-
Referring to line 76 of scripts/word_similarity/wordsim.py .
Getting the error: name 'geomm_utils' is not defined.
Is the code for geomm_utils available? Directly calling the functions without geom…
-
作者您好?可以分享PKU-500 dataset word similarity任务的人工打分数据集吗?在做中文相似度方面的研究,万分感谢!
-
To Do:
* . Use Stanford Contextualized Word Similarity
* Convert to tf_records using the existing dictionary so that the IDs match
* Split into validation and eval
Later:
* . Use ELMo eval m…
-
Here a list of related projects which might be interesting. Would be nice to read somewhere the similarities and differences of the projects.
- [Docear4Word](https://github.com/Docear/Docear4Word/) - …
-
## 0. Paper
@inproceedings{brandl-lassner-2019-times,
title = "Times Are Changing: Investigating the Pace of Language Change in Diachronic Word Embeddings",
author = "Brandl, Stephanie and…
a1da4 updated
3 years ago
-
## 0. Paper
@inproceedings{martinc-etal-2020-leveraging,
title = "Leveraging Contextual Embeddings for Detecting Diachronic Semantic Shift",
author = "Martinc, Matej and
Kralj Novak…
a1da4 updated
3 years ago
-
A floating idea that we will now be proceeding with.
The way I envision it at the moment (at least for some sort of MVP):
1. Store each word that is inserted into the braille display, into a wor…
nkdem updated
8 months ago
-
There are 10 similarity scores for each term – 1M for Idun and 1,5M for Ugglan. We can get them with this query:
```sql
SELECT
t1.term_term AS term1,
t2.term_term AS term2,
similarity
FR…
-
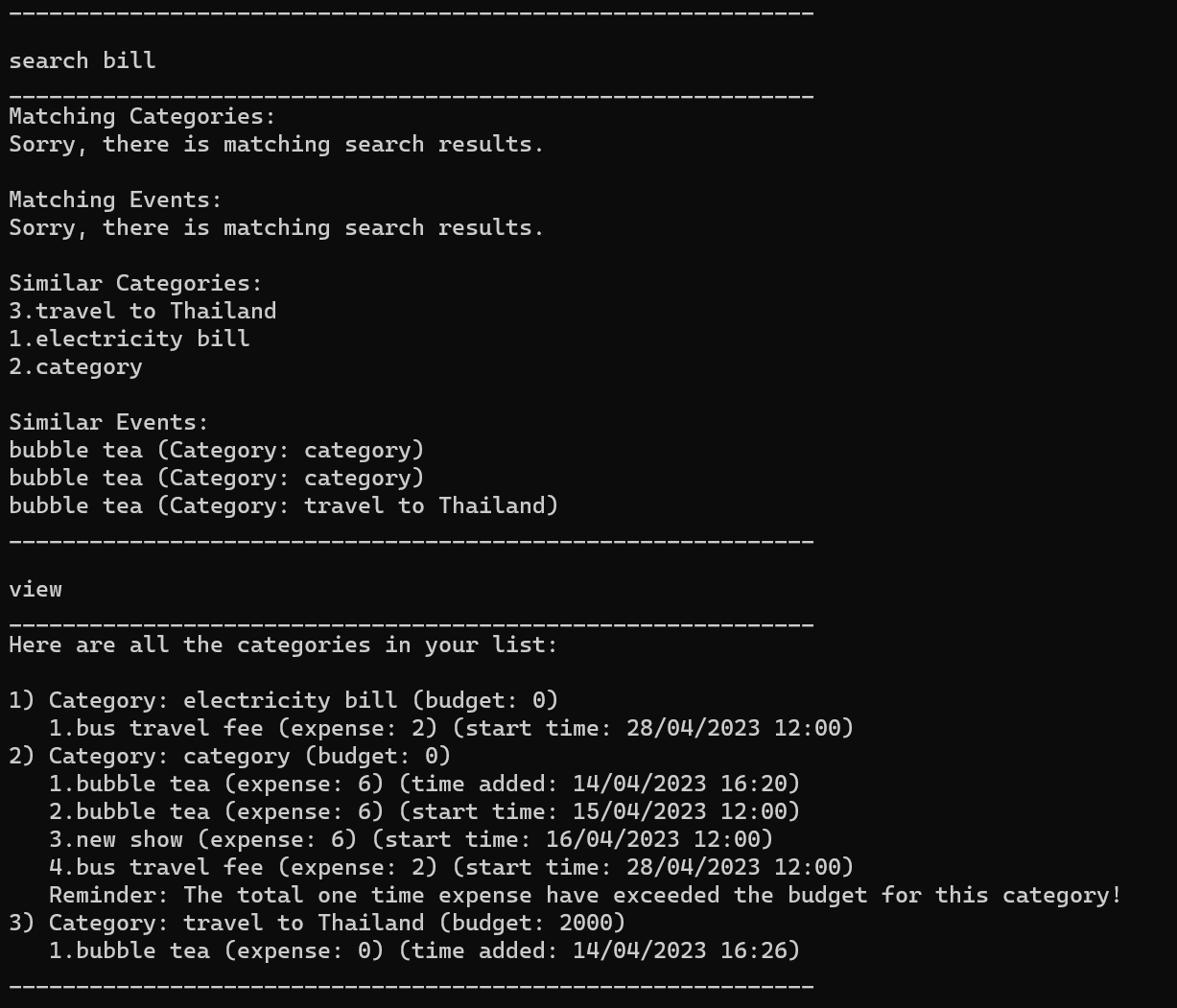
Search function has a feature showing similar category, but the similarity in the list is …
-
[Repository](https://github.com/knoxdw/nanogenmo2018), [text](https://raw.githubusercontent.com/knoxdw/nanogenmo2018/master/makeshift.txt), and [pdf](https://raw.githubusercontent.com/knoxdw/nanogenmo…