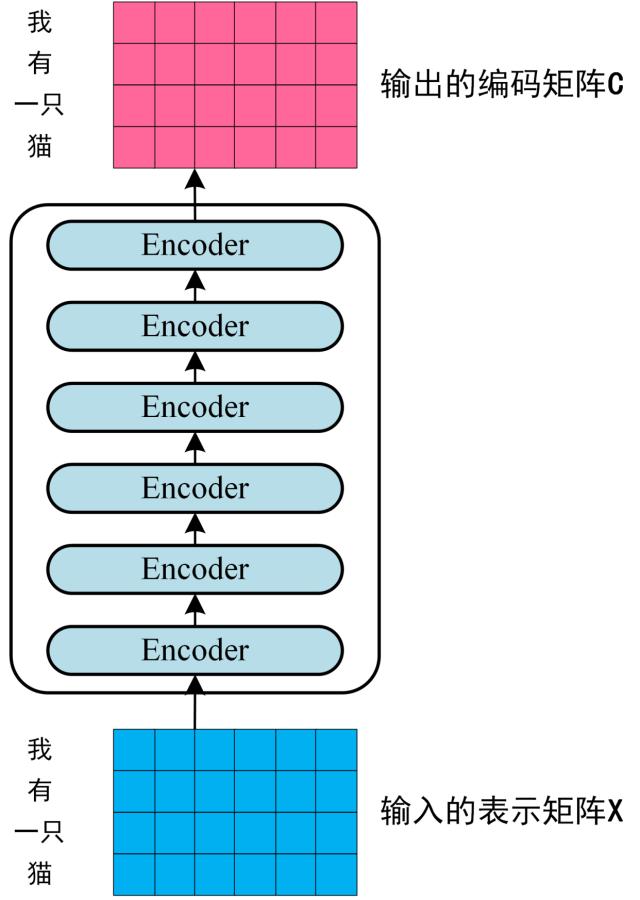
将得到的单词表示向量矩阵传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 $C$。
-
将 Encoder 输出的编码信息矩阵 $C$ 传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 $1 \sim i$ 翻译下一个单词 $i+1$。在使用的过程中,翻译到单词 $i+1$ 的时候需要通过 Mask (掩盖) 操作遮盖住 $i+1$ 之后的单词。
Self-Attention
帮助 Encoder 在对特定单词进行编码时照顾到输入的句子中的其他单词。
结构
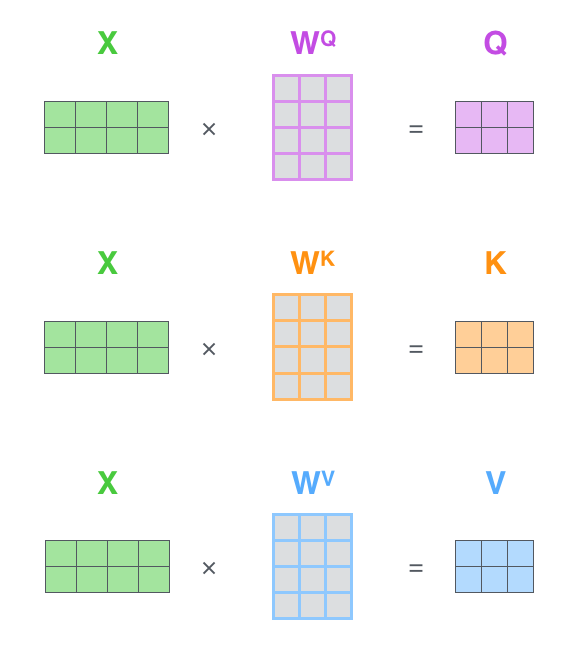
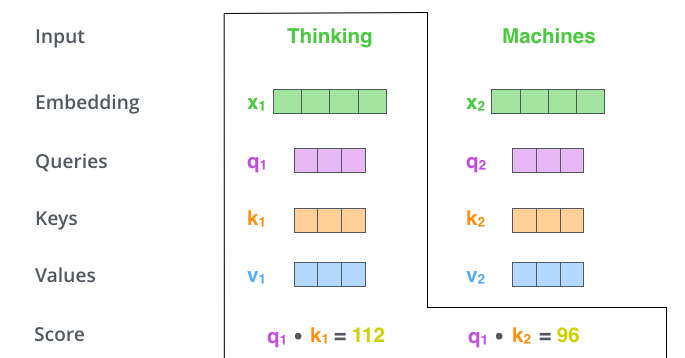
矩阵 $Q$(查询),$K$(键值), $V$(值)。
Self-Attention 接收的是输入(单词的表示向量 $x$ 组成的矩阵 $X$) 或者上一个 Encoder block 的输出。
而 $Q, K, V$ 正是通过 Self-Attention 的输入进行线性变换得到的。
Q, K, V 的计算
Self-Attention 的输入用矩阵 $X$ 进行表示,则可以使用线性变阵矩阵 $W^{Q}, W^{K}, W^{V}$ 计算得到 $Q, K, V$。
Self-Attention 的输出
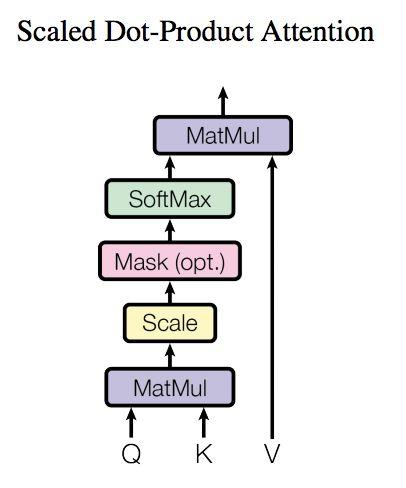
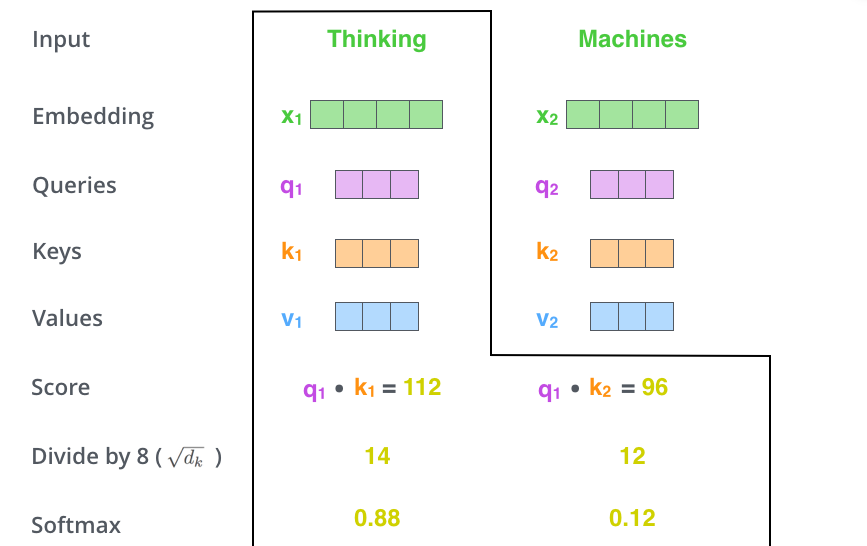
$\begin{aligned} &\text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d{k}}}\right) V\ &d{k} \text { 是 } Q \text { , } K \text { 矩阵的列数,即向量维度 } \end{aligned}$
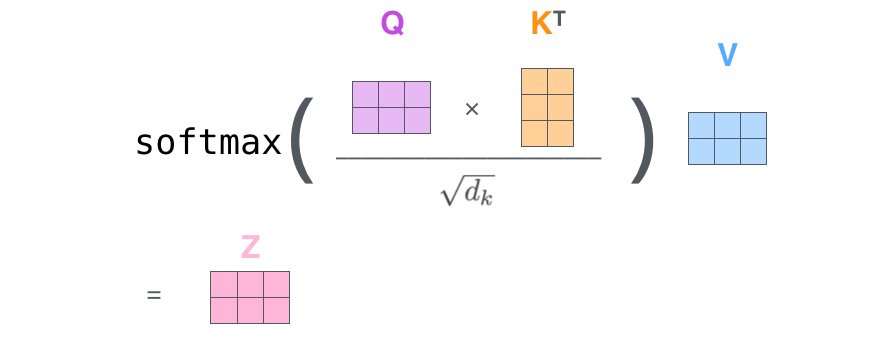
- $Q$ 乘以 $K$ 的转置(计算注意力得分,这个分数决定了在编码某个位置上的单词时,对其他单词的关注程度)
- 使用 Softmax 计算每一个单词对于其他单词的 attention 系数
- 得到 Softmax 矩阵之后和 $V$ 相乘,得到最终的输出 $Z$(尽量保持想要关注的单词的 value 值不变,而掩盖掉那些不相关的单词(将它们乘以很小的数字))。SoftMax 矩阵的第 $1$ 行表示单词 $1$ 与其他所有单词的 attention 系数,最终单词 $1$ 的输出 $Z{1}$ 等于所有单词 $i$ 的值 $V{i}$ 根据 attention 系数的比例加在一起得到。
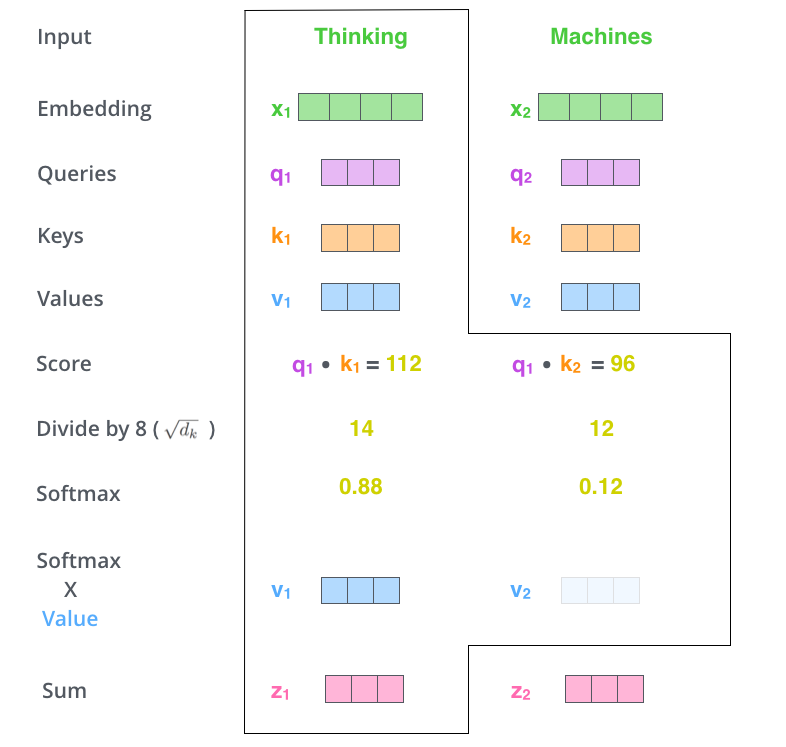
Self-Attention 的输出被输入到前馈神经网络。
完全相同的前馈网络分别应用于各个 Encoder block 中。
Multi-Head Attention
Multi-Head Attention 是由多个 Self-Attention 组合形成的。
结构
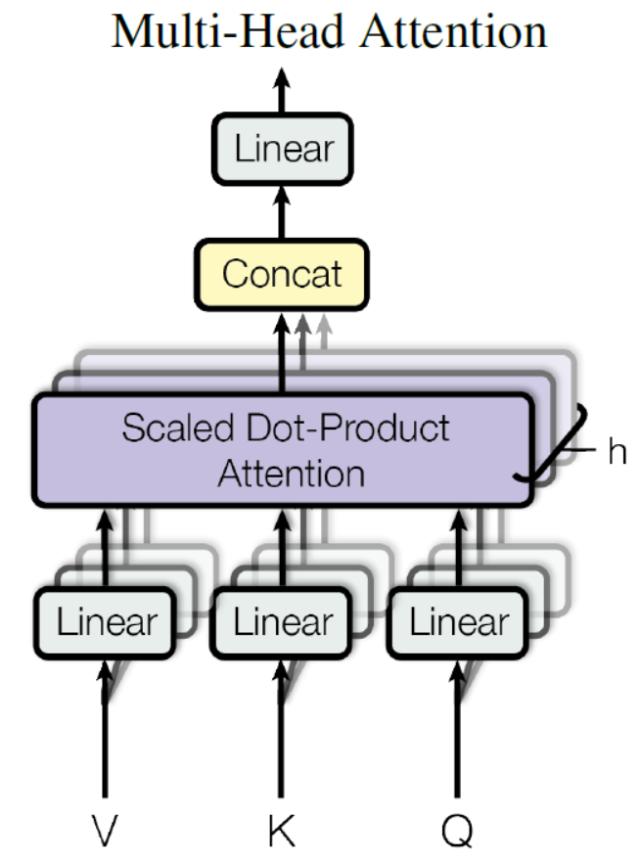
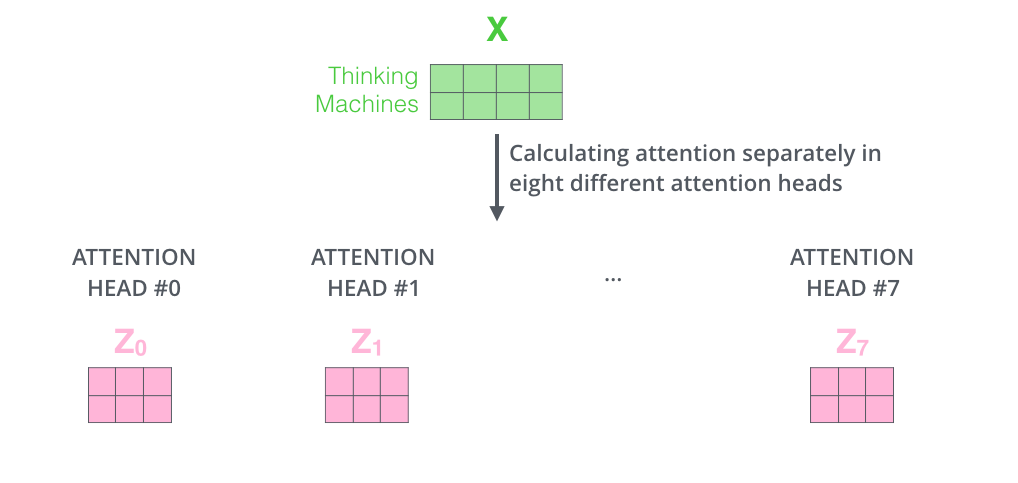
将输入 $X$ 分别传递到 $h$ 个不同的 Self-Attention 中,计算得到 $h$ 个输出矩阵 $Z$
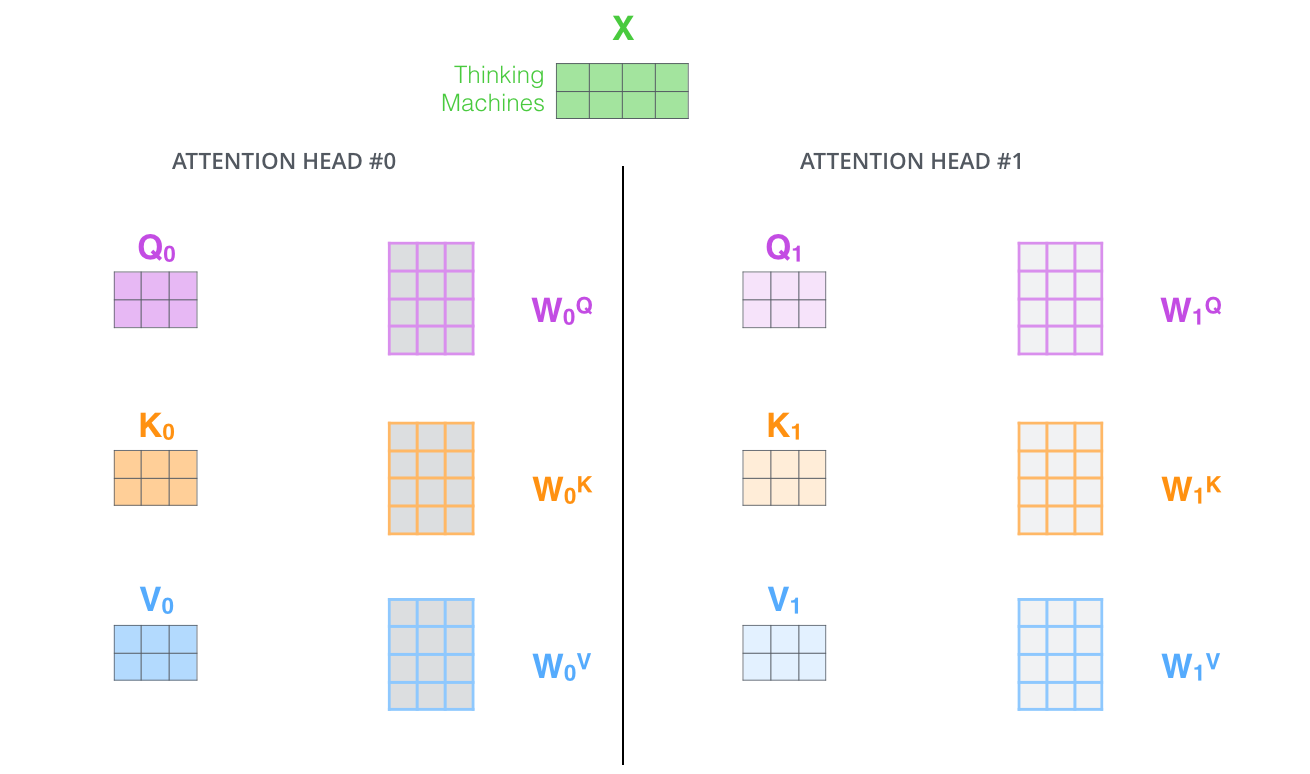
e.g. h = 8
- 用不同的权重矩阵做8次不同的计算,得到 8 个输出矩阵 $Z$
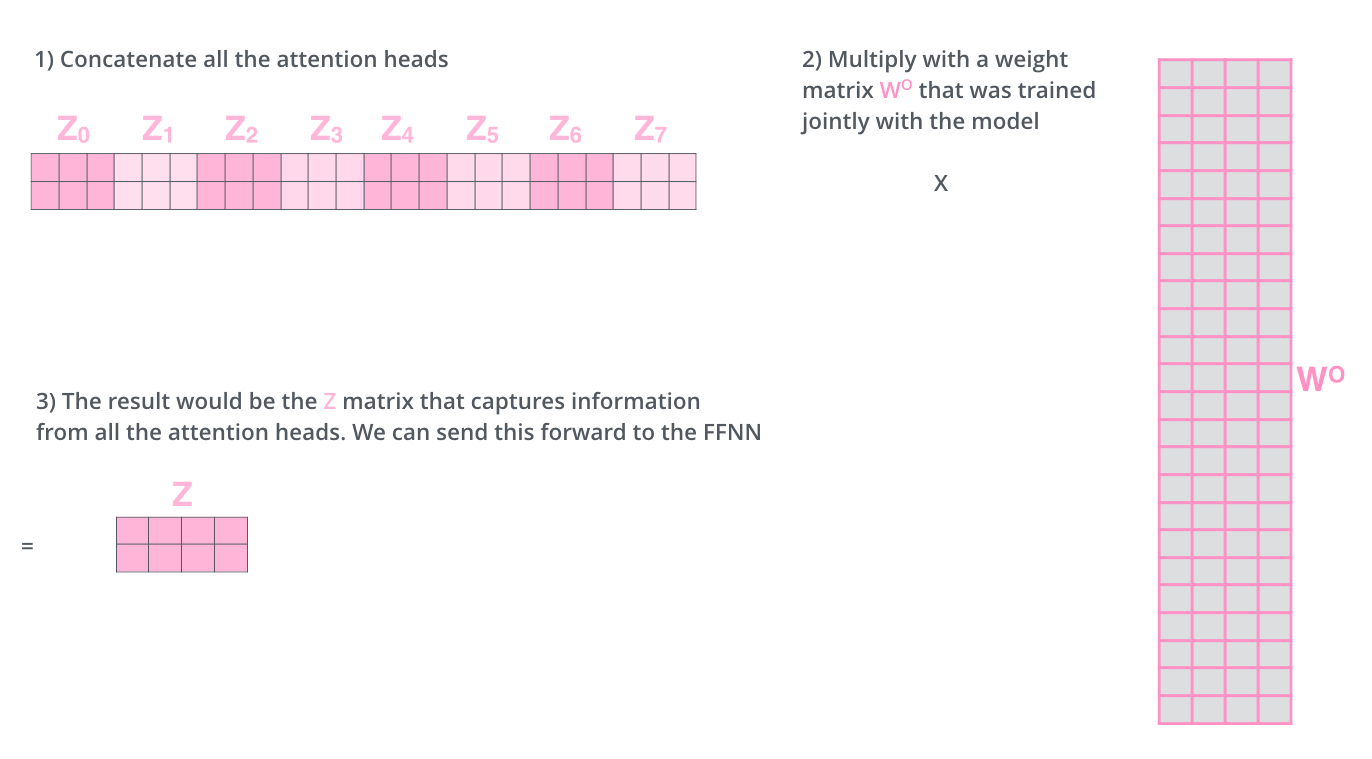
- 得到 8 个输出矩阵 $Z{0}$ 到 $Z{7}$ 之后,Multi-Head Attention 将它们拼接在一起 (concat),然后传入一个 Linear 层,得到 Multi-Head Attention 最终的输出 $Z$。
Add & Norm
Add & Norm 层由 Add 和 Norm 两部分组成:
LayerNorm $(X+$ MultiHeadAttention $(X))$ LayerNorm $(X+$ FeedForward $(X))$
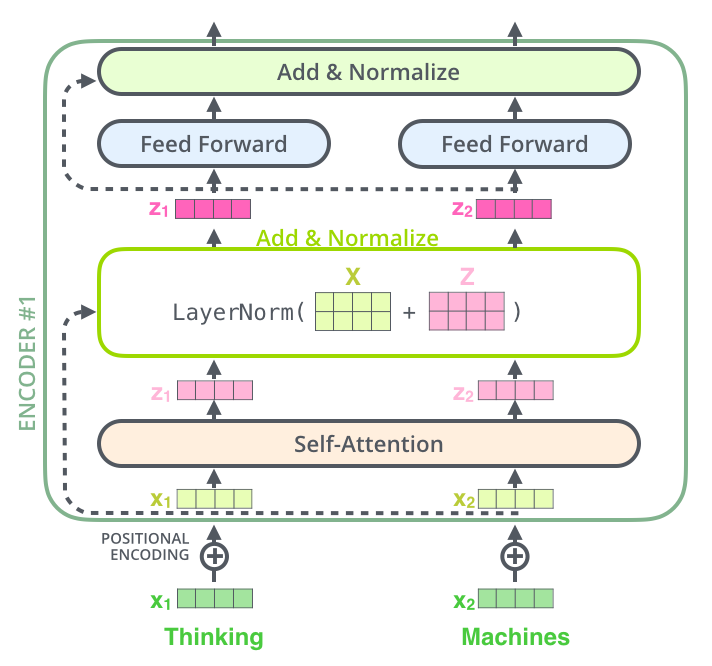
Add

$X$ + Multi-Head Attention($X$),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到。
Norm
Norm 指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
Feed Forward
Feed Forward 层是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数。
$\max \left(0, X W{1}+b{1}\right) W{2}+b{2}$
组成 Encoder
Multi-Head Attention, Feed Forward, Add & Norm 就可以构造出一个 Encoder block,Encoder block 接收输入矩阵 $X$,并输出一个矩阵 $O$。通过多个 Encoder block 叠加就可以组成 Encoder。
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是 编码信息矩阵 $C$,这一矩阵后续会用到 Decoder 中。
组成 Decoder
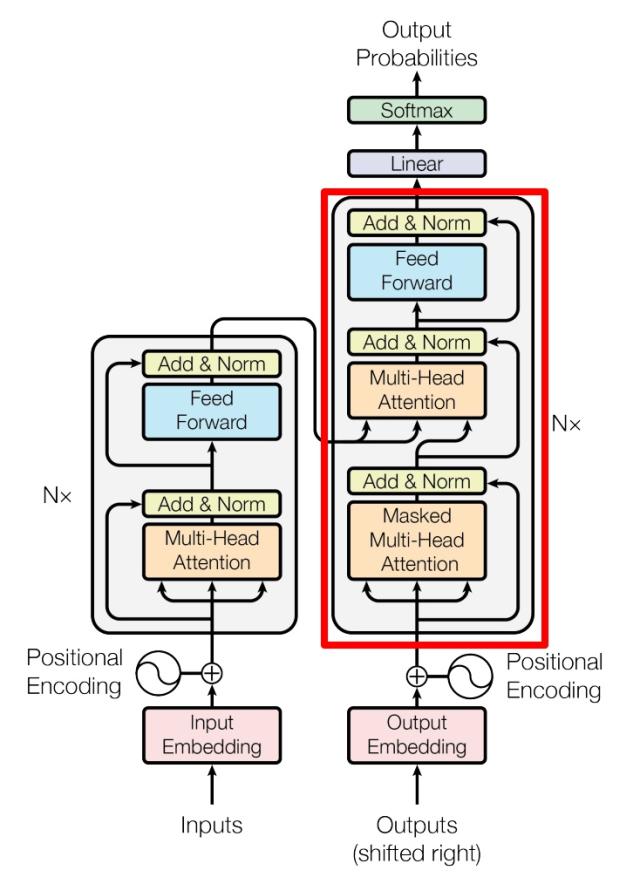
-
Decoder block 包含两个 Multi-Head Attention 层;
-
第一个 Multi-Head Attention 层采用了 Masked 操作;
-
第二个 Multi-Head Attention 层的 $K, V$ 矩阵使用 Encoder 的编码信息矩阵 $C$ 进行计算,而 $Q$ 使用上一个 Decoder block 的输出计算。
-
最后有一个 Softmax 层计算下一个翻译单词的概率。
第一个 Multi-Head Attention
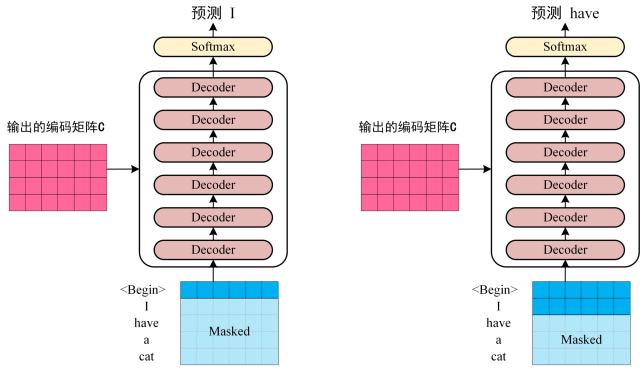
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 $i$ 个单词,才可以翻译第 $i+1$ 个单词。通过 Masked 操作可以防止第 $i$ 个单词知道 $i+1$ 个单词之后的信息。

-
Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 "
I have a cat" (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息 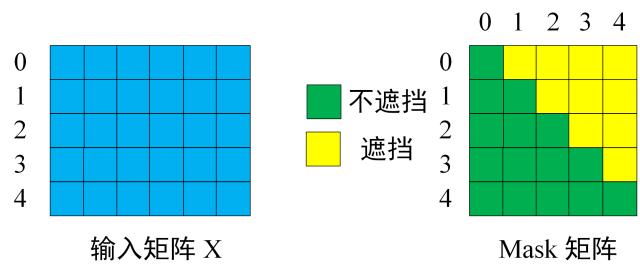
-
通过输入矩阵 $X$ 计算得到 $Q, K, V$ 矩阵。然后计算 ${Q K^{T}}$
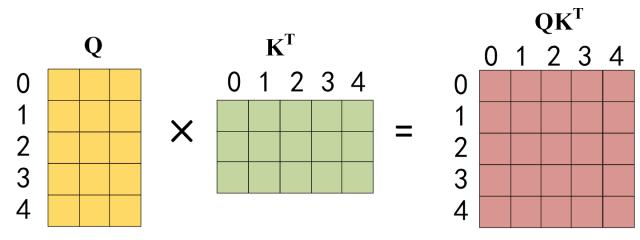
-
在得到 ${Q K^{T}}$ 之后需要进行 Softmax,计算 attention score,在 Softmax 之前需要使用 Mask 矩阵遮挡住每一个单词之后的信息
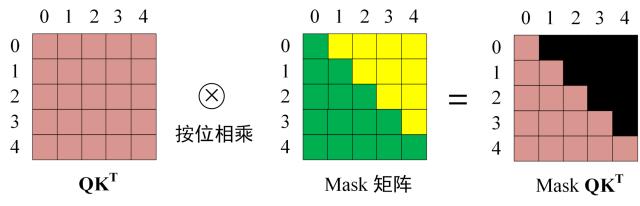
得到 Mask ${Q K^{T}}$ 之后在 Mask ${Q K^{T}}$ 上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
-
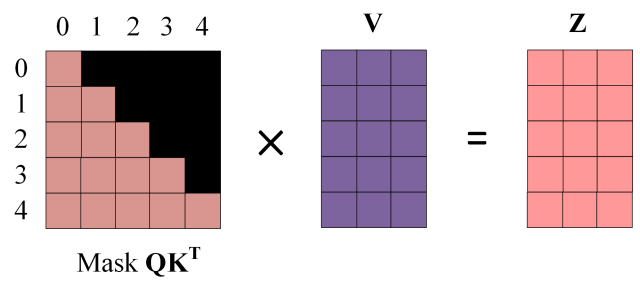
使用 Mask ${Q K^{T}}$ 与矩阵 $V$ 相乘,得到输出 $Z$,则单词 1 的输出向量 $Z_{1}$ 是只包含单词 1 信息的。
-
通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵 $Z{i}$,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出 $Z{i}$ 然后计算得到第一个 Multi-Head Attention 的输出 $Z$,$Z$ 与输入 $X$ 维度一样。
第二个 Multi-Head Attention
帮助 Decoder 将注意力集中在输入句子的相关部分。
其中 Self-Attention 的 $K, V$ 矩阵不是使用上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 $C$ 计算的。
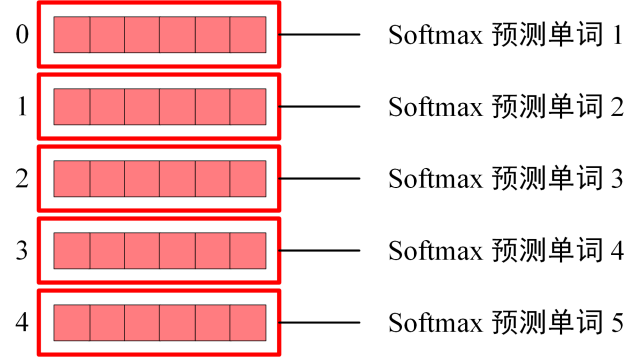
Softmax 预测输出单词
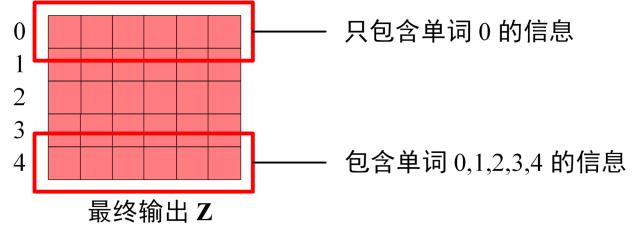
之前的网络层可以得到一个最终的输出 $Z$,因为 Mask 的存在,使得单词 0 的输出 $Z_{0}$ 只包含单词 0 的信息。
Softmax 根据输出矩阵的每一行预测下一个单词
多个 Decoder block 组合而成 Decoder。
paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding github: bert