-
I have the exact same configuration for another domain, just swapping out the domain specific stuff. I get the following error when trying to run the indexer.
ERROR [GenericDocumentFetcher] Cannot…
-
Hello Pascal,
I'm struggling with a weird script filter issue.
Even the most trivial script filter just returning `true` results in a `REJECTED_IMPORT` when used as `postParseHandler`, where the…
-
[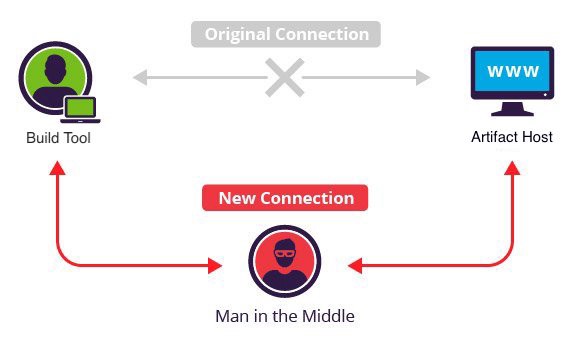](https://medium.com/@jonathan.leitschuh/want-to-take-over-the-java-ecosystem-all-yo…
-
Dear Sirs,
I am successfully crawling dozen websites with the 2.8.1 Collector-Http, successfully sending/committing contents to my Solr7.5.0 schema
But a (Italian) website always returns Connect…
-
Hi there,
I'm trying to change the content that will be committed based on the contentType.
That means, I'm trying to submit the "description"-Field for PDF files, rather than the original content…
-
Hi,
From my main site http://www.test.com, i only need to crawl certain parts. So I configured like this:
```xml
https://www.test.com/deptA
https://www.test.com/deptD
``…
-
Hi,
I have several urls with this format. Is the hypen causing the issue? How do i get around it? I cannot change the url formats.
```
website_test: 2018-12-02 18:56:08 INFO - DOCUMENT_F…
-
Hi,
I want to import only certain data from the webpage which I am crawling. This data exists between the body tag of the HTML page
```xml
The ACME Business
Bangalore
www.acme.com
…
-
Hi, I want to suffix the value of one metadata field. I tried using com.norconex.importer.handler.transformer.impl.ReplaceTransformer in the preParseHandlers.
For ex. title="test" to get transform…
-
Hi ,
I am using HTTP collector and MYSQL committer along with document fetcher to crawl and index web pages. everything is working fine , however I have one requirement where I need to store start…