-
**Describe the bug**
(Following steps on https://docs.letta.com/server/docker#run-letta-server-with-docker)
1. Clone Repo
2. Create .env with OPENAI_API_KEY="sk-..."
3. docker compose up
4. v…
-
### Willingness to contribute
No. I cannot contribute this feature at this time.
### Proposal Summary
I would like MLFlow AI Gateway to add support for Gemini Foundational models
### Motivation
>…
-
I have tried a variety of models that support function calls, none of them gives the correct answer using LM Studio. Since it uses an 'API compatible with that of OpenAI it should accept the `tools` k…
-
### What is the issue?
When calling llava models from a REST client, setting temperature cause the ollama server hangs until process is killed.
### OS
Windows
### GPU
Nvidia
### CPU
AMD
### Ol…
-
Here's a rough idea of what I have so far:
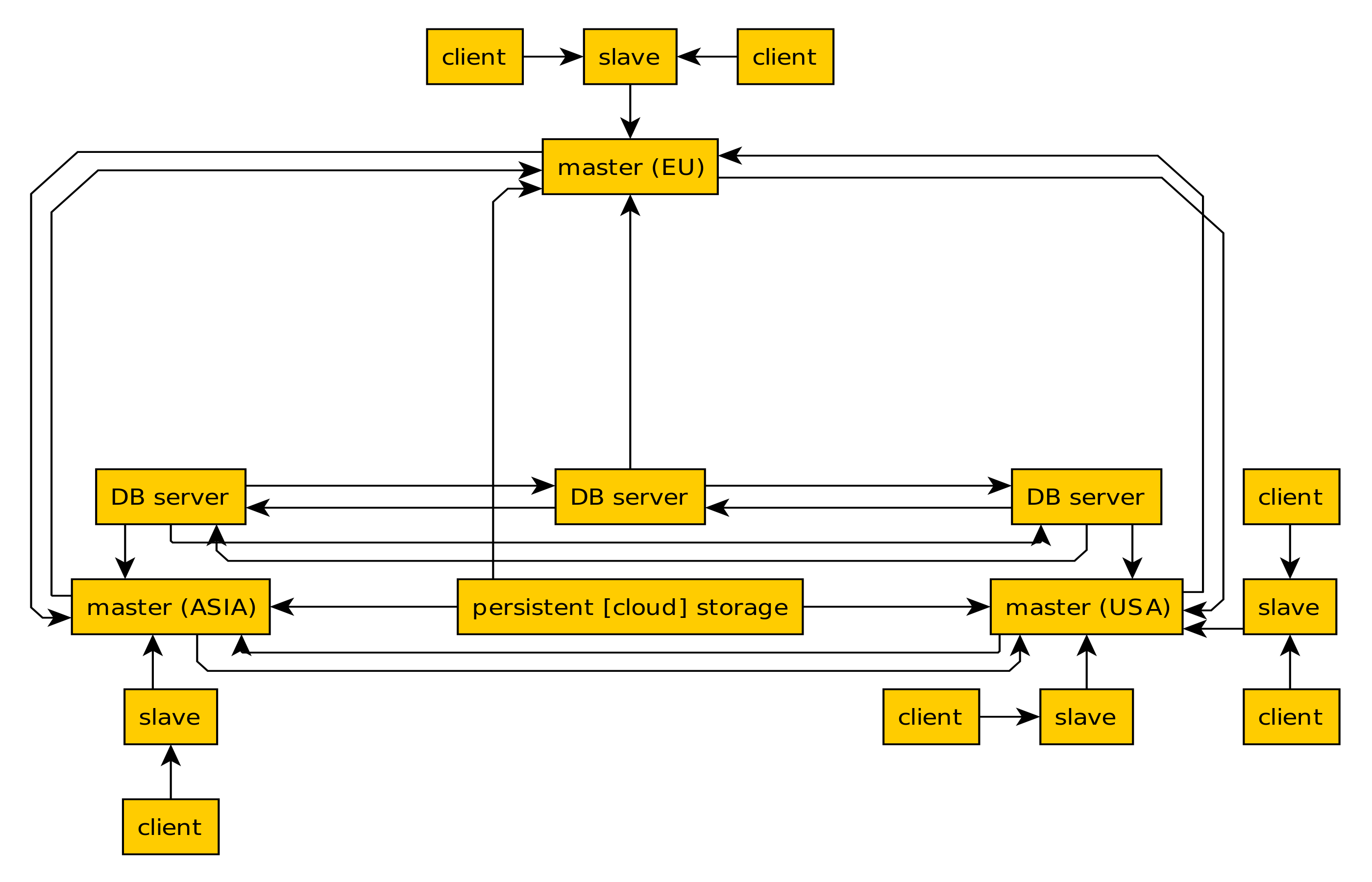
Sorry about the graph being messy and all. Anywa…
-
## Bug Description
I'm trying to serve torch-tensorrt optimized model to Nvidia Triton server based on the provided tutorial
https://pytorch.org/TensorRT/tutorials/serving_torch_tensorrt_with_t…
-
In `reverie/backend_server/persona/prompt_template/run_gpt_prompt.py`, multiple requests to OpenAI are made with a hardcoded model `gpt-35-turbo-0125`, which is currently not a valid/supported model o…
-
here is the the container parameters :
export DOCKER_IMAGE=intelanalytics/ipex-llm-inference-cpp-xpu:latest
export CONTAINER_NAME=ipex-llm-inference-cpp-xpu-container
podman run -itd \
…
-
It would be nice in the model service page, to be able to let the user access to the log of the server - which can be helpful for debugging.
-
Envoy supports sending the full request body to the external authorization server via the with_request_body filter configuration. Do you think that it is possible to expose such feature on the Securit…