 Ameobea
commented
8 years ago
Ameobea
commented
8 years ago Today, I created code gen inits for other widgets and got code generation for a complete workflow (image included below) working from start to finish. The only manual modifications I had to make were due to an input/output linker bug that I will fix soon. (Generated code is also linked below)
@kernc I read over your examples and proposed generation strategy a few times and think I have a bit more to say about my code generation model.
Instead, I propose there be no separate string-generating function in every widget, but that widgets define their "main", exportable functional behaviour in a separate method
I do not use a string generator function in each widget, nor do I use a singular "main" function that performs the widget's actions. Instead, I opted for a mix between the two that initializes a code generator object with data from the widget (including something that could be thought of as a "main" function") and provides ways to tweak and modify that information to produce clean and efficient code down the line.
Here's an example of the current code generator for owclassificationtreegraph, the visualizer for classification trees: (I've added in comments explaining what each part does)
def init_code_gen(self):
def pre():
qapp = QApplication([])
def pre2():
# Import code can't recognize constants, so import manually
from sklearn.tree._tree import TREE_LEAF
# "Main" function of the widget. This code is run during widget exection in the output script
def run():
# Construct a new classification tree graph
ow = OWClassificationTreeGraph()
ow.handleNewSignals()
# Add the input classifier from the parent widget
# This is linked by the code generator automatically to the variable `input_classifier`
ow.ctree(input_classifier)
# Display the visualization
ow.show()
qapp.exec()
update_selection(ow)
ow.handleNewSignals()
# Close the widget and proceed with execution
ow.saveSettings()
ow.onDeleteWidget()
gen = self.code_gen()
# Give the code generator a copy of the widget
gen.set_widget(self)
# Generate import statements for dependencies
gen.add_import([QApplication, OWClassificationTreeGraph, numpy])
# Insert the contents of the preamble functions at the beginning of the script if they're not already there
gen.add_preamble(pre)
gen.add_preamble(pre2)
# Set `run` as the main function
gen.set_main(run)
# Copy non-class functions from widget code into the output
gen.add_extern(self.update_selection)
gen.add_extern(_leaf_indices)
gen.add_extern(_subnode_range)
# Modify some lines to suit the classless execution environment
gen.null_ln("send(")
gen.add_repl_map(("self", "ow"))
# Link the output so it can be read by other widgets
gen.add_output("data", "data", iscode=True)
return genHere is the current version of the generated code produced by this workflow: 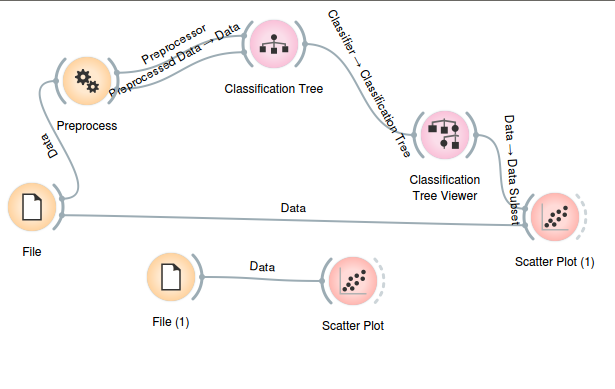
I will admit that this is almost certainly not the most efficient way to accomplish the task. However, I'm still not (anywhere near) 100% with my knowledge of Orange3 and I will continue to optimize and improve these as I continue development.
As I mentioned in the comments, linking of input and output channels is handled automatically by the code generator. The code generator and the code generator initializer functions are only called once during the code generation process don't interfere at all with other widget functionality.
Don't be afraid to modify widgets or to introduce/enforce conventions that you need to simplify this use case. The more declarative, the nicer.
Moving forward, I will consider more aggressive code generation techniques that could produce more efficient code by modifying the widget itself.
 kernc
kernc Pelonza
Pelonza
┆Issue is synchronized with this Asana task