 5Mi
commented
7 years ago
5Mi
commented
7 years ago /*
* 经典面试题
* 函数参数不定回调函数数目不定
* 编写函数实现:
* add(1,2,3,4,5)==15
* add(1,2)(3,4)(5)==15
*/
function add() {
// 第一次执行时,定义一个数组专门用来存储所有的参数
var _args = [].slice.call(arguments);
// 在内部声明一个函数,利用闭包的特性保存_args并收集所有的参数值
var adder = function () {
var _adder = function() {
[].push.apply(_args, [].slice.call(arguments));
return _adder;
};
// 利用隐式转换的特性,当最后执行时隐式转换,并计算最终的值返回
_adder.toString = function () {
return _args.reduce(function (a, b) {
return a + b;
});
}
return _adder;
}
return adder.apply(null, _args);
}
// 输出结果,可自由组合的参数
console.log(add(1, 2, 3, 4, 5)); // 15
console.log(add(1, 2, 3, 4)(5)); // 15
console.log(add(1)(2)(3)(4)(5)); // 15
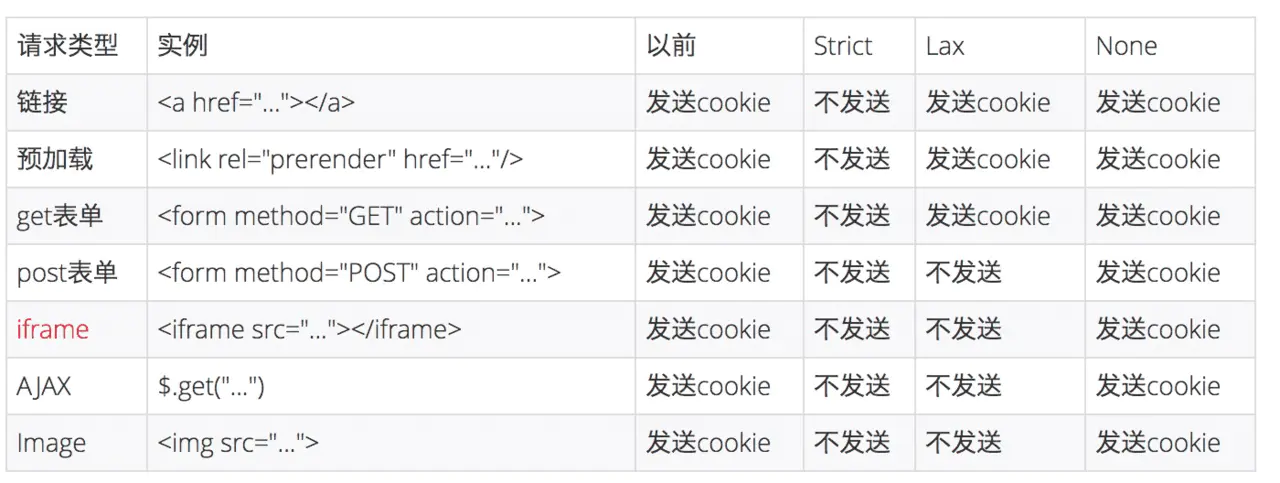



 有滚动
有滚动
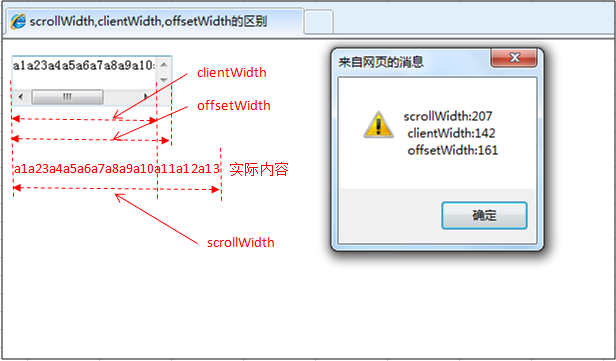
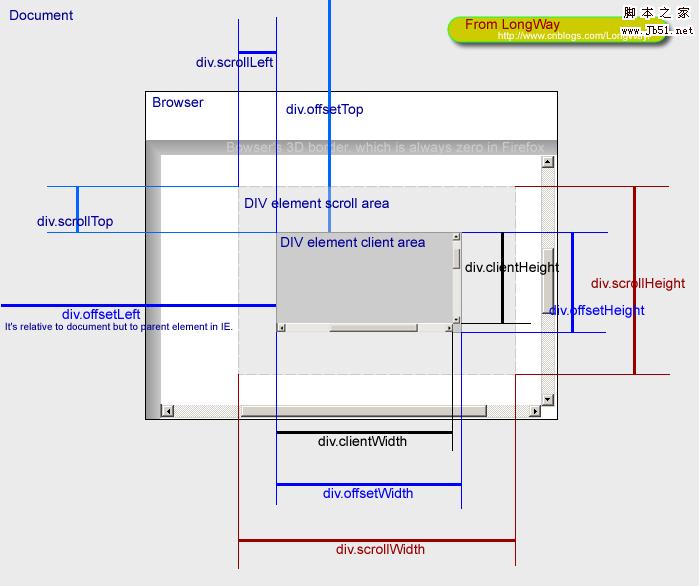
转自前端进阶
MS
ECMAScript中的所有参数传递的都是值,不可能通过引用传递参数。 被传递的值会被复制给一个局部变量(arguments)
js slice 与 splice
字符串回文与匹配 与乱序
javascript 中的
this引用的是函数据以执行的环境对象——或者也可以说是 this 值(当在网页的全局作用域中调用函数时, this 对象引用的就是 window)。运算符优先级表
优先级 高到低 同级不同运算从左到右 20 圆括号
19 成员访问
.19 需计算的成员访问
[]19
new(带参数列表 例: new...(...) )19 函数调用 例: ...(...)
18
new(无参数列表) 例: new ...17 后置自增,后置自减
a++a--...
(new foo 等同于 new foo(), 只能用在不传递任何参数的情况)
函数声明提升 和 变量声明提升
变量提升也有优先级, 函数声明 > arguments > 变量声明
函数作用域链包含两个对象:的作用域链包含两个对象:它自己的变量对象(其中 定义着 arguments 对象) 和 全局环境的变量对象。
作用域链是定死的,函数引用的变量在哪里定义,引用的就是哪里的变量.
function fn(){ console.log(a); var a = 5; console.log(a);
a++; var a; fn3(); fn2(); console.log(a);
}
function fn3(){ console.log(a) a = 200; }
fn(); console.log(a); //输出 //undefined //5 //1 //6 //20 //200
函数的隐式转换
对象通过valueOf方法,把自己转换成数字,通过toString方法,把自己转换成字符串
如果字符串和数字相加,JavaScript会自动把数字转换成字符的,不管数字在前还是字符串在前,字符串和数字相加结果是字符串
一个对象同时存在valueOf方法和toString方法,那么,valueOf方法总是会被优先调用的
参考
==与===与Object.is()获取页面用到哪些元素
document.getElementsByTagName('*');document.all能取得当前页面所有的element,判断nodeType===1就是element了,取nodeName就是标签名称js 中的
new访问属性对象
.与[][]中可以用变量this函数调用可等价转化为call形式;
数组去重
模拟call , apply函数
参考call,apply,bind
模拟实现
模拟bind函数
bind方法
返回类型