-
I was able to setup model and it works really great. My code is:
`private fun testAudio() {
// Initialize Whisper
val mWhisper = Whisper(this) // Create Whisper instance
// L…
-
- [x] Examples
- [x] Components used
-
I was testing the setup on mini librispeech data .This is log when I started training
```
# train.py -c conf/train.yaml data/simu/data/train_clean_5_ns2_beta2_500 data/simu/data/dev_clean_2_ns2_bet…
-
**Weekend Task**
- Research on theory behind Stable Diffusion
- List and research on the applications of Stable Diffusion
- Expand on the application.
- Which industry does this affect?
…
-
-
Amazon, Microsoft and Google are the leading solution providers in AI.
These are the solutions provided by these three,
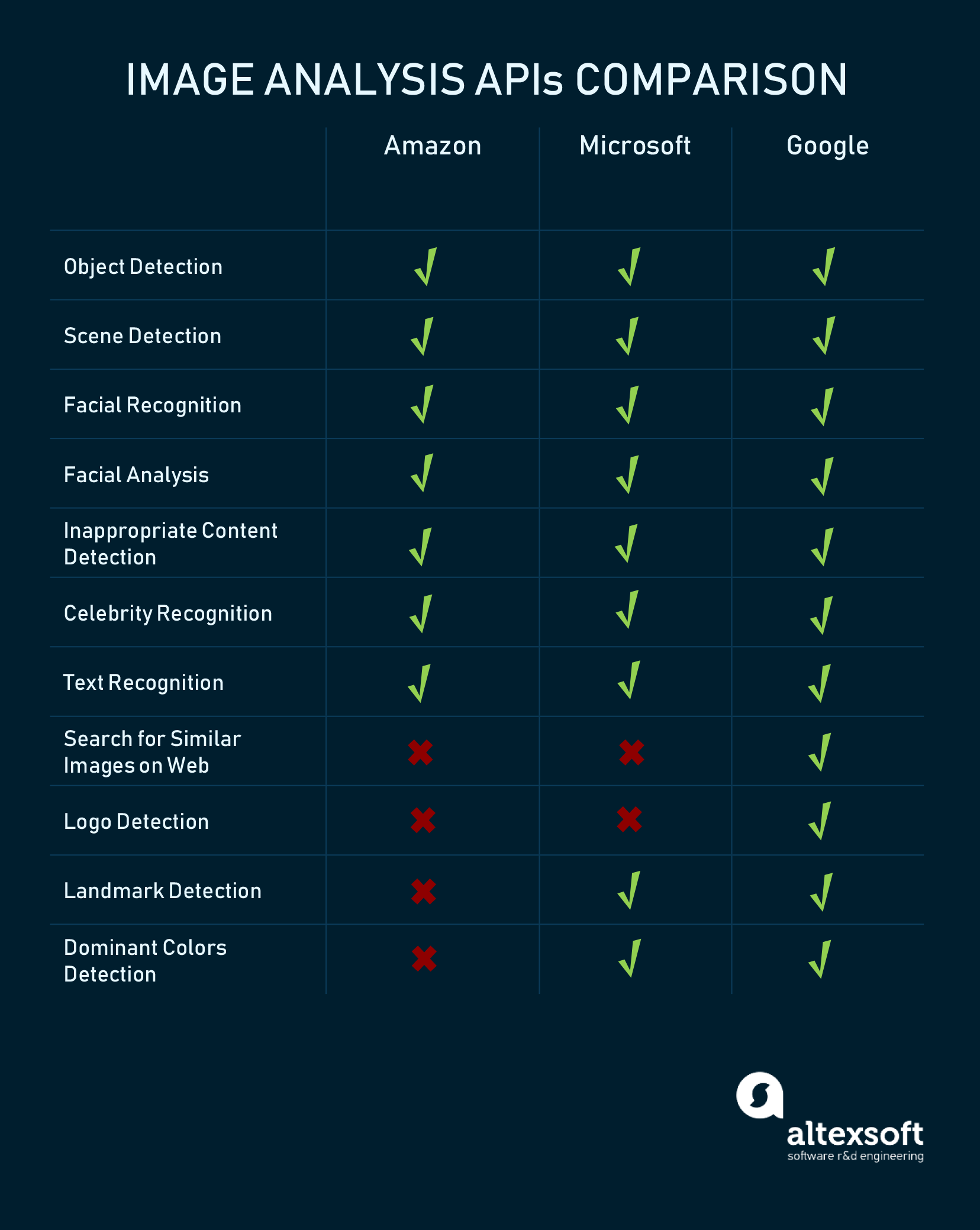
As y…
-
rtx3060 4G , speaking finish , text shows after 3-5 minutes what's wrong
-
**Reported by ragb on 2013-02-13 12:26**
This is kind of a spin-of of #279.
As settled some time ago, this proposal aims to implement automatic text “language” detection for NVDA. The main goal of t…
-
First, a disclaimer: Echogarden is being used as a dependency of another project ([Storyteller](https://gitlab.com/smoores/storyteller)) and Iʼm only 95% sure that the bug is entirely in Echogarden. …
-
Currently Willow uses only the intent part of the HA assist pipeline.
It would be nice if users could choose if they want to use the entire pipeline (so use the TTS and STT provided by the pipeline)…