 laclouis5
commented
4 years ago
laclouis5
commented
4 years ago @AlexeyAB Really great work!
For training, same partial weights as old tiny Yolo i.e. the first 15 layers yolov4-tiny.conv.15?
Open AlexeyAB opened 4 years ago
laclouis5
commented
4 years ago @AlexeyAB Really great work!
For training, same partial weights as old tiny Yolo i.e. the first 15 layers yolov4-tiny.conv.15?
 AlexeyAB
commented
4 years ago
AlexeyAB
commented
4 years ago @laclouis5
Use this pre-trained file for trainint yolov4-tiny.cfg: https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.conv.29
How to train yolov4-tiny.cfg: https://github.com/AlexeyAB/darknet#how-to-train-tiny-yolo-to-detect-your-custom-objects
 muhammad-maaz-confiz
commented
4 years ago
muhammad-maaz-confiz
commented
4 years ago Hi @alexeab,
Does OpenCV DNN module supports YoloV4-tiny? Thanks
AlexeyAB
commented
4 years ago We are waiting for the implementation of the YOLOv4-tiny in libraries:
 ark-
commented
4 years ago
ark-
commented
4 years ago Hi @alexeab,
Does OpenCV DNN module supports YoloV4-tiny? Thanks
OpenCV implemented it in their master branch in 6 days for Yolov4. This looks like a more trivial change required so here's hoping it will be live in a few days.
 LukeAI
commented
4 years ago
LukeAI
commented
4 years ago @AlexeyAB v. exciting. are you planning to release a paper on it? Would love to read some details about how it works. Is it a novel backbone or one of the existing CSPs? Do you have any numbers on the performance of the backbone as a classifier?
AlexeyAB
commented
4 years ago @LukeAI
There is used resize=1.5 instead of random=1, that you suggested, congrats! https://github.com/AlexeyAB/darknet/issues/3830
CSP: There is used groups for [route] layer for CSP - EFM: http://openaccess.thecvf.com/content_CVPRW_2020/papers/w28/Wang_CSPNet_A_New_Backbone_That_Can_Enhance_Learning_Capability_of_CVPRW_2020_paper.pdf Initially it was done for MixNet: https://github.com/AlexeyAB/darknet/issues/4203#issuecomment-551047590
There is used CIoU-loss with optimal normalizers (as in YOLOv4)
scale_x_y parameter (as in YOLOv4)
 bao-O
commented
4 years ago
bao-O
commented
4 years ago @AlexeyAB Can you explain why the last yolo layer uses masks starting from 1, not 0?
 CSTEZCAN
commented
4 years ago
CSTEZCAN
commented
4 years ago confirmed. performance is WOW.
https://youtu.be/TWteusBINIw
offline test (without connecting to the stream)
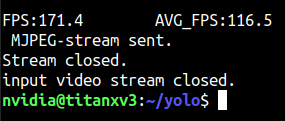
AlexeyAB
commented
4 years ago @CSTEZCAN Hi,
What FPS can you get by using such command without mjpeg_port?
darknet.exe detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights -i 0 -thresh 0.25 -ext_output test.mp4 -dont_show
On GPU RTX 2070, CPU Core i7 6700K
I get 230 FPS by using command:
darknet.exe detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights -ext_output test.mp4 -dont_show
in both cases (1) NMS is commented and (2) NMS isn't commented
I get 330 FPS by using command - it doesn't read videofile:
darknet.exe detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights -ext_output test.mp4 -dont_show -benchmark
So the bottleneck is OpenCV: (1) cv::VideoCapture Video Capturing from file/camera and (2) cv::imshow / cv::wait_key Showing video on the screen / sending by TCP/IP -mjpeg_port 8090 flag
AlexeyAB
commented
4 years ago @DoriHp Just to compare with Yolov3-tiny where were used the same masks, it seems tiny models don't detect well small objects anyway.
bao-O
commented
4 years ago I saw yolov3-tiny_3l.cfg with 3 yolo layers. So due to what you said, the last yolo layers has no use?
AlexeyAB
commented
4 years ago To detect small objects you must also use 3-yolo-layers in yolov4-tiny.
CSTEZCAN
commented
4 years ago @AlexeyAB Hello Alexey! this is your "Piano Concerto No. 2 Op. 18". I have infinite respect for your work.
My results as follows;
nvidia-smi -pl 125 watts titan x pascal
nvidia-smi -pl 250 watts titan x pascal

Will be running tests on Jetson Nano, TX2 and Xavier later..
AlexeyAB
commented
4 years ago @CSTEZCAN Thanks! I think yolov4-tiny can work with 500 - 1000 FPS by using OpenCV or tkDNN/TensorRT when it will be implemented in these libraries.
CSTEZCAN
commented
4 years ago @AlexeyAB I have no doubt. The only weird thing I noticed is, it uses CPU relatively more during training compared to YOLOv4. The recommended system must start from Ryzen 3500 and above for an optimal performance (if you are creating such recommended setup list) :)
 choochtech
commented
4 years ago
choochtech
commented
4 years ago @AlexeyAB good job ! great work !
CSTEZCAN
commented
4 years ago @AlexeyAB Nvidia Jetson AGX Xavier can do (all avg_fps) MAX_N : 120.5 15W: 36.0 30W ALL: 68.9 30W 2core: 28.9

Training on tiny takes around 2 hours for a single class model for 5000 batches (which is usually enough) on xavier
it is just great!
 ghost
commented
4 years ago
ghost
commented
4 years ago @AlexeyAB you truly outdone yourself, I am impressed. The OpenCV/tensort rt will be a game changer. @CSTEZCAN post the nano results, along with testing cpu-only mode results.
 marvision-ai
commented
4 years ago
marvision-ai
commented
4 years ago @CSTEZCAN what jetpack version are you using ? And are you training networks on the Xavier too?
 1027663760
commented
4 years ago
1027663760
commented
4 years ago On training on yolov4-tiny, I met nan, and when adversarial_lr=1 attention=1, I saw a pure black picture The default learning_rate is too large, I set it to learning_rate=0.001 to only ease the time when nan appears
AlexeyAB
commented
4 years ago @AlexeyAB you truly outdone yourself, I am impressed. The OpenCV/tensort rt will be a game changer.
Thanks so much for @WongKinYiu
CSTEZCAN
commented
4 years ago @deepseek nano has some problems, maybe about ram. edit2: nano can do max_N:16fps, 5W:10.2fps. @mbufi I've trained 1 model on it, at 30 watts mode, it can train models without any problems. edit1: it is an old jetpack from last year, probably 4.2 or 4.3.
CSTEZCAN
commented
4 years ago There is a small question - there is no implementation in cv2 yet - what is the easiest way to run the model on the CPU (in the application) without a large number of dependencies?
question of the century :)
LukeAI
commented
4 years ago There is a small question - there is no implementation in cv2 yet - what is the easiest way to run the model on the CPU (in the application) without a large number of dependencies?
can you not run with darknet, compiled without CUDA?
marvision-ai
commented
4 years ago @CSTEZCAN what resolution images are you training and running inference on with the Xavier? I'd love to see an example cfg file that supports that performance you are showing.
Thanks for testing everything! Super helpful.
CSTEZCAN
commented
4 years ago @CSTEZCAN what resolution images are you training and running inference on with the Xavier? I'd love to see an example cfg file that supports that performance you are showing.
nothing especially changed on the yolov4-tiny.cfg (except class number and filters) so training & inferencing resolutions are same. https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4-tiny.cfg
 zbyuan
commented
4 years ago
zbyuan
commented
4 years ago @AlexeyAB Hello Alexey! [route] layers=-1 groups=2 group_id=1 What does it mean?
AlexeyAB
commented
4 years ago @zbyuan Read: https://github.com/opencv/opencv/issues/17666
CSTEZCAN
commented
4 years ago @CSTEZCAN okay cool. And for the video you are passing it, what's the resolution of the frames before resizing them? How are the detections of small objects? (especially if the algorithm is resizing it to smaller before putting it through the network.) This is great information you are providing.
Dude come on, I don't know your data, I don't know your label quality. You have to test them "yourself"
marvision-ai
commented
4 years ago @CSTEZCAN great thanks!
CSTEZCAN
commented
4 years ago mac mini perf test. https://www.youtube.com/watch?v=0ZrfTglY4SI
 wwzh2015
commented
4 years ago
wwzh2015
commented
4 years ago Hi,What is the score that the yolo4-tiny tested in voc2007 and trained in voc2007+2012.
 piaomiaoju
commented
4 years ago
piaomiaoju
commented
4 years ago why there are no spp layers selected in yolo4-tiny? @AlexeyAB
AlexeyAB
commented
4 years ago @piaomiaoju @WongKinYiu Yes, maybe we can try to use small SPP: yolov4-tiny-spp.cfg.txt
### SPP
[maxpool]
size=3
stride=1
[route]
layers=-2
[maxpool]
size=5
stride=1
[route]
layers=-1,-3,-4 Anafeyka
commented
4 years ago
Anafeyka
commented
4 years ago @piaomiaoju @WongKinYiu Yes, maybe we can try to use small SPP: yolov4-tiny-spp.cfg.txt
### SPP [maxpool] size=3 stride=1 [route] layers=-2 [maxpool] size=5 stride=1 [route] layers=-1,-3,-4share an example cfg small SPP + 3 layers of yolo. To detect small objects
 BackT0TheFuture
commented
4 years ago
BackT0TheFuture
commented
4 years ago To detect small objects you must also use 3-yolo-layers in yolov4-tiny.
great works! do you have plan for 3-yolo-layers in yolov4-tiny? thanks!
 javier-box
commented
4 years ago
javier-box
commented
4 years ago @AlexeyAB .. nice... well done.. yolov4-tiny is in the goldielocks zone... not too slow and just the right mAP.
You can also use the other yolov4 bag of tricks to get a slightly better mAP
 www7890
commented
4 years ago
www7890
commented
4 years ago To detect small objects you must also use 3-yolo-layers in yolov4-tiny.
great works! do you have plan for 3-yolo-layers in yolov4-tiny? thanks!
Want to know , too!
 tobyglei
commented
4 years ago
tobyglei
commented
4 years ago Exciting news. Thanks for the good work @AlexeyAB
 JasonDoingGreat
commented
4 years ago
JasonDoingGreat
commented
4 years ago @CSTEZCAN Thanks! I think yolov4-tiny can work with 500 - 1000 FPS by using OpenCV or tkDNN/TensorRT when it will be implemented in these libraries.
Using tkDNN fresh yolov4-tiny impl, tested on Jetson Nano with JetPack 4.4, TensorRT v7.1, 416 input size
For FP32, profile results:
Time stats:
Min: 37.3371 ms
Max: 122.952 ms
Avg: 38.0922 ms 26.2521 FPSFor FP16, profile results:
Time stats:
Min: 24.5687 ms
Max: 90.5088 ms
Avg: 25.5292 ms 39.1709 FPS[route] layers=-1 groups=2 group_id=1 if we don't slice the layer here, i think there are no accuracy degradation, but very little size added.
wwzh2015
commented
4 years ago degrade
what‘s mean?
AlexeyAB
commented
4 years ago RTX 2080Ti (CUDA 10.2, TensorRT 7.0.0, Cudnn 7.6.5, tkDNN); for yolo4tiny 416x416, on 1200 images of size 416x416: https://github.com/ceccocats/tkDNN/issues/59#issuecomment-652269964
AlexeyAB
commented
4 years ago @CSTEZCAN Thanks! I think yolov4-tiny can work with 500 - 1000 FPS by using OpenCV or tkDNN/TensorRT when it will be implemented in these libraries.
I was very mistaken, here 2000 FPS, not 1000 FPS
AlexeyAB
commented
4 years ago Jetson AGX (CUDA 10.2, TensorRT 7.0.0, Cudnn 7.6.5, tkDNN); for yolo4tiny 416x416, on 1200 images of size 416x416: https://github.com/ceccocats/tkDNN/issues/59#issuecomment-652420971
ghost
commented
4 years ago Mayday, Mayday!! @CSTEZCAN Confirm the fps math, does it check? because Alex might have changed the GAME. @AlexeyAB How is this even possible??! were you able to main the accuracy? tell me everything.
CSTEZCAN
commented
4 years ago @CSTEZCAN Thanks! I think yolov4-tiny can work with 500 - 1000 FPS by using OpenCV or tkDNN/TensorRT when it will be implemented in these libraries.
I was very mistaken, here 2000 FPS, not 1000 FPS
I really don't know what to say @AlexeyAB you've rocked this planet & probably beyond :) Lets work on totally unsupervised classification & detection next time for mars rovers :)
CSTEZCAN
commented
4 years ago Mayday, Mayday!! @CSTEZCAN Confirm the fps math, does it check? because Alex might have changed the GAME. @AlexeyAB How is this even possible??!
I don't have tkDNN setup on Xavier and I don't have RTX GPU to check INT8, FP16 to reach those numbers... but the source is trustworthy. If they say it works, it works.
AlexeyAB
commented
4 years ago Darknet isn't optimized for inference on CPU (even with AVX=1 OPENMP=1). Use https://github.com/Tencent/ncnn for testing on CPU (Desktop, Laptop, Smartphones) or wait for the implementation of yolov4-tiny in the OpenCV library https://github.com/opencv/opencv/issues/17666
Discussion: https://www.reddit.com/r/MachineLearning/comments/hu7lyt/p_yolov4tiny_speed_1770_fps_tensorrtbatch4/
Full structure: structure of yolov4-tiny.cfg model
YOLOv4-tiny released:
40.2%AP50,371FPS (GTX 1080 Ti) /330FPS (RTX 2070)1770 FPS - on GPU RTX 2080Ti - (416x416, fp16, batch=4) tkDNN/TensorRT https://github.com/ceccocats/tkDNN/issues/59#issuecomment-652269964
1353 FPS - on GPU RTX 2080Ti - (416x416, fp16, batch=4) OpenCV 4.4.0 (including: transfering CPU->GPU and GPU->CPU) (excluding: nms, pre/post-processing) https://github.com/AlexeyAB/darknet/issues/6067#issuecomment-656604015
39 FPS- 25ms latency - on Jetson Nano - (416x416, fp16, batch=1) tkDNN/TensorRT https://github.com/ceccocats/tkDNN/issues/59#issuecomment-652157334290 FPS- 3.5ms latency - on Jetson AGX - (416x416, fp16, batch=1) tkDNN/TensorRT https://github.com/ceccocats/tkDNN/issues/59#issuecomment-65215733442 FPS- on CPU Core i7 7700HQ (4 Cores / 8 Logical Cores) - (416x416, fp16, batch=1) OpenCV 4.4.0 (compiled with OpenVINO backend) https://github.com/AlexeyAB/darknet/issues/6067#issuecomment-65669352920 FPSon CPU ARM Kirin 990 - Smartphone Huawei P40 https://github.com/AlexeyAB/darknet/issues/6091#issuecomment-651502121 - Tencent/NCNN library https://github.com/Tencent/ncnn120 FPSon nVidia Jetson AGX Xavier - MAX_N - Darknet framework371FPS on GPU GTX 1080 Ti - Darknet framework