 AlexeyAB
commented
4 years ago
AlexeyAB
commented
4 years ago @wuzhenxin1989
- Run detection several times (first detection is slow due to GPU initialization)
- Show screenshot.
Open AlexeyAB opened 4 years ago
AlexeyAB
commented
4 years ago @wuzhenxin1989
 KyloEntro
commented
4 years ago
KyloEntro
commented
4 years ago Hi, I'm running yolov4 and yolov4-tiny on a rtx2080ti and i9 in python program with opencv dnn
Is it normal that I have 166 FPS in tiny and 55fps with yolov4 ? I'm using opencv dnn with cuda_fp16 target and detectModel object (+ do nms and get in list the result) My question is : is the performance I get is normal on a rtx2080ti ?
 YashasSamaga
commented
4 years ago
YashasSamaga
commented
4 years ago Is it normal that I have 166 FPS in tiny and 55fps with yolov4?
What is the input image size?
Can you try measuring the FPS with this?
 KyryloAntoshyn
commented
4 years ago
KyryloAntoshyn
commented
4 years ago Hi, thank you for the YOLOv4-tiny release, @AlexeyAB! It's a very great job!
I am working on the project that must work on NVIDIA Jetson Nano to detect persons in real-time and I have two questions:
I chose YOLOv4-tiny, because I was comparing it with MobileNetV2-SSD, SqueezeNet and ThunderNet (lightweight detectors). I found the following COCO results: 40.2 AP50 for YOLOv4-tiny, 22.1-22.2 AP for MobileNetV2-SSD and 33.7-40.3-46.2 AP50 (262-473-1300 MFLOPs) for ThunderNet. For SqueezeNet I didn't find AP. Is YOLO the best choice among these detectors for my task (real-time persons detection on Jetson Nano)?
I was reading that I can run YOLOv4-tiny with: darknet framework (16 FPS), tkDNN/TensorRT library (39 FPS), OpenCV and Tencent-NCNN. I want to perform transfer learning for my task: train the network on images from pedestrian datasets like Caltech Pedestrian Dataset. Do I need to leverage darknet framework for training (transfer learning) and tkDNN/TensorRT or OpenCV for inference? Am I able to train YOLOv4-tiny only with darknet framework or I can do it with OpenCV too (tkDNN/TensorRT is only for inference)?
Thank you in advance!
AlexeyAB
commented
4 years ago Hi,
KyryloAntoshyn
commented
4 years ago Hi,
- Yes, yolov4-tiny is a Top-1 lightweight object detector in terms Speed & Accuracy.
- You can do transfer-learning by using Darknet, and then use these cfg/weights files in tkDNN or OpenCV to run inference on Jetson Nano with ~40 FPS
Thank you so much for your time and help!
 forestguan
commented
4 years ago
forestguan
commented
4 years ago Hi, @AlexeyAB , thanks for your great job. I want to convert yolov4-tiny.weights to caffemodel. But there are some errors. $ python darknet2caffe.py cfg/yolov4-tiny.cfg weights/yolov4-tiny.weights prototxt/yolov4-tiny.prototxt caffemodel/yolov4-tiny.caffemodel
$Traceback (most recent call last):
File "darknet2caffe.py", line 521, in
When I change "buf = np.fromfile(fp, dtype = np.float32)" to "buf = np.fromfile(fp, dtype = np.float16)" in darknet2caffe.py, this error is disappear. Is it correct? Sincerely.
 richardgohth
commented
4 years ago
richardgohth
commented
4 years ago Tested on Xavier NX, with 720p video, fps was around 5 to 8. Width and height in cfg file changed to 320. Is this normal? How to make it go faster? thanks
 ajaykumaar
commented
4 years ago
ajaykumaar
commented
4 years ago Hi, firstly, thanks for the wonderful implementation! Can I use the weights and cfg of YOLOV4-tiny for any Darknet model (i.e. model for full-size YOLOV3)? If not can you suggest the best model to chuck the weights in?
Thanks
 LukeAI
commented
4 years ago
LukeAI
commented
4 years ago Hi, firstly, thanks for the wonderful implementation! Can I use the weights and cfg of YOLOV4-tiny for any Darknet model (i.e. model for full-size YOLOV3)? If not can you suggest the best model to chuck the weights in?
Thanks
You cannot. What is it that you want to do?
ajaykumaar
commented
4 years ago Hi, firstly, thanks for the wonderful implementation! Can I use the weights and cfg of YOLOV4-tiny for any Darknet model (i.e. model for full-size YOLOV3)? If not can you suggest the best model to chuck the weights in? Thanks
You cannot. What is it that you want to do?
Hi, thanks for the quick reply. I want to build an object detector with YOLOV4-tiny and I used the weights and config file for the same from this repo. To load the weights into a model, I used the darknet which was built for YOLOV3 from another repo and I got the input size mismatch error. So which model should I use to load the the weights from this repo?
LukeAI
commented
4 years ago Hi, firstly, thanks for the wonderful implementation! Can I use the weights and cfg of YOLOV4-tiny for any Darknet model (i.e. model for full-size YOLOV3)? If not can you suggest the best model to chuck the weights in? Thanks
You cannot. What is it that you want to do?
Hi, thanks for the quick reply. I want to build an object detector with YOLOV4-tiny and I used the weights and config file for the same from this repo. To load the weights into a model, I used the darknet which was built for YOLOV3 from another repo and I got the input size mismatch error. So which model should I use to load the the weights from this repo?
what do you mean? use the weights alexeyab has provided.
ajaykumaar
commented
4 years ago The issue is that I used alexeyab weights and cfg files like below...
config_path='config/yolov4-tiny.cfg'
weights_path='yolov4-tiny.weights'
model=Darknet(config_path,img_size=416)
model.load_weights(weights_path)
But I get the runtime error: shape [256,384,3,3] is invalid input of size 756735. and the Darknet() was from this repo
How do I resolve this?
LukeAI
commented
4 years ago The issue is that I used alexeyab weights and cfg files like below...
config_path='config/yolov4-tiny.cfg'weights_path='yolov4-tiny.weights'model=Darknet(config_path,img_size=416)model.load_weights(weights_path)But I get the runtime error: shape [256,384,3,3] is invalid input of size 756735. and the Darknet() was from this repo
How do I resolve this?
I don't know, why don't you ask on that repo? I don't think you'll get an answer about a different repo here.
 marvision-ai
commented
4 years ago
marvision-ai
commented
4 years ago I have a question a few questions that I wrote in this issue: https://github.com/AlexeyAB/darknet/issues/6548 but had not resolution. Please see below:
I am in the process of detecting 4 types small objects. I have been going through all the extra steps to increase performance.
I calculated these custom achors: anchors = 9, 11, 17, 17, 15, 65, 31, 34, 41, 61, 44,121, 88, 74, 99,123, 180,144
Custom anchors
Only if you are an expert in neural detection networks - recalculate anchors for your dataset for width and height from cfg-file: darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416 then set the same 9 anchors in each of 3 [yolo]-layers in your cfg-file. But you should change indexes of anchors masks= for each [yolo]-layer, so for YOLOv4 the 1st-[yolo]-layer has anchors smaller than 30x30, 2nd smaller than 60x60, 3rd remaining, and vice versa for YOLOv3. Also you should change the filters=(classes + 5)*
before each [yolo]-layer. If many of the calculated anchors do not fit under the appropriate layers - then just try using all the default anchors.
I took what you said, and applied it as such to my .cfg but I am not getting much of an increase (1%) performance compared to the original anchors.
Here is my .cfg portion: I changed the filters=(classes + 5)*<number of mask> and I made sure to go based on the largest achors in the first layer, and the smallest anchors in the last.
[convolutional]
size=1
stride=1
pad=1
filters=36
activation=linear
[yolo]
mask = 5,6,7,8
anchors = 9, 11, 17, 17, 15, 65, 31, 34, 41, 61, 44,121, 88, 74, 99,123, 180,144
classes=4
num=9
jitter=.3
scale_x_y = 1.05
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
ignore_thresh = .7
truth_thresh = 1
random=1
resize=1.5
nms_kind=greedynms
beta_nms=0.6
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 23
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=27
activation=linear
[yolo]
mask = 2,3,4
anchors = 9, 11, 17, 17, 15, 65, 31, 34, 41, 61, 44,121, 88, 74, 99,123, 180,144
classes=4
num=9
jitter=.3
scale_x_y = 1.05
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
ignore_thresh = .7
truth_thresh = 1
random=1
resize=1.5
nms_kind=greedynms
beta_nms=0.6
[route]
layers = -3
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 15
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 0,1
anchors = 9, 11, 17, 17, 15, 65, 31, 34, 41, 61, 44,121, 88, 74, 99,123, 180,144
classes=4
num=9
jitter=.3
scale_x_y = 1.05
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
ignore_thresh = .7
truth_thresh = 1
random=1
resize=1.5
nms_kind=greedynms
beta_nms=0.63 Questions:
( 9, 11) anchor, should I just ignore that (too small) and just have the last layer show mask = 1 ?I also want to implement the following suggestions:
for training for small objects (smaller than 16x16 after the image is resized to 416x416) - set layers = 23 instead of https://github.com/AlexeyAB/darknet/blob/6f718c257815a984253346bba8fb7aa756c55090/cfg/yolov4.cfg#L895
set stride=4 instead of https://github.com/AlexeyAB/darknet/blob/6f718c257815a984253346bba8fb7aa756c55090/cfg/yolov4.cfg#L892 set stride=4 instead of https://github.com/AlexeyAB/darknet/blob/6f718c257815a984253346bba8fb7aa756c55090/cfg/yolov4.cfg#L989
 ghost
commented
4 years ago
ghost
commented
4 years ago Hey @AlexeyAB !! I would like to get a suggestion from you regrading the choice of Object Detector: SSDMobileNetv2 and Yolov4-tiny in terms of speed and accuracy/mAP for a mobile application. Please help !! Thanks !!
 wwzh2015
commented
4 years ago
wwzh2015
commented
4 years ago Hey @AlexeyAB !! I would like to get a suggestion from you regrading the choice of Object Detector: SSDMobileNetv2 and Yolov4-tiny in terms of speed and accuracy/mAP for a mobile application. Please help !! Thanks !!
SSDMobileNetv2 is lower
 SilverWaveGL
commented
4 years ago
SilverWaveGL
commented
4 years ago @wwzh2015 : Can you please share this comparison?
 lisifann
commented
4 years ago
lisifann
commented
4 years ago @AlexeyAB Excuse me, could you help me to explain what groups = 2, group_id = 1 means? And did you refer to any papers on this?
 lliming2006
commented
3 years ago
lliming2006
commented
3 years ago Hi, @AlexeyAB , thanks for your great job. I had converted yolov4-tiny.weights to caffemodel and test its , (in caffemodel, i use the "slice"layer and "silence"layers replace the route layer that include "groups" in yolov4-tiny, but there is big difference result between Caffe framework and darknet framework on same image. es. to some Target objects in image,there are two or three Target boxes( one box contain one or two small boxes after do_nms_sort, these boxes are the same category, their scores are slightly different ),why?
 WENKONG01
commented
3 years ago
WENKONG01
commented
3 years ago Discussion: https://www.reddit.com/r/MachineLearning/comments/hu7lyt/p_yolov4tiny_speed_1770_fps_tensorrtbatch4/
Full structure: https://lutzroeder.github.io/netron/?url=https%3A%2F%2Fraw.githubusercontent.com%2FAlexeyAB%2Fdarknet%2Fmaster%2Fcfg%2Fyolov4-tiny.cfg
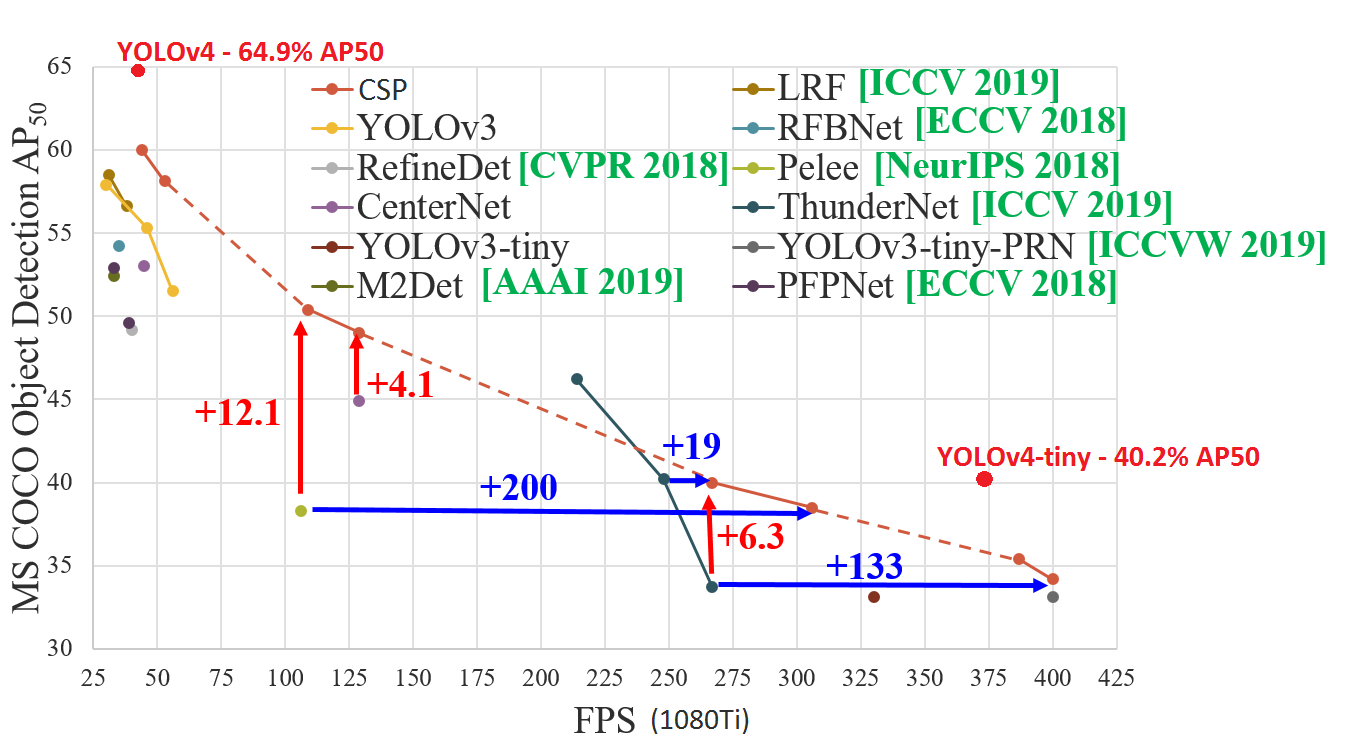
YOLOv4-tiny released:
40.2%AP50,371FPS (GTX 1080 Ti) /330FPS (RTX 2070)
1770 FPS - on GPU RTX 2080Ti - (416x416, fp16, batch=4) tkDNN/TensorRT ceccocats/tkDNN#59 (comment)
1353 FPS - on GPU RTX 2080Ti - (416x416, fp16, batch=4) OpenCV 4.4.0 (including: transfering CPU->GPU and GPU->CPU) (excluding: nms, pre/post-processing) #6067 (comment)
39 FPS- 25ms latency - on Jetson Nano - (416x416, fp16, batch=1) tkDNN/TensorRT ceccocats/tkDNN#59 (comment)
290 FPS- 3.5ms latency - on Jetson AGX - (416x416, fp16, batch=1) tkDNN/TensorRT ceccocats/tkDNN#59 (comment)
42 FPS- on CPU Core i7 7700HQ (4 Cores / 8 Logical Cores) - (416x416, fp16, batch=1) OpenCV 4.4.0 (compiled with OpenVINO backend) #6067 (comment)
20 FPSon CPU ARM Kirin 990 - Smartphone Huawei P40 #6091 (comment) - Tencent/NCNN library https://github.com/Tencent/ncnn
120 FPSon nVidia Jetson AGX Xavier - MAX_N - Darknet framework
371FPS on GPU GTX 1080 Ti - Darknet frameworkcfg: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4-tiny.cfg
weights: https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.weights
source yolov3-tiny (800x800) yolov4-tiny (800x800)


hi AlexeyAB, thanks for your great job. could you tell me which datasets the pictures is from? thanks.
 WongKinYiu
commented
3 years ago
WongKinYiu
commented
3 years ago i do not know which datasets the picture is from, but i get the source picture from https://github.com/google/automl/tree/master/efficientdet .
lliming2006
commented
3 years ago if you only test the generalization ability of the model ,you can get some test dataset on the overpass!
Best Regards 刘黎明 Tel:15910968546 微信: llm454650810 QQ:632846506
----- 原始邮件 ----- 发件人:"Kin-Yiu, Wong" @.> 收件人:AlexeyAB/darknet @.> 抄送人:lliming2006 @.>, Comment @.> 主题:Re: [AlexeyAB/darknet] YOLOv4-tiny released: 40.2% AP50, 371 FPS (GTX 1080 Ti), 1770 FPS tkDNN/TensorRT (#6067) 日期:2021年06月01日 17点59分
i do not know which datasets the picture is from, but i get the source picture from https://github.com/google/automl/tree/master/efficientdet .
— You are receiving this because you commented. Reply to this email directly, view it on GitHub, or unsubscribe.
WENKONG01
commented
3 years ago i do not know which datasets the picture is from, but i get the source picture from https://github.com/google/automl/tree/master/efficientdet .
Okay, thanks for your reply.
WENKONG01
commented
3 years ago if you only test the generalization ability of the model ,you can get some test dataset on the overpass! … -------------------------------- Best Regards 刘黎明 Tel:15910968546 微信: llm454650810 QQ:632846506 ----- 原始邮件 ----- 发件人:"Kin-Yiu, Wong" @.> 收件人:AlexeyAB/darknet @.> 抄送人:lliming2006 @.>, Comment @.> 主题:Re: [AlexeyAB/darknet] YOLOv4-tiny released: 40.2% AP50, 371 FPS (GTX 1080 Ti), 1770 FPS tkDNN/TensorRT (#6067) 日期:2021年06月01日 17点59分 i do not know which datasets the picture is from, but i get the source picture from https://github.com/google/automl/tree/master/efficientdet . — You are receiving this because you commented. Reply to this email directly, view it on GitHub, or unsubscribe.
thanks!
 Fetulhak
commented
3 years ago
Fetulhak
commented
3 years ago @DoriHp Can you explain why the last yolo layer uses masks starting from 1, not 0? in yolov4-tiny. did you get the answer or is it a mistake?
WongKinYiu
commented
3 years ago We just follow yolov3-tiny to use masks starting from 1 for fair comparison.
Fetulhak
commented
3 years ago In that case you are not going to use the last anchor size. am I correct?
WongKinYiu
commented
3 years ago yes, anchor with index 0 is not used in that case.
Fetulhak
commented
3 years ago @AlexeyAB Excuse me, could you help me to explain what groups = 2, group_id = 1 means? And did you refer to any papers on this?
did anyone explain how the backbone of yolov4-tiny works? it is easy to follow yolov4-custom.cfg but in yolov4-tiny.cfg it becomes difficult for me to understand. in the route layer there is groups parameter does this indicate group convolution? if there is group convolution don't we need shuffle parameter too? @AlexeyAB @WongKinYiu please give us a reading reference how the architecture of the backbone implemented? I have seen @AlexeyAB response here https://github.com/AlexeyAB/darknet/issues/6067#issuecomment-649857780
AlexeyAB
commented
3 years ago @Fetulhak
[route]
layers=-1
groups=2
group_id=1It means,
layers=-1 - it gets output of previous layer (layer_id - 1) as input, then groups=2 - it divides this input by channels into 2 groupsgroup_id=1 - output of this layer will be just the 2nd groupSo in Pytorch it can be implemented as:
b,c,h,w = input.shape
out = input[:,:, c/2:c ,:]Look at the Full structure of yolov4-tiny.cfg model
This is related to the CSP paper: https://openaccess.thecvf.com/content_CVPRW_2020/html/w28/Wang_CSPNet_A_New_Backbone_That_Can_Enhance_Learning_Capability_of_CVPRW_2020_paper.html

Fetulhak
commented
3 years ago @AlexeyAB thank you for your great illustration of the Yolov4-tiny backbone structure.

Discussion: https://www.reddit.com/r/MachineLearning/comments/hu7lyt/p_yolov4tiny_speed_1770_fps_tensorrtbatch4/
Full structure: structure of yolov4-tiny.cfg model
YOLOv4-tiny released:
40.2%AP50,371FPS (GTX 1080 Ti) /330FPS (RTX 2070)1770 FPS - on GPU RTX 2080Ti - (416x416, fp16, batch=4) tkDNN/TensorRT https://github.com/ceccocats/tkDNN/issues/59#issuecomment-652269964
1353 FPS - on GPU RTX 2080Ti - (416x416, fp16, batch=4) OpenCV 4.4.0 (including: transfering CPU->GPU and GPU->CPU) (excluding: nms, pre/post-processing) https://github.com/AlexeyAB/darknet/issues/6067#issuecomment-656604015
39 FPS- 25ms latency - on Jetson Nano - (416x416, fp16, batch=1) tkDNN/TensorRT https://github.com/ceccocats/tkDNN/issues/59#issuecomment-652157334290 FPS- 3.5ms latency - on Jetson AGX - (416x416, fp16, batch=1) tkDNN/TensorRT https://github.com/ceccocats/tkDNN/issues/59#issuecomment-65215733442 FPS- on CPU Core i7 7700HQ (4 Cores / 8 Logical Cores) - (416x416, fp16, batch=1) OpenCV 4.4.0 (compiled with OpenVINO backend) https://github.com/AlexeyAB/darknet/issues/6067#issuecomment-65669352920 FPSon CPU ARM Kirin 990 - Smartphone Huawei P40 https://github.com/AlexeyAB/darknet/issues/6091#issuecomment-651502121 - Tencent/NCNN library https://github.com/Tencent/ncnn120 FPSon nVidia Jetson AGX Xavier - MAX_N - Darknet framework371FPS on GPU GTX 1080 Ti - Darknet framework