-
**Environment:**
1. Framework: MXNET
2. Framework version: 1.4.1
3. Horovod version:
4. MPI version: 3.1.0
5. CUDA version: 10.0
6. NCCL version:
7. Python version: 3.6
8. OS and version: "Am…
-
**Environment:**
1. Framework: TensorFlow
2. Framework version: 1.13.1
3. Horovod version: not specified
4. MPI version: 3.1.0
5. CUDA version: 9.0
6. NCCL version:
7. Python version: 2.7
8. O…
-
Should be available from Apache Archive though, currently looking into in ec2_bootstrap.sh changing
http://apache.mirrors.lucidnetworks.net/spark/spark-2.2.1/spark-2.2.1-bin-hadoop2.7.tgz
into
…
-
[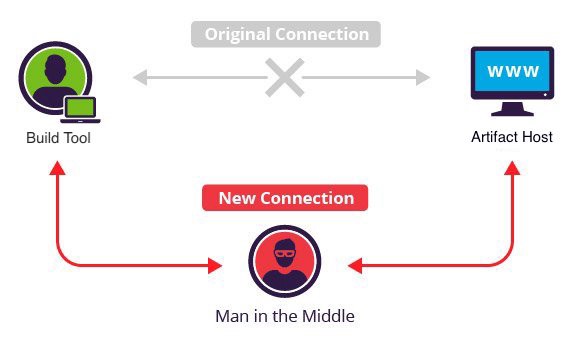](https://medium.com/@jonathan.leitschuh/want-to-take-over-the-java-ecosystem-all-yo…
-
we have the spark job server run together with the standalone spark cluster on one machine, which has 8 cores, 14G memory.
we tried to run jobs every 1 second against it, but after about 30 jobs, the…
-
Performing an update or a preview after a refresh causes an AWS EMR cluster to be replaced, even when there are no actual intended changes.
I have created a minimal reproduction case for this issue…
-
1. registered AWS account and created a user and generated access_id and secret_key and chose a region for "aws configure" command, I passed ec2 instance installation. It took time to get everything i…
-
I'm trying to do hyper-parameter tuning in scala, using GridCV. However I create my pipeline and everything, I fit my dataset to the pipeline, it fits properly.
Then I add some `paramGrid` and I go…
-
When I read a parquet file on s3 from sparklyr context like this:
spark_read_parquet(sc, name = "parquet_test", path = "s3a://"), it throws me an error which is:
Caused by: java.io.IOException: Cou…
-
Got error ImportError: No module named 'pyspark' when running python ch02/pyspark_mongodb.py
The other examples in chapter 2 ran fine.