-
With https://github.com/dotnet/runtime/issues/80814, we achieved functional parity of `Vector512` with `Vector128` and `Vector256`. However, there are some new instructions available in Avx512 capable…
-
Imo, we should publish a new release. The following have been added:
- #140: cw721-expiration: contract with expiration for NFTs
- #141: update libs
- #149: withdrawal address: contracts may have…
-
### System Info
- `transformers` version: 4.41.2
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.11.1
- Huggingface_hub version: 0.23.3
- Safetensors version: 0.4.3
- Accelerate versio…
-
When using multi-GPU via the `accelerate` scripts, performance is improved, however when doing multi-node-multi-GPU performance degrades below usability.
Benchmarks:
1. Single P4 GPU: 1.8 it/sec…
-
### Problem: 应该如何彻底解决下载问题?(i.e. P1&P2)
GitHub 文件加速下载[^1]、网盘直链解析[^2] 等类似的服务很难长期维持正常 + 保证下载速度。
那么,如何彻底解决P1[^1]、P2[^2] 就成了两大难题,因为不是所有用户都有 VPN,以及网盘手动下载的耐心。
诚心希望大家能够积极参与问题讨论,非常感谢。
---
### Problem: How…
-
tensorflow:1.4.0
python:3.6.9
-
Urls are checked using a loop that tests the response of the requests sequentially, which becomes slow for huge websites.
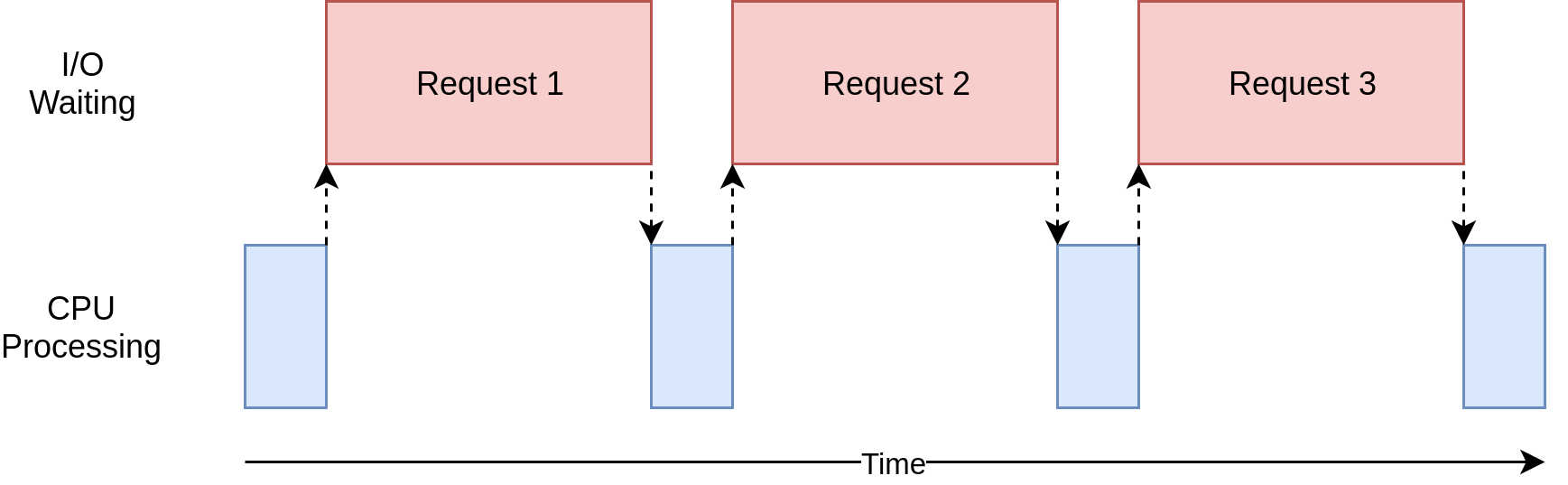
[Img sou…
-
First of all, congratulations for the script! It seems to work quite well in general.
I found a couple of small problems, this is one of them as you can see in the video:
https://vimeo.com/131253387
-
How would i get the library for this on android?
Without this lib, we were able to still get it to compile; however, the speed is many mulitples slower than 650ms on a Samsung Galaxy s5
-
As described in following, stridedgemm() is faster than gemm for batch gemm.
https://devblogs.nvidia.com/cublas-strided-batched-matrix-multiply/
https://docs.nvidia.com/cuda/cublas/index.html#cublas…