-
编写了一个webui,增加了以下功能:
1. 选择音色;
2. 保存音色到本地;
3. 选择固定音色推理;
4. 调整推理参数;
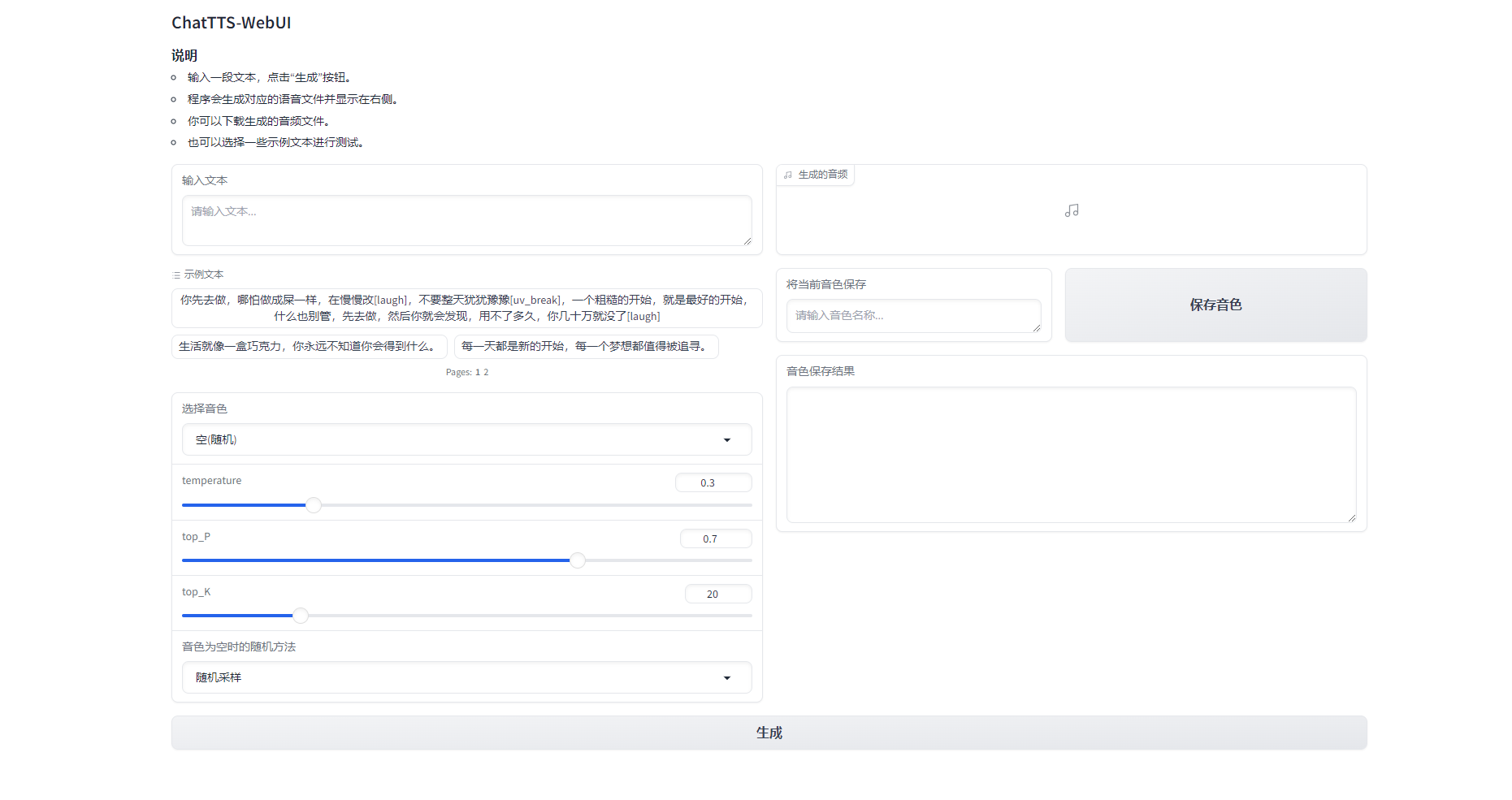
[ChatTTS_WebUI](https://github.com/craii/Cha…
craii updated
2 months ago
-
INFO:VideoTrans:配音加速 [117]
INFO:VideoTrans:配音加速 [118]
ERROR:VideoTrans:配音阶段出错:ffprobe error,:{ } ,
-
Model support must accommodate both inference and fine-tuning, with a higher priority on inference. Even if only inference is available, it should still be added to the TrainableModule.
1. Text-to-…
-
rt:May I ask how to fix the voice color?
请问:如何固定音色,或者有没有ChatTTS增强版的autodl镜像
-
**例行检查**
[//]: # '方框内填 x 表示打钩'
- [ x] 我已确认目前没有类似 features
- [x ] 我已确认我已升级到最新版本
- [ x] 我已完整查看过项目 README,已确定现有版本无法满足需求
- [x ] 我理解并愿意跟进此 features,协助测试和提供反馈
- [x] 我理解并认可上述内容,并理解项目维护者精力有限,**不遵循规则…
-
clmnt updated
2 months ago
-
现在是从pip install ChatTTS的话,会安装比较老的版本,方法参数接口都和测试代码不一致。
必须先从git clone到本地,在本地引用使用。
还有sample代码里应该提示需要pip install pyaudiofile,否则 torchaudio 会报no backend错误。
-
文本格式是markdown的或者其他形式,里面会存在一些特殊字符,如何自定义的过滤掉一些特殊字符
-
型号名称:MacBook Pro
芯片: Apple M1 Pro
核总数:8(6性能和2能效)
内存:16 GB
This problem appears after that branch "8235a46711ef738387ec17604a7e73f674930719"
-
```py
import ChatTTS
import torch
import torchaudio
chat = ChatTTS.Chat()
chat.load(compile=False) # Set to True for better performance
texts = ["语音太短了会造成生成音频错误, 这是占位占位, 老大爷觉得车夫的想法很有道理",
…