-
# 预览截图:
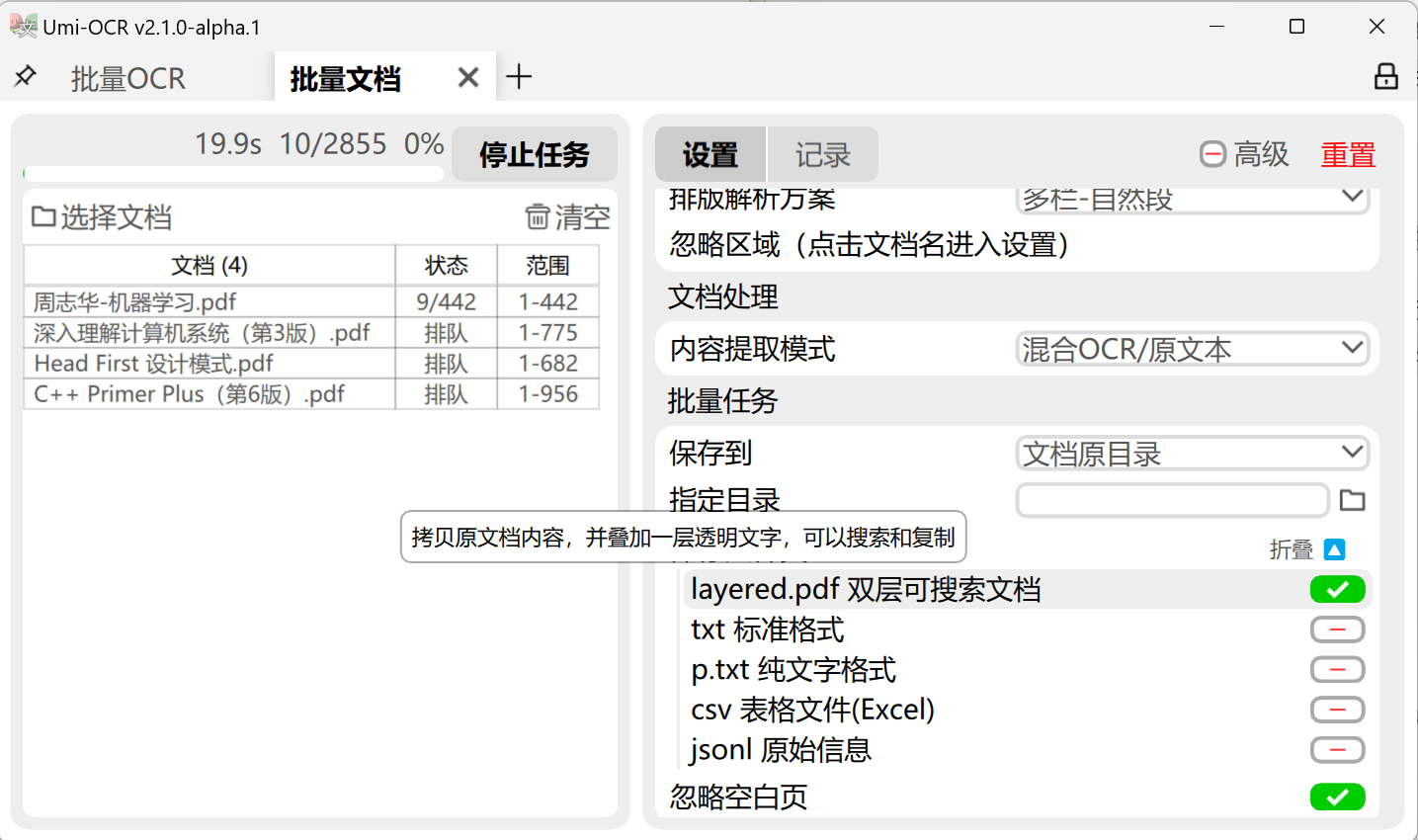
## 扫描件转为双层可搜索PDF 示例:

像上面这样,7zip发行压缩包在解压后丢失了PaddleOCR-js…
-
用这张图测试,旮旯二字只识出一个:
-

如上图,接口和软件中的不一样,我理解返回的数据应该是要处理,但是并不清楚具体的逻辑
-
https://github.com/hiroi-sora/Umi-OCR/issues/160
https://private-user-images.githubusercontent.com/56373419/246670568-8b4da183-d4f9-4f06-b39f-2fab85d37d80.png?jwt=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9…
-
识别的英文单词之间没有空格了怎么解决?
-

背景是批量的识别图片,用CLI,出现了这个错误
-
建议截图识别也可以保存结果到本地指定的文件
cukkk updated
5 months ago
-
-

生成后是0KB打不开,什么原因呢