 hui-po-wang
commented
6 years ago
hui-po-wang
commented
6 years ago @bearwbearw,
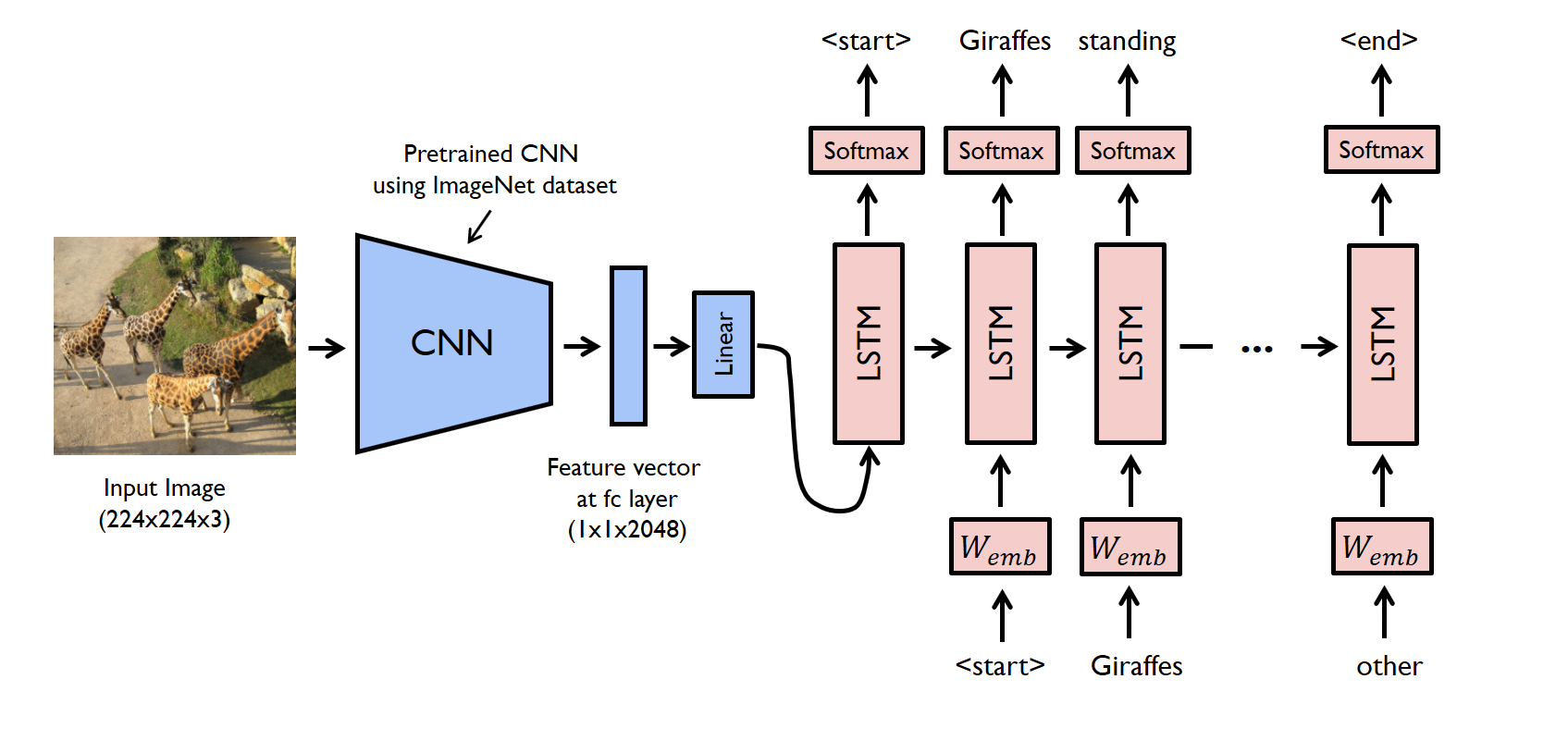
同上,caption的最後一個字
TA
Open bearwbearw opened 6 years ago
hui-po-wang
commented
6 years ago @bearwbearw,
同上,caption的最後一個字
TA
`class DecoderRNN(nn.Module):
助教你好, 這個 embeddings 的內容是 cnn 的 feature map + 字串, 所以有意義的資料長度應該是 1 + lengths
但執行了下面這, 帶入的長度是 length. 這樣不是字串的最後一個有意義的資料會被 truncate 掉? 'packed = pack_padded_sequence(embeddings, lengths, batch_first=True)`