Open 23784148 opened 5 years ago
阅读模式是让你专注阅读的必要手段,那么你认为「完美的阅读模式」该是什么样子?
我在做 简悦 的时候,偶尔会有些朋友这么说:「不就是 Safari 的阅读模式吗?」确实,阅读模式本身没什么,无非提取正文,显示而已。但如果深入下去,就不会这么理解了。从另外一个角度说,一般有这样想法的朋友大多不会经常使用阅读模式。也因此,只要是用过简悦的用户,大多会发出下面的感慨。
强如谷歌(翻译),也没办法完美的做好 中文 → 英文 这件事情。究其原因,语言是一件很个性化的事情,它可以翻译出较精准的书面语,但遇到口语,就很难尽如人意了。同样,文字也跟语言一样是很个性化的事情,虽然大多数的页面能保持良好的结构(书面语),但绝大多数页面却不仅如此。
为了解决这个问题,简悦寻求了一个更为简单直接的方式,即采用 手动适配 的方案。在初版发布后,确实收获了大量的种子用户。但随着简悦用户量的增大,手动适配的弊端就凸显了出来,如果某个小众的页面不支持简悦,但简悦的用户还想使用它,怎么办?
手动适配是一条正确的道路,但毕竟只是一条腿走路而已。基于上面的一些困扰,简悦增加了 词法分析引擎,即:结合手动识别分析的前提下,智能识别出未适配页面的正文。
包含 词法分析引擎 的版本推出后,果然在 Github issues 提新站请求的用户大幅降低了,这也就成了简悦的另一条腿。但其弊端也很凸显,也就是上文描述的情况:正文提取的不完美。
我认为通过算法不能解决所有的问题,决定仍旧采用手动的方式,在生成的阅读模式页面下,可以删除不需要(或认为有问题)的内容。通过移动鼠标 清除任意元素 这个简单操作,就能实现干净、完美的正文。
删除任意元素的前提是词法分析引擎正确解析了正文,但极端的情况下,正文获取失败怎么办?为了解决这个问题,又增加了 手动重新框选正文,万一正文的框选不如意怎么办?在此基础上配合 手动框选的精细调整,最终实现了手动重新获取正文的功能。
手动适配有个弊端,一旦适配的页面结构改变,就会出现适配错误的情况。简悦增加了 智能纠错 的功能,它会自动判断当前正文是否获取失败,一旦出现异常,它会自动使用词法分析引擎来重新获取正文。这样确保了:即便适配列表错误也能使用阅读模式。
最后,通过 手动适配(智能纠错) + 智能获取正文( 词法分析引擎 + 删除任意元素 + 重新高亮)这两种方式,终于实现了两条腿走路。
上面的功能只是解决了正文提取这件事情,但需要做的还远远不够。
页面布局有着丰富的形态,如:贴吧 / 知乎这类论坛类型页面、小说阅读类的前一页 / 后一页、含有大量代码的页面、纯文本类型的页面、包含 LaTeX 的页面等等。
为了「完美阅读模式」这件事情,简悦逐一解决了上面的问题。
支持 LaTeX 的解析
支持 论坛类页面支持解析 Markdown 文本
正如我在 这篇文章 所说,阅读是非常个性化的事情。同样,简悦也为这些具体化的阅读场景提供了不同的使用方案。
简悦为此提供了 导出到本地、导出到生产力工具 使其成为你的知识收集的一环。
借助 英文阅读时间 / 进度统计 全文翻译 可以实现英文阅读。
使用 代码段增强(高亮 / 去重) LaTeX 识别 Markdown 识别 可以让拥有代码段的页面更加的易于阅读。
简悦自 2017年 6月11日发布以来,得到了 4.9 的评分。
以及进入了 Chrome web store 「生产力工具热门精选」和「热门精选更新」两个榜单。
回到文中开始所问:「什么才是阅读模式该有的样子?」每个人心目中都有他认为完美的模样,简悦要做的就是:尽量成为你(用户)认为的样子。简悦做的还远远不够,但随着 1.1.3 版 的发布,在我心里它算是摸到了「完美阅读模式」的边了吧。 😊
阅读模式而已,有那么麻烦吗?
我在做 简悦 的时候,偶尔会有些朋友这么说:「不就是 Safari 的阅读模式吗?」确实,阅读模式本身没什么,无非提取正文,显示而已。但如果深入下去,就不会这么理解了。从另外一个角度说,一般有这样想法的朋友大多不会经常使用阅读模式。也因此,只要是用过简悦的用户,大多会发出下面的感慨。
阅读模式有那么难吗?
强如谷歌(翻译),也没办法完美的做好 中文 → 英文 这件事情。究其原因,语言是一件很个性化的事情,它可以翻译出较精准的书面语,但遇到口语,就很难尽如人意了。同样,文字也跟语言一样是很个性化的事情,虽然大多数的页面能保持良好的结构(书面语),但绝大多数页面却不仅如此。
简悦的做法
为了解决这个问题,简悦寻求了一个更为简单直接的方式,即采用 手动适配 的方案。在初版发布后,确实收获了大量的种子用户。但随着简悦用户量的增大,手动适配的弊端就凸显了出来,如果某个小众的页面不支持简悦,但简悦的用户还想使用它,怎么办?
简悦的升级
手动适配是一条正确的道路,但毕竟只是一条腿走路而已。基于上面的一些困扰,简悦增加了 词法分析引擎,即:结合手动识别分析的前提下,智能识别出未适配页面的正文。
词法分析的弊端
包含 词法分析引擎 的版本推出后,果然在 Github issues 提新站请求的用户大幅降低了,这也就成了简悦的另一条腿。但其弊端也很凸显,也就是上文描述的情况:正文提取的不完美。
清除任意元素
我认为通过算法不能解决所有的问题,决定仍旧采用手动的方式,在生成的阅读模式页面下,可以删除不需要(或认为有问题)的内容。通过移动鼠标 清除任意元素 这个简单操作,就能实现干净、完美的正文。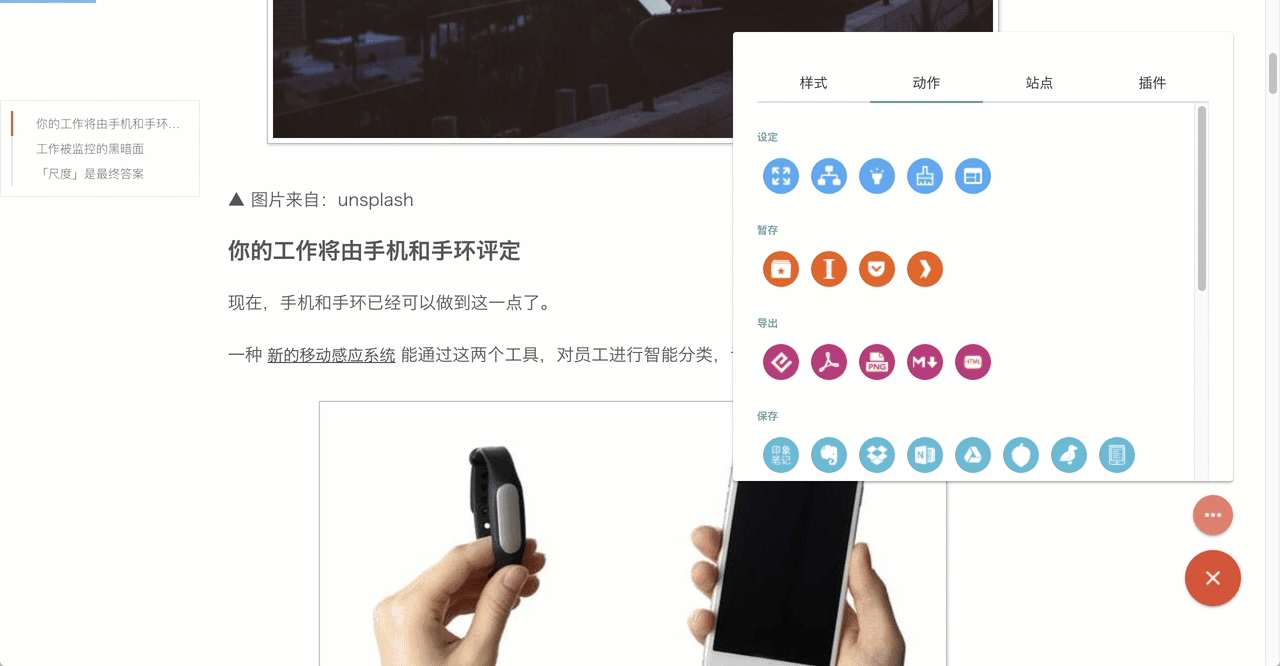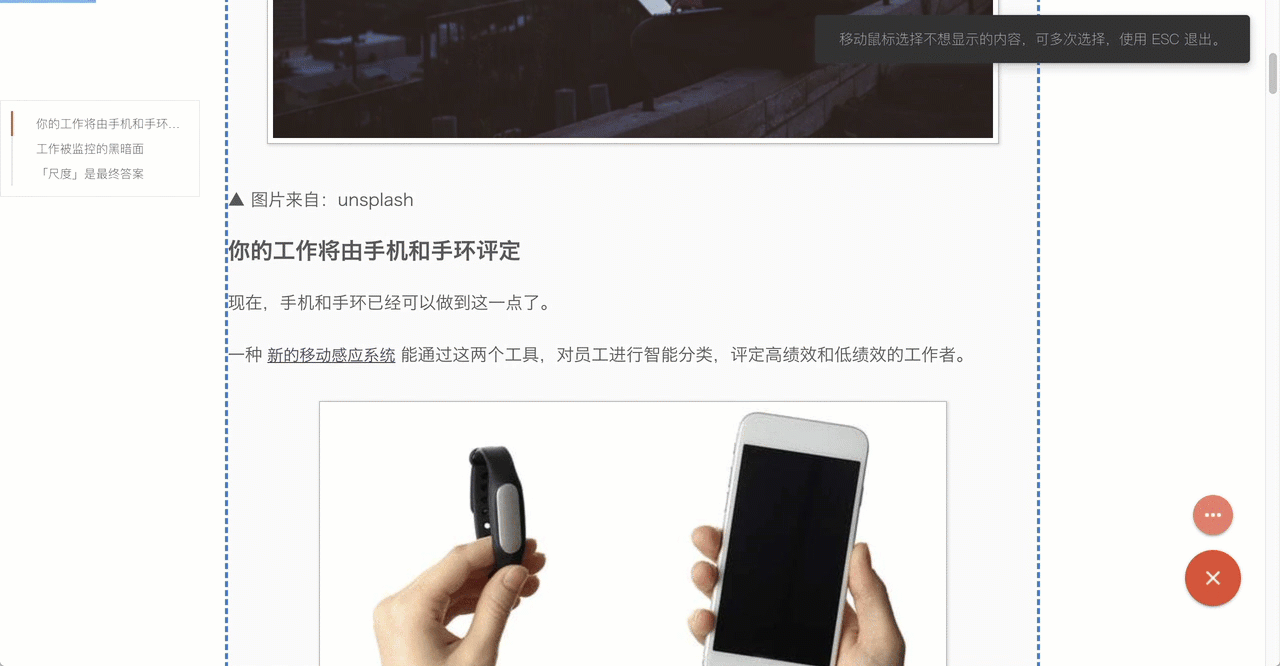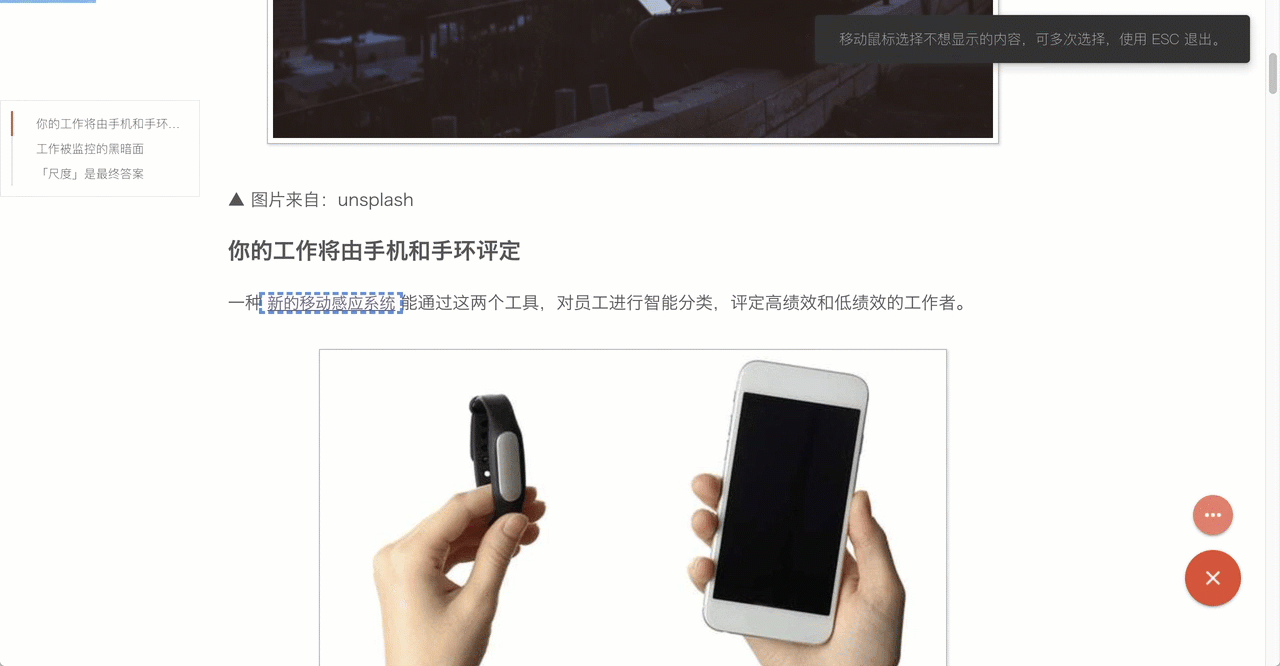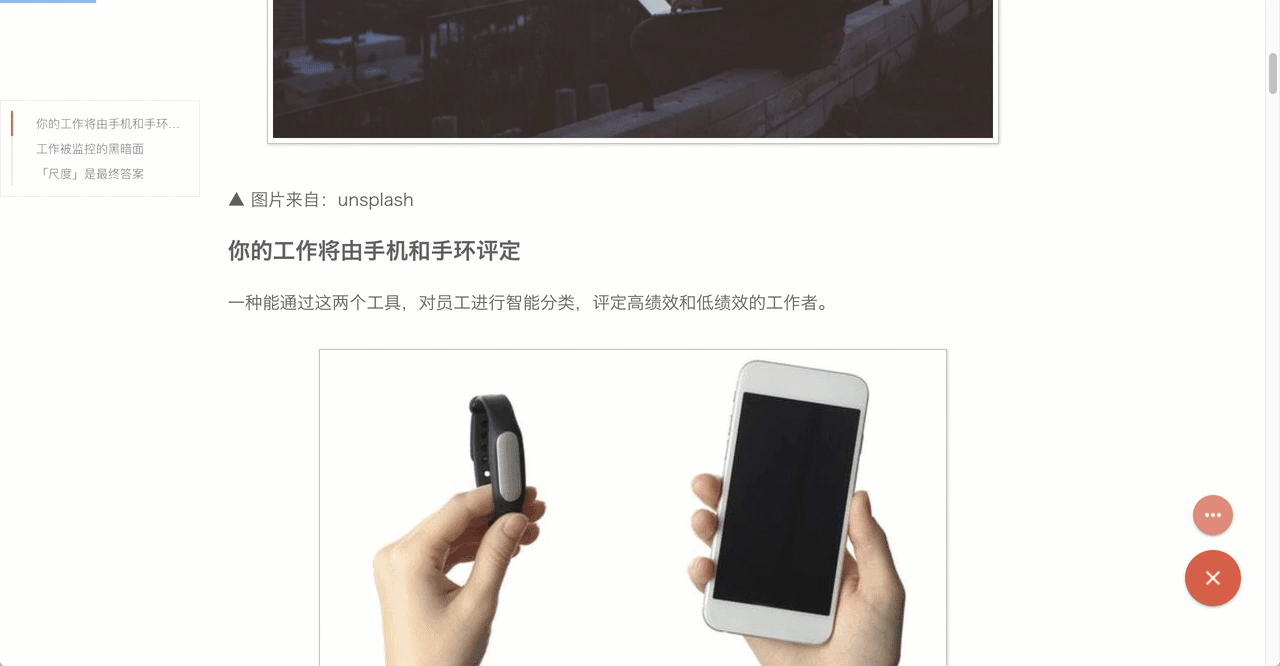
重新框选正文区域
删除任意元素的前提是词法分析引擎正确解析了正文,但极端的情况下,正文获取失败怎么办?为了解决这个问题,又增加了 手动重新框选正文,万一正文的框选不如意怎么办?在此基础上配合 手动框选的精细调整,最终实现了手动重新获取正文的功能。
智能纠错
手动适配有个弊端,一旦适配的页面结构改变,就会出现适配错误的情况。简悦增加了 智能纠错 的功能,它会自动判断当前正文是否获取失败,一旦出现异常,它会自动使用词法分析引擎来重新获取正文。这样确保了:即便适配列表错误也能使用阅读模式。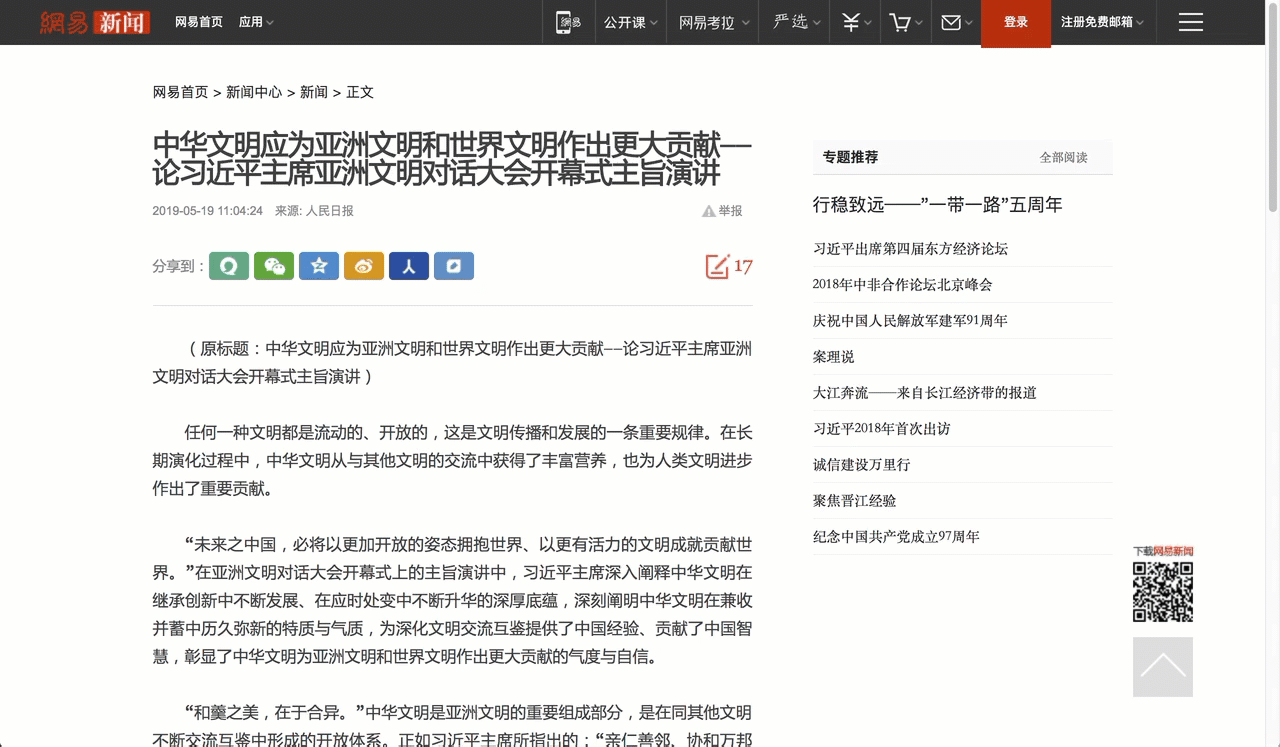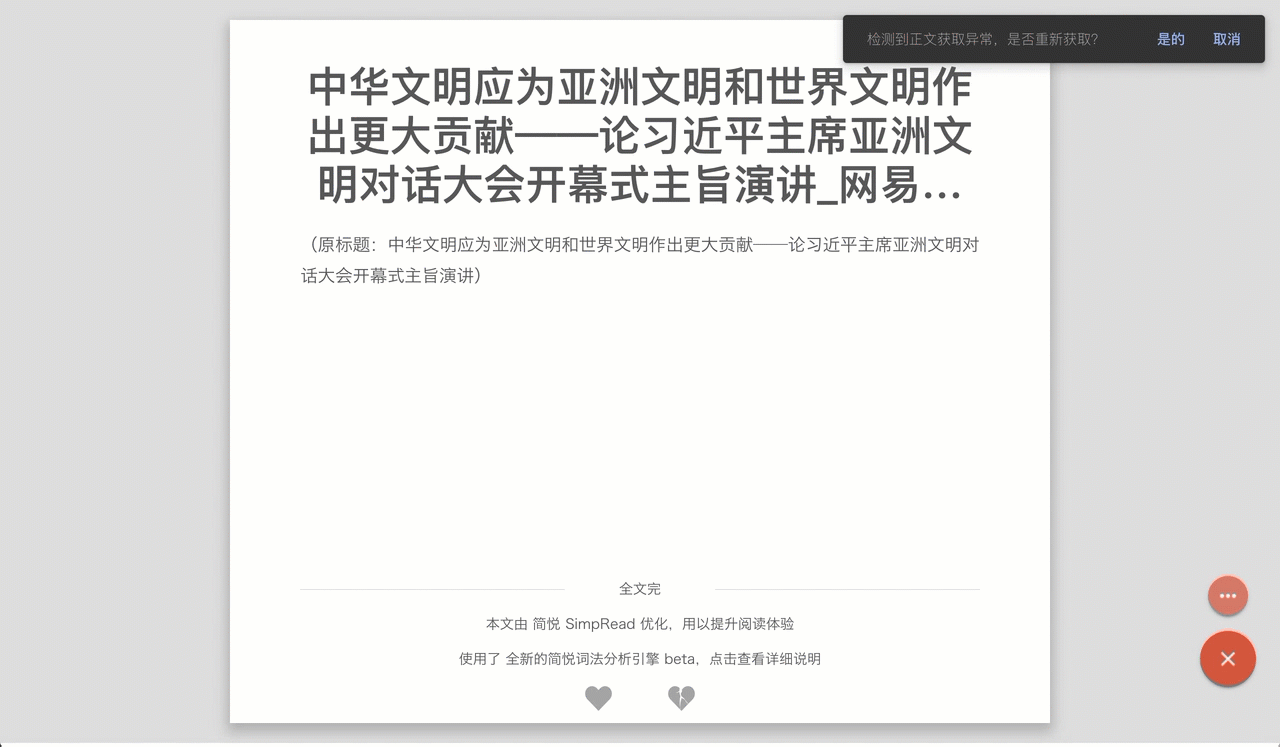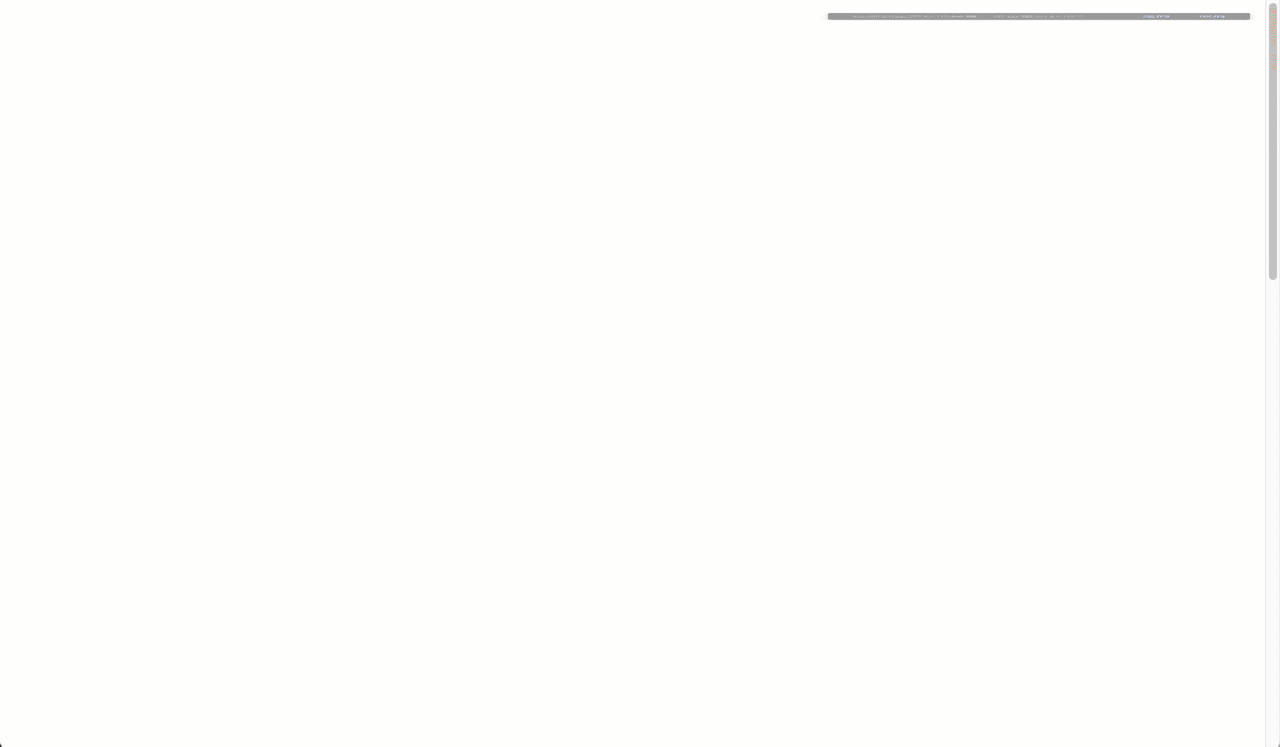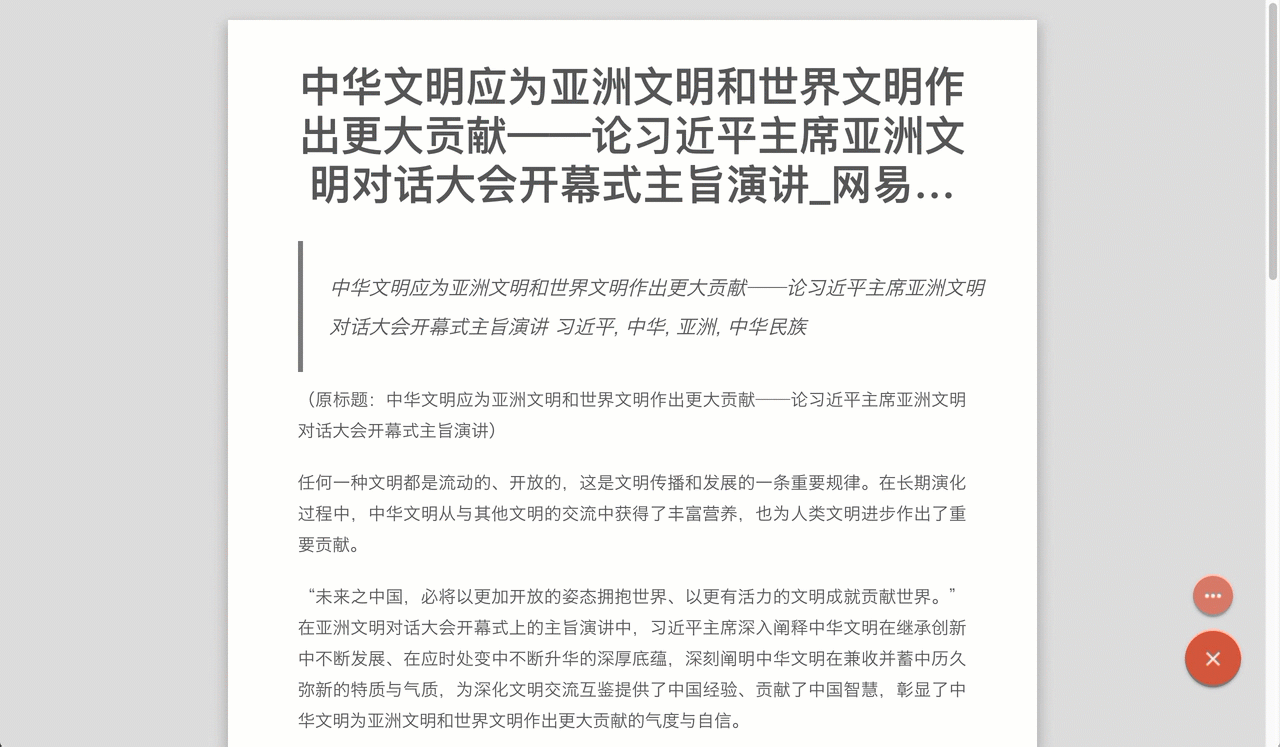
最后,通过 手动适配(智能纠错) + 智能获取正文( 词法分析引擎 + 删除任意元素 + 重新高亮)这两种方式,终于实现了两条腿走路。
丰富多样的阅读类型
上面的功能只是解决了正文提取这件事情,但需要做的还远远不够。
页面布局有着丰富的形态,如:贴吧 / 知乎这类论坛类型页面、小说阅读类的前一页 / 后一页、含有大量代码的页面、纯文本类型的页面、包含 LaTeX 的页面等等。
为了「完美阅读模式」这件事情,简悦逐一解决了上面的问题。
丰富多样的阅读场景
正如我在 这篇文章 所说,阅读是非常个性化的事情。同样,简悦也为这些具体化的阅读场景提供了不同的使用方案。
知识化的阅读场景
简悦为此提供了 导出到本地、导出到生产力工具 使其成为你的知识收集的一环。
英文阅读
借助 英文阅读时间 / 进度统计 全文翻译 可以实现英文阅读。
代码类阅读
使用 代码段增强(高亮 / 去重) LaTeX 识别 Markdown 识别 可以让拥有代码段的页面更加的易于阅读。
你用着好,才是真的好
简悦自 2017年 6月11日发布以来,得到了 4.9 的评分。
以及进入了 Chrome web store 「生产力工具热门精选」和「热门精选更新」两个榜单。
最后
回到文中开始所问:「什么才是阅读模式该有的样子?」每个人心目中都有他认为完美的模样,简悦要做的就是:尽量成为你(用户)认为的样子。简悦做的还远远不够,但随着 1.1.3 版 的发布,在我心里它算是摸到了「完美阅读模式」的边了吧。 😊