 Athe-kunal
commented
2 years ago
Athe-kunal
commented
2 years ago Can you re-run the experiments with all the technical indicators. I am not sure that why it is not performing well. Here are some of the reasons that I am speculating:
- Maybe in the testing set, the model performed well on the exposed data and then it didn't do well. Check the actions dataframe for it.
Also, the RL agent doesn't remember the data, rather it tries to capture the variation in data and based on those variations trades. These are just possible reasons, but yeah do run some more experiments to conclude.
 gendrelom
gendrelom
I tried two different tune runs: with future data(you can find this code by "#Future data") and without. I expected to see a big difference in rewards betweent these two runs(or at lease some difference), but instead of this I got almost the same results: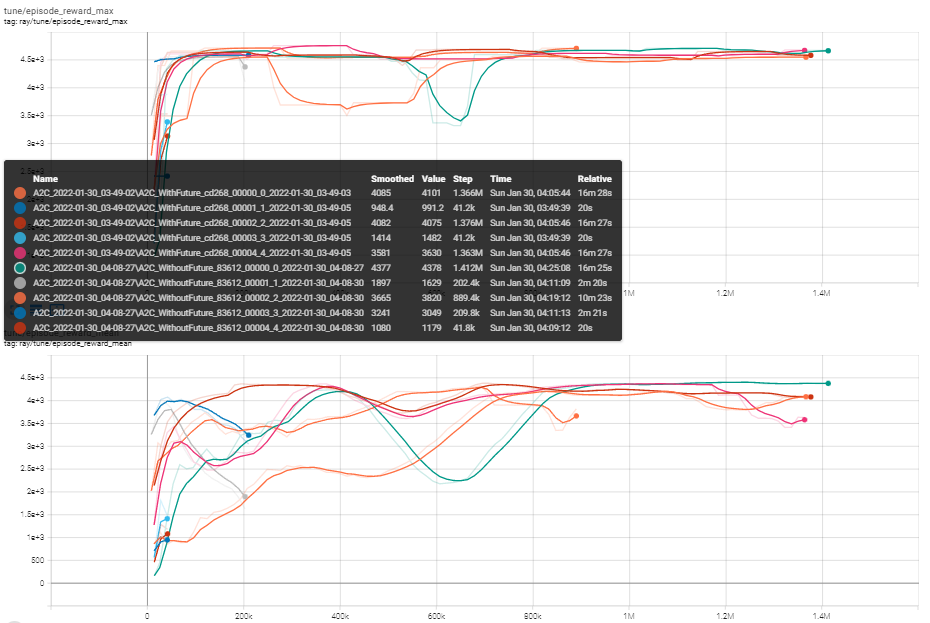
Here is the code which I used to tune environment with future data(when I tuned without future data I just commented out the corresponding lines):
I think this is important because if agent can't even learn on cheat data, then what is the reason to try to find some useful indicators? What do you think and how can I fix it?