-
### the issue
I modified the libritts example to use MFA alignment extracted durations to train a baker fastspeech2 model, it sounds much worse and noise than the tacotron2 extracted duration trained…
-
Hello! I am very impressed with your work, it provides me with many opportunities and I rely on it a lot. Some time ago I asked questions about solving some problems when training a model in Russian. …
-
Hi,
I am trying to fine-tune LJSpeech model (ljspeech_tts_train_conformer_fastspeech2_raw_phn_tacotron_g2p_en_no_space_train.loss.ave) on my dataset. I started the training with this command:
`.…
-
EoM
-
안녕하세요. fastspeech2로 한국어 tts구현을 시도해보고 있는 학생입니다. 좋은 코드 감사드립니다:)
mfa training에 있어 dictionary에 대해 궁금한 점이 있어 질문 드립니다.
1) dictionary에 존재하는 단어 조합 이 training corpus에 있는 단어조합 갯수를 커버하지 못하면 트레이닝 하는데 문제가 없…
-
Hello all! First of all, thanks for the great work - it is incredible! 🥇
I have contacted a friend who has a very great voice and we are able to do around 12h of studio recordings. I was thinking …
-
Hi @yuekaizhang :
From this issue https://github.com/espnet/espnet/issues/2537#issuecomment-703191762_
Can you provide the training time and how many GPU used for pre-training the conformer…
-
set "speaker = 3" in config.py
change fastspeech2_dataset.py as follow:
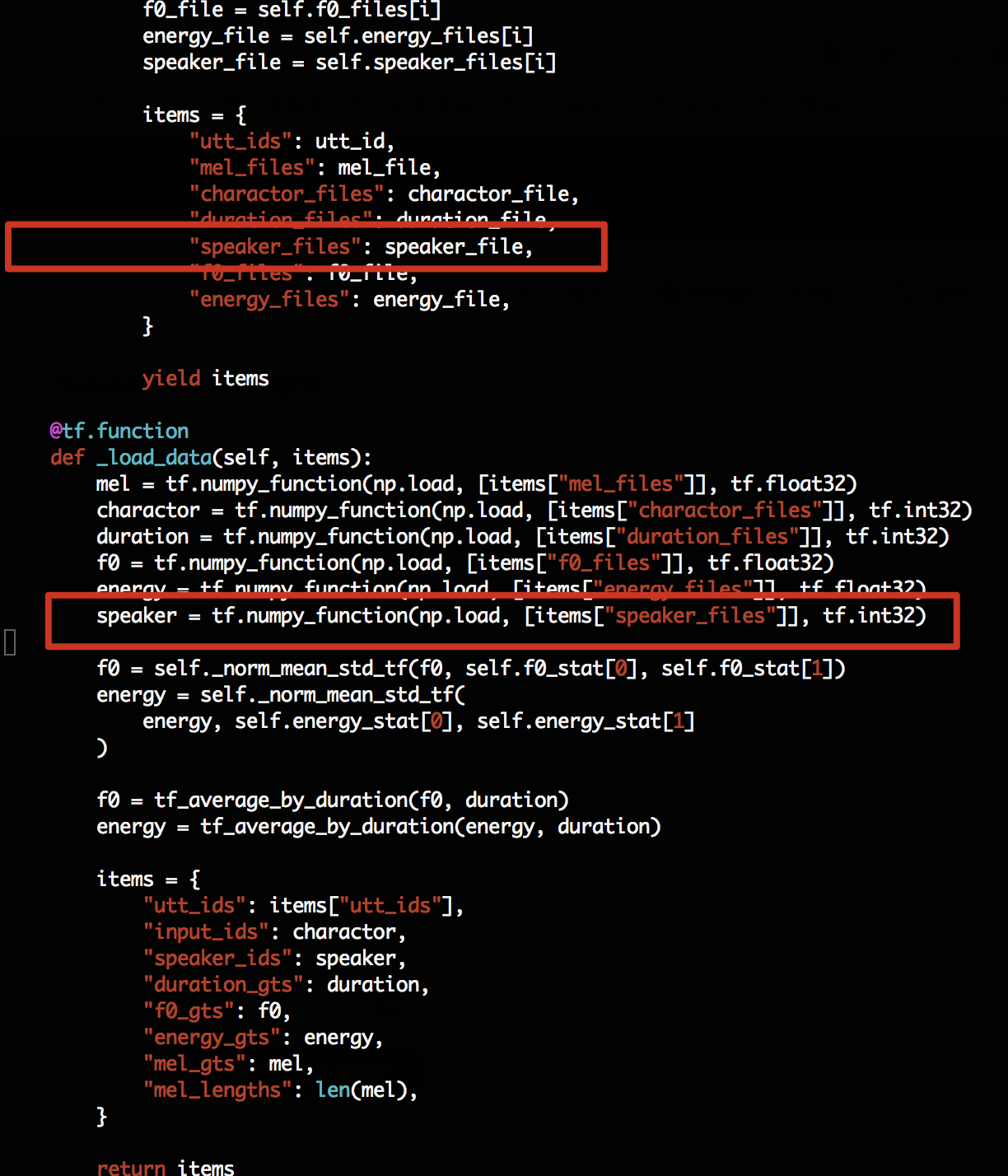
but got …
-
Hi~ Thanks for your contribution. It's a real meaningful work.
I trained a fastspeech2 model on own dataset for Chinese language.
I trained well on v2.yaml, but I couldn't converge good on v1.yaml,…
-
I just want to change dimension of mel-spectrum from 80 to 20 in tacotron2
so i change the value as n_mels = 20 in conf/tacotron2.v1.yaml
but i've got the error message
Exception has occurred…