-
Hi,
I removed the GAN loss and only used the L1 loss to see the effect of training.
In this case, I remove the discriminator and its relevant optimizers and backpropagation functions.
However, wh…
-
Discriminator and Generator seem to have similar accurracy. We want the Discriminator to outpace the Generator, and therefore implement the Wasserstein Loss, because otherwise a better discriminator w…
-
Hi Shangyu,
Great work! I have some questions regarding the code as below
- new_meta_hidden_state_dict is empty [here](https://github.com/csyhhu/MetaQuant/blob/master/meta_utils/helpers.py#L13)?
…
-
I thought it might be better to discuss the sliding window in a separate issue.
https://github.com/kermitt2/delft/issues/44#issue-466195876
> I was just considering whether we need sliding windo…
-
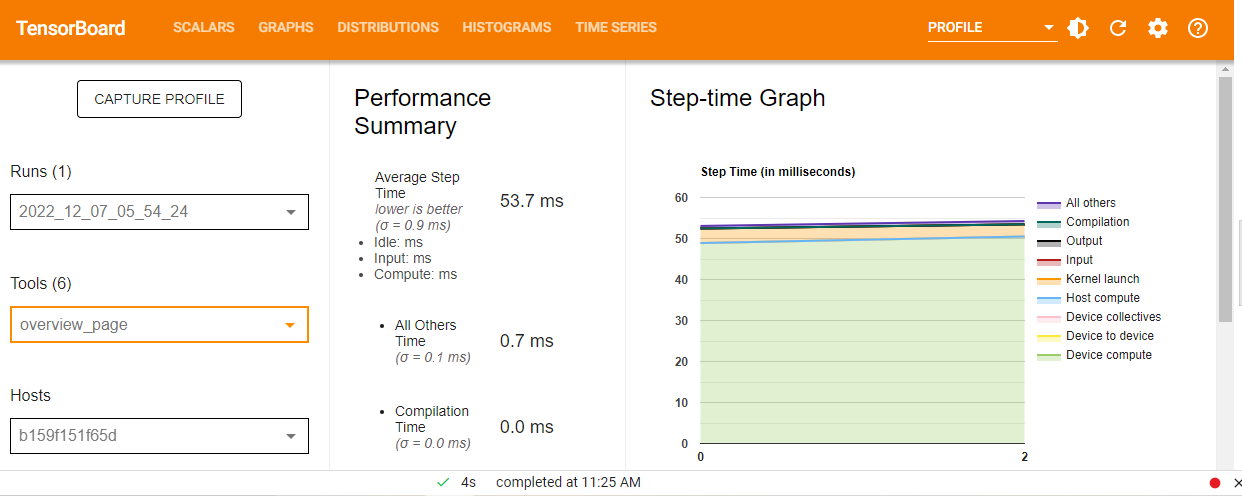
Hi all, I am trying to profile the following code , I am facing issues understanding …
-
Thanks for great work!
I would like to add a camera optimizer to optimize the camera pose during training. Specifically, I will introduce a learnable parameter `ext_emb_`(N * 6), translate it to SO3x…
-
Starting a new issue in reference to question: (https://github.com/astooke/Synkhronos/issues/11#issuecomment-326628646)
I have not experimented with running Synkhronos multi-node. Currently it's o…
-
## 一言でいうと
Transformerの演算を効率化する手法。Attentionの計算におけるQKではQに近いKだけ考慮される(=遠い所の計算は無駄)なので、ハッシュ関数を使ってソートしたうえでchunkに区切り、chunk内(似た者同士)/前chunk(接続)のみAttention計算を行う。またReversibleのResNetによる効率化も行っている。
