 readicculus
commented
3 years ago
readicculus
commented
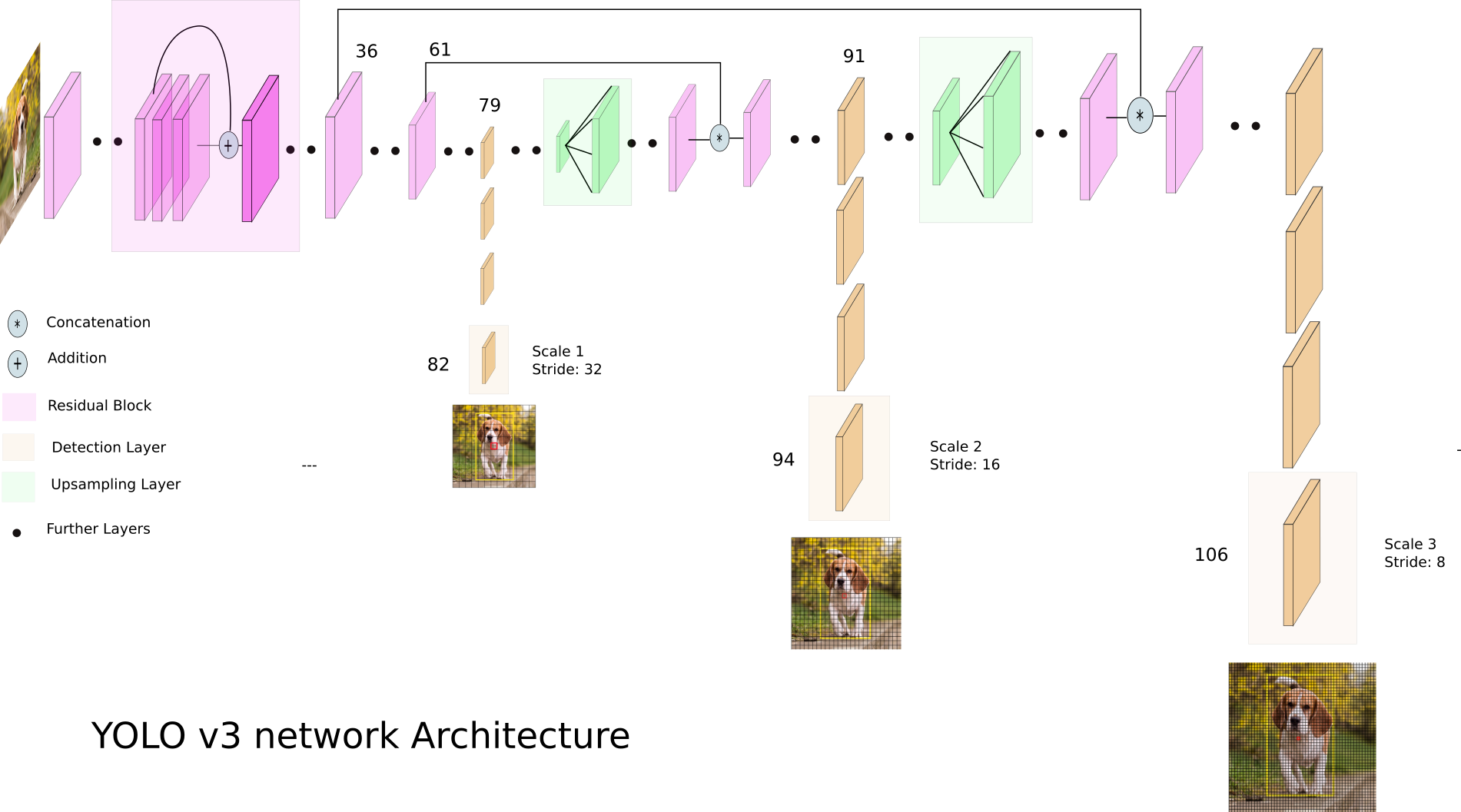
3 years ago Multi-scale detection is the idea here. With a 416x416 input you have 3 feature maps, first is 13x13xn_features then 26x26xn_features then 52x52xn_features. The 13x13 is good for bigger objects, 52x52 for detection smaller objects.
Yolo only outputs a single array of detections at the end when it filters out all the noise and low-objectness detections. The network itself outputs one detection per grid cell at each of the 3 yolo layers so many many many detections. Then there is some filtering based on objectness so most boxes are discarded immediately and nms to filter overlapping boxes.
As far as I know the yolov4 architecture hold the same general idea as yolov3 so this graphic may help you understand what is going on. I hope to play around with v4 soon but still only really working with v3 models so its possible some of this is a little bit different in v4.
 ghost
ghost
Hello,
I have been trying to re-write the YOLOv4 architecture using tensorflow and I found out that there are 3 different outputs ([yolo] layers). As far as I know, Yolo outputs one vector holding the coordinates of the bouding boxes, the object class and the probability of prediction. What are the three outputs for ? Does each one output a different bounding box and then we pick the one with the highest probability ?
Any help would be appreciated. Thank you very much !😊