dexception
commented
6 years ago
dexception
commented
6 years ago I am not sure how comfortable you are with Java. But here is the code:
public static ArrayList<String> parseAndReturnData(String path) throws ParserConfigurationException, SAXException, IOException
{
ArrayList<String> boxList= new ArrayList<String>();
File file = new File(path);
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document doc = db.parse(file);
doc.getDocumentElement().normalize();
System.out.println("Root element :" + doc.getDocumentElement().getNodeName());
NodeList sizeList = doc.getElementsByTagName("size");
int width = -1;
int height = -1;
System.out.println("Size tags:"+sizeList.getLength());
NodeList sizeChildNodes = sizeList.item(0).getChildNodes();
for(int j=0;j< sizeChildNodes.getLength();j++)
{
if(sizeChildNodes.item(j).getNodeName().equals("width"))
width = Integer.parseInt(sizeChildNodes.item(j).getTextContent());
if(sizeChildNodes.item(j).getNodeName().equals("height"))
height = Integer.parseInt(sizeChildNodes.item(j).getTextContent());
}
System.out.println("width:"+width);
System.out.println("height:"+height);
NodeList objectList = doc.getElementsByTagName("object");
System.out.println("Object Length:"+objectList.getLength());
for (int temp = 0; temp< objectList.getLength(); temp++)
{
Node objectNode = objectList.item(temp);
if (objectNode.getNodeType() == Node.ELEMENT_NODE)
{
Element objectElement = (Element) objectNode;
System.out.println("Current Node: "+objectElement.getNodeName());
NodeList childObjectNodes = objectElement.getChildNodes();
for(int z=0;z<childObjectNodes.getLength();z++)
{
Node childObjectNode = childObjectNodes.item(z);
System.out.println(childObjectNode.getNodeName());
if(childObjectNode.getNodeName().equals("bndbox"))
{
NodeList bndboxChildNodes = childObjectNode.getChildNodes();
int xmin=-1,ymin=-1,xmax=-1,ymax=-1;
for(int temp2 = 0; temp2< bndboxChildNodes.getLength();temp2++)
{
Node bndboxChildNode = bndboxChildNodes.item(temp2);
if (bndboxChildNode.getNodeType() == Node.ELEMENT_NODE )
{
Element e2 = (Element) bndboxChildNode;
if(e2.getNodeName().equals("xmin"))
xmin = Integer.parseInt(e2.getTextContent());
else if(e2.getNodeName().equals("ymin"))
ymin = Integer.parseInt(e2.getTextContent());
else if(e2.getNodeName().equals("xmax"))
xmax = Integer.parseInt(e2.getTextContent());
else if(e2.getNodeName().equals("ymax"))
ymax = Integer.parseInt(e2.getTextContent());
}
}
if(xmin!=-1 && ymin!=-1 && xmax!=-1 && ymax!=-1)
{
String qwerty = "0 "+convert(width, height, xmin, ymin, xmax, ymax);
boxList.add(qwerty);
}
else
{
System.out.println("Could not find proper values");
System.out.println(path);
System.exit(1);
}
}
}
}
}
return boxList;
}
public static String convert(int width, int height, int xmin, int ymin, int xmax, int ymax)
{
double dw = 1.0/width;
double dh = 1.0/height;
double x = (xmin+xmax)/2.0;
double y = (ymin+ymax)/2.0;
double w = xmax - xmin;
double h = ymax - ymin;
x = x * dw;
w = w * dw;
y = y * dh;
h = h * dh;
return x+" "+y+" "+w+" "+h;
}
 AlexeyAB
AlexeyAB kmsravindra
kmsravindra

 sinaikh
sinaikh sharoseali
sharoseali MuhammadAsadJaved
MuhammadAsadJaved
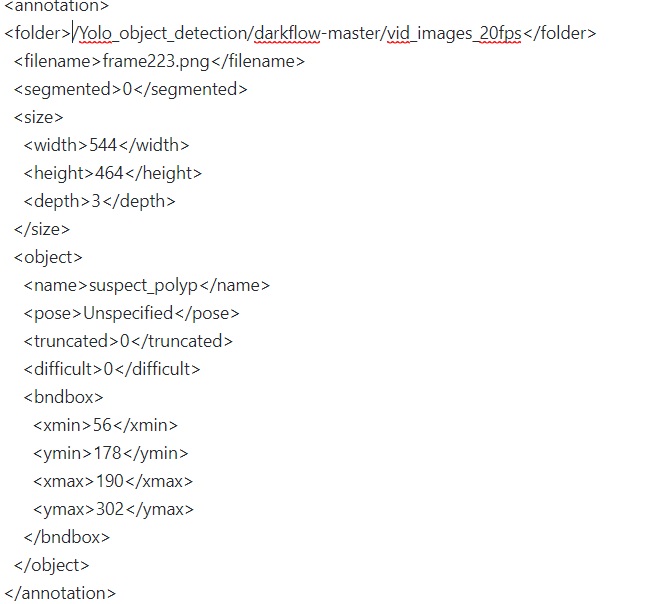
@AlexeyAB ,
I have used darkflow earlier and I wanted to make a switch to your library as this performs great with lot of options! So, I already have several annotations that were done in .xml...The content looks like the below - Is there a script than can simply convert it to .txt file without having to use Yolo_mark? Otherwise I can write a script , if you can tell me what I need to take care of. Your help is much appreciated!