 Bazist
commented
2 years ago
Bazist
commented
2 years ago Hi, it is very depend question. What kind of data we add. How many data we add. Have we delete scenarios in the middle of insertion process and etc.
In general we have next picture for memory: from overhead in 2-3 times to compression for some kind of keys. https://raw.githubusercontent.com/Bazist/HArray/master/Images/functionality2.png
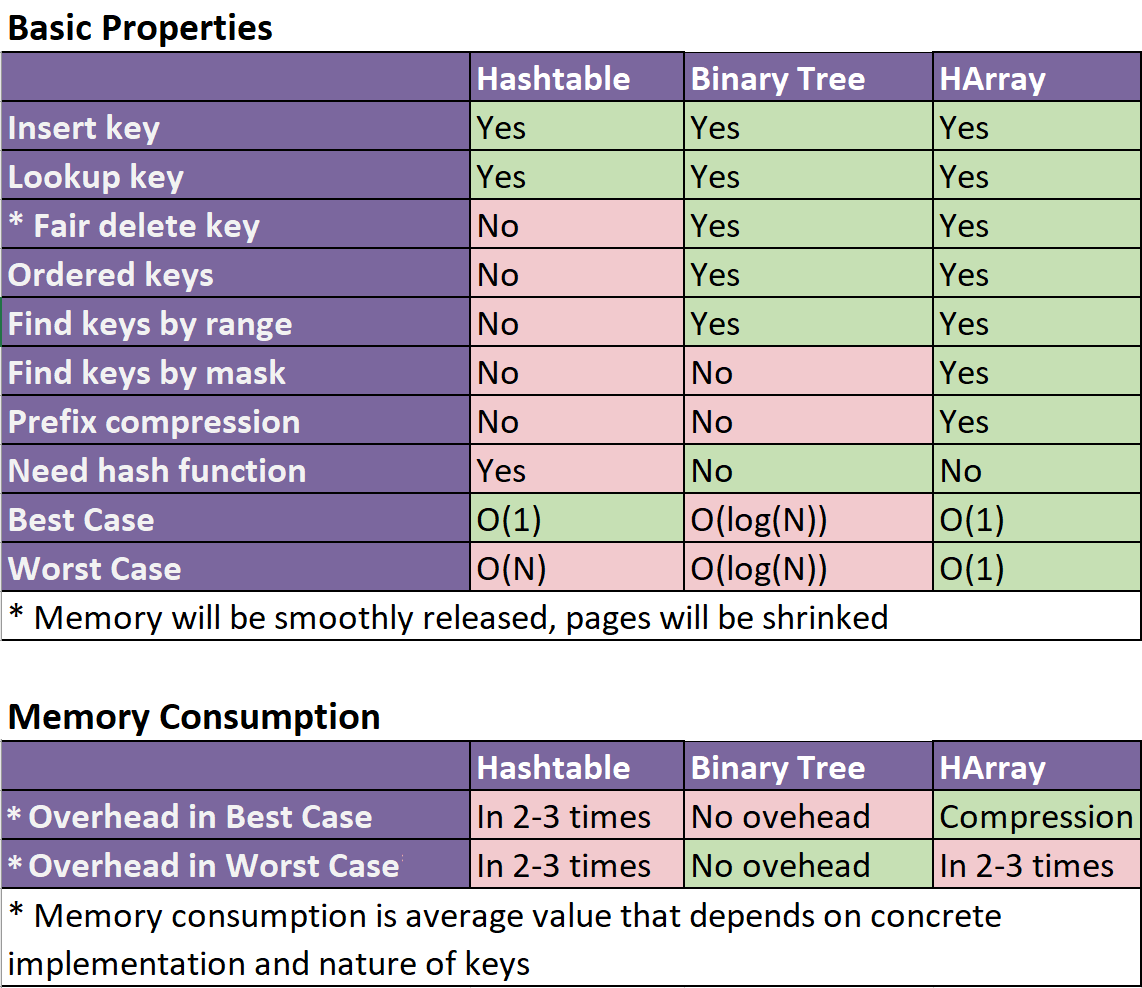{kind=link}
I didn't compare it with hat-trie, but I think hat-trie will be more effective for string keys in compression.
HArray is designed for binary data, as balanced structure between Insert/Delete/Update/Memory usage for large datasets (up to billions keys in one container). In compare to hat-trie it doesn't have any hash function, so we have set of analytical queries that is useful in database scenarios.
Here is list of advantages:
- Keys with variable length inside one instance of the container
- Without any Stop World events such as Rebuild/Rehashing on Insert key.
- Without any Hash Functions, the container has adpative algorithm for different nature of keys
- Scan by Prefix/Scan by Range functionality as bonus
- All Keys are sorted. Ability to set your Custom Order of Keys
- Predictable behaviour even in worst case: smoothly consuming memory, almost constantly latency on insert/lookup
- Prefix Compression helps reduce memory when keys have the same prefix: urls, file paths, words etc.
- Serialize/Deserialize from/to file at a speed close to the max speed of the hard drive
- Fair Delete operation with smoothly dismantling each Key. Dead fibres are used for insert new keys, so structure perfect works in massive insert/delete scenarios.
any memory usage compared with the rest?
how does it compare with https://github.com/Tessil/hat-trie ?