 HagegeR
commented
5 years ago
HagegeR
commented
5 years ago YOLOv3 608 means width&height=608, the best way to increase result should be to increase the width&height parameters, I think that you could even use subdivisions =32 in order to get the best width&height possible. also try to create a validation set and set it in the configuration file in order to get better understanding of your results during the training, loss is not enough most of the time.
try the label:Explanations in the issues section to get most of the YOLO bible directly from the mentor ;)
 AlexeyAB
AlexeyAB
 HanSeYeong
HanSeYeong
First I really appreciate with your beautiful YOLO v3.
I think the lack of 11GB vram with my 2080ti was the problem that I can't decrease the subdivision and increase width&height. So I bought a TITAN RTX 24GB graphic card which has enormous vram!!
My GPU is Titan RTX 24GB vram
My configuration for training YOLOv3 is
Above configurations are using maximum 22GB of vram. (When I use the subdivisions=4 and width=416, lack of memory error was occurred.... My titan rtx dream was gone...)
My data 2770 images with 8214 labeled boxes. 4 classes -> each of class is labeled 5047, 2490, 615, 62. train image resolution : 1280x720 not small objects to detect
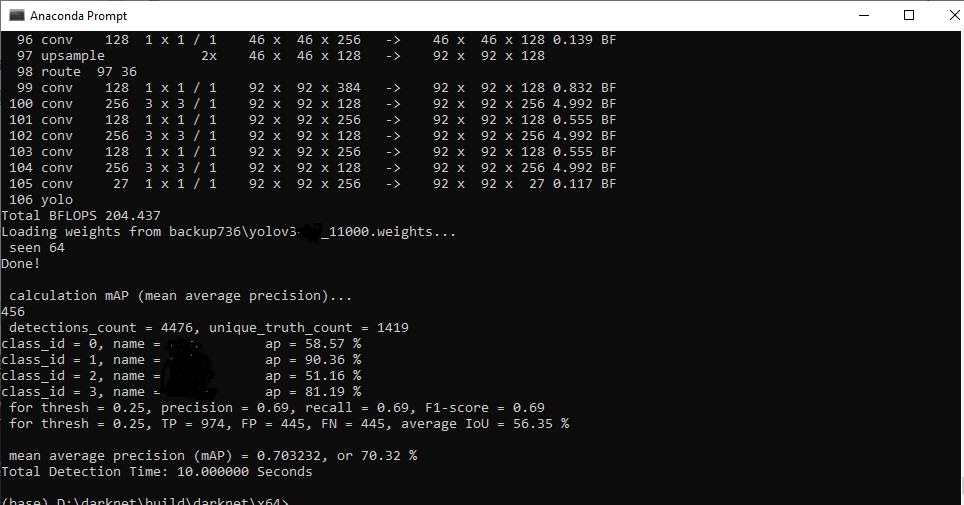
Result 31254 iterations the lowest loss was 0.59
I am sorry that I can't show the classes because of my secret project... I tested with images but the result was same with above accuracy.
What did I do for shrinking the loss of training:
My question From the 'When should I stop the training?'
I think my question can be helpful who wants to train the best custom labeled image model.
Sharing some experiences All the below results are trained by 1280x720 resolution images.
Training speed(per 1000 epochs)
Vram usage