 sisterAn
commented
5 years ago
sisterAn
commented
5 years ago 在 HTTP/1 中,每次请求都会建立一次HTTP连接,也就是我们常说的3次握手4次挥手,这个过程在一次请求过程中占用了相当长的时间,即使开启了 Keep-Alive ,解决了多次连接的问题,但是依然有两个效率上的问题:
- 第一个:串行的文件传输。当请求a文件时,b文件只能等待,等待a连接到服务器、服务器处理文件、服务器返回文件,这三个步骤。我们假设这三步用时都是1秒,那么a文件用时为3秒,b文件传输完成用时为6秒,依此类推。(注:此项计算有一个前提条件,就是浏览器和服务器是单通道传输)
- 第二个:连接数过多。我们假设Apache设置了最大并发数为300,因为浏览器限制,浏览器发起的最大请求数为6,也就是服务器能承载的最高并发为50,当第51个人访问时,就需要等待前面某个请求处理完成。
HTTP/2的多路复用就是为了解决上述的两个性能问题。 在 HTTP/2 中,有两个非常重要的概念,分别是帧(frame)和流(stream)。 帧代表着最小的数据单位,每个帧会标识出该帧属于哪个流,流也就是多个帧组成的数据流。 多路复用,就是在一个 TCP 连接中可以存在多条流。换句话说,也就是可以发送多个请求,对端可以通过帧中的标识知道属于哪个请求。通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极大的提高传输性能。
 azl397985856
azl397985856 Hiker9527
Hiker9527 Lie8466
Lie8466 aimeefe
aimeefe NuoHui
NuoHui yingye
yingye weixiaoxu123
weixiaoxu123 SnailOwO
SnailOwO NathanHan1
NathanHan1 Meow-z
Meow-z YuArtian
YuArtian JTangming
JTangming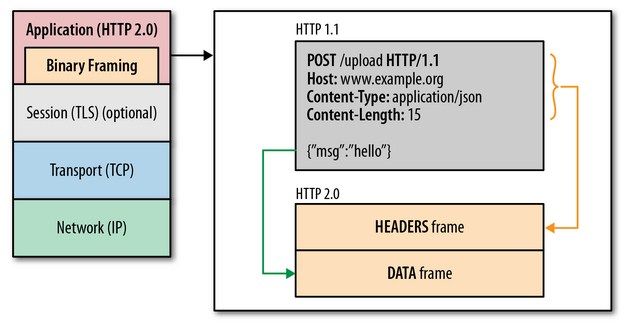
 dcy0701
dcy0701 yuexian1234
yuexian1234 ruofee
ruofee yuexunshi
yuexunshi huanzhiyazi
huanzhiyazi Soyn
Soyn thecoolbb
thecoolbb nk-akun
nk-akun chengfengfengwang
chengfengfengwang wrkaiser
wrkaiser Yuweiai
Yuweiai
 csDeng
csDeng jiangjiu
jiangjiu orangelunatics
orangelunatics DevinXian
DevinXian minami-WYL
minami-WYL
HTTP2采用二进制格式传输,取代了HTTP1.x的文本格式,二进制格式解析更高效。 多路复用代替了HTTP1.x的序列和阻塞机制,所有的相同域名请求都通过同一个TCP连接并发完成。在HTTP1.x中,并发多个请求需要多个TCP连接,浏览器为了控制资源会有6-8个TCP连接都限制。 HTTP2中