 Ameobea
commented
8 years ago
Ameobea
commented
8 years ago Lots of progress today.
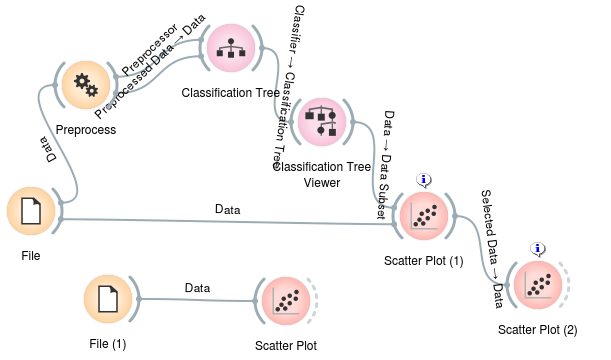
I worked extensively to both improve repr coverage for all preprocessors and learners. I've got pretty complete coverage of all the preprocessor objects as well as learners. Since I've been using the code generator to develop and test the reprs, I've committed changes to the code-generation branch and copied only changes that have to do with reprs into the repr branch.
Here's the comparison of the repr branch so far to the master branch I forked it from: https://github.com/Ameobea/orange3/compare/master...Ameobea:repr
In addition to the repr changes, I've also been working on integrating all of these changes into the current code generator. I've worked to improve dependency importing and clean up unnecessary code in as many places as possible. The generator is currently capable of, to my knowledge, creating scripts for any combination of learner-class widgets and preprocessors possible in addition to the few miscellaneous visualization and data widgets I've created generators for.
I think that, except for visualization widgets, there will be no need to construct widget objects for any other widgets (except visualizations) and expect the process of building code generators for them to be much quicker than before due to the higher quality generator and repr backend.
{kind=link}
┆Issue is synchronized with this Asana task