 Bryce1010
commented
4 years ago
Bryce1010
commented
4 years ago 算法岗面试准备,机器学习基础
算法岗
-
算法/深度学习/NLP面试笔记: [github]
-
AI Jobs Notes https://github.com/amusi/AI-Job-Notes 公式:刷题+背题+项目+实习(可选)+竞赛(可选)+顶会/顶刊(可选)
-
Deep Learning interview book https://github.com/amusi/Deep-Learning-Interview-Book
-
机器学习/算法校招面试考点 https://www.nowcoder.com/discuss/165930
面经
-
一个算法菜鸡的面试经验总结[blog]
-
深度学习500问 [github]
以问答形式对常用的概率知识、线性代数、机器学习、深度学习、计算机视觉等热点问题进行阐述,以帮助自己及有需要的读者。 全书分为18个章节,50余万字。由于水平有限,书中不妥之处恳请广大读者批评指正。 未完待续............ 如有意合作,联系scutjy2015@163.com 版权所有,违权必究 Tan 2018.06
机器学习
模型评估
本节将会涉及以下内容:
分类模型评估常用方法:Accuracy, Precision, Recall, P-R曲线, F1, Confusion Matrix, ROC, AUC ;
回归模型评估常用方法:MSE, MAE, R-Squard ;
误差,偏差和方差;过拟合和欠拟合;交叉验证;Unblanced Data;
| 指标 | 描述 |
|---|---|
| Accuracy | 准确率 |
| Precision | 精准度/查准率 |
| Recall | 召回率/查全率 |
| P-R曲线 | 查准率为纵轴,查全率为横轴,作图 |
| F1 | F1值 |
| Confusion Matrix | 混淆矩阵 |
| ROC | ROC曲线 |
| AUC | ROC曲线下的面积 |
回归模型常用评估方法:
| 指标 | 描述 |
|---|---|
| Mean Square Error (MSE, RMSE) | 平均方差 |
| Absolute Error (MAE, RAE) | 绝对误差 |
| R-Squared | R平方值 |
查准率和查全率(precision&recall)
ROC和AUC
F1-score
解决unbalanced data的方法
-
数据扩增数据集; -
数据对大类样本欠采样;代表算法:EasyEnsemble。其思想是利用集成学习机制,将大类划分为若干个集合供不同的学习器使用。相当于对每个学习器都进行欠采样,但对于全局则不会丢失重要信息。
-
数据对小类样本过采样;代表算法:SMOTE和ADASYN。
SMOTE:通过对训练集中的小类数据进行插值来产生额外的小类样本数据。
新的少数类样本产生的策略:对每个少数类样本a,在a的最近邻中随机选一个样本b,然后在a、b之间的连线上随机选一点作为新合成的少数类样本。
ADASYN:根据学习难度的不同,对不同的少数类别的样本使用加权分布,对于难以学习的少数类的样本,产生更多的综合数据。 通过减少类不平衡引入的偏差和将分类决策边界自适应地转移到困难的样本两种手段,改善了数据分布。 -
使用新评价指标;
类别不均衡评价指标
-
选择新算法;
不同的算法适用于不同的数据分布,应该用不同的算法进行比较
-
数据代价加权;
对小样本数据增加权值,降低大样本的权值影响,从而使得样本重点集中在小样本上
如何解决过拟合和欠拟合
如何解决欠拟合?
- 添加其他的特征
- 增加模型的复杂度
- 减小正则化系数
如何解决过拟合?
解决过拟合的方法主要有两个,一个是增加数据,另一个是做正则化;
数据重新清洗数据,数据不纯导致过拟合;数据较少样本的特征数;数据增加训练样本的数据;模型降低模型复杂度;正则化增大正则化的系数;正则化添加dropout方法;让神经元以一定的概率处于不工作的状态;early stoping- 用pretrained方法,得到一个好的初始化参数;
- 在训练过程中增加OHEM
- 在训练过程中,增加Label smoothing
- 对于Unbalanced data,还可以尝试把loss函数变为focal loss
- 正则化还可以做model ensemble
- 正则化还可以在测试阶段做交叉验证
- 正则化还可以在测试阶段做TTA
支持向量机
支持向量机是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是边界最大化,最终转化为一个凸二次规划问题来求解.
聚类和降维
本节将会将会涉及以下内容:
维数灾难,常用的聚类方法,降维方法
-
为什么会产生维数灾难?
特征数多样本密度假设在分类人物场景下,在低维空间中,样本特征数量少,分类任务难度大;所以容易想到增加特征数量,扩充维度空间,在高纬度中,特征数增加,样本区分度更高,分类任务难度降低。但是换个角度来看,在低纬度情况下样本的密度大,区分度小;在高维空间,样本密度小,样本空间稀疏,区分度大。但是如果样本空间的的维数太大,导致样本密度过于稀疏,造成分类器学习到一些过于特殊的样本,造成过拟合的现象。那么这种现象怎么来避免呢?
-
怎样避免维数灾难?
降维一般维数灾难的原因是特征数太多,维数太大,通过降维避免。常用方法有主成分分析法(PCA),线性判别法(LDA),奇异值分解简化数据,拉普拉斯特征映射等。
-
聚类和降维的关系?
数据点数据特征聚类方法降维方法聚类是针对数据点的操作,而降维是针对数据特征的操作;常用的聚类方法有K-Means,层次聚类和基于密度的聚类等;常用的降维方法有PCA,lsomap,LLE等。
四种常用聚类算法
- K-Means聚类
-
原理
$$ E=\sum{i=1}^{k}\sum{p\in C_i}\left|p-m_i\right|^2 $$
这里E是数据中所有对象的平方误差的总和,p是空间中的点,$m_i$是簇$C_i$的平均值
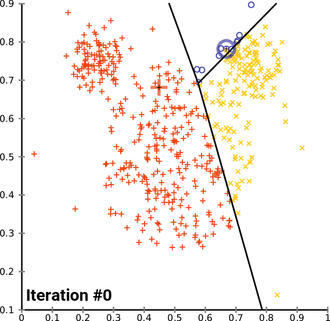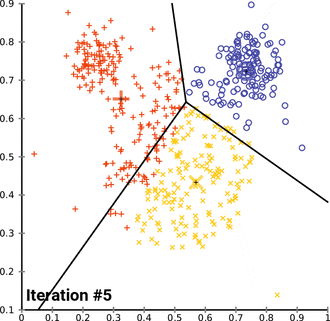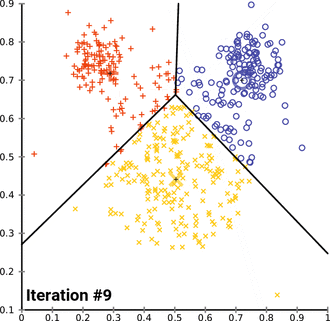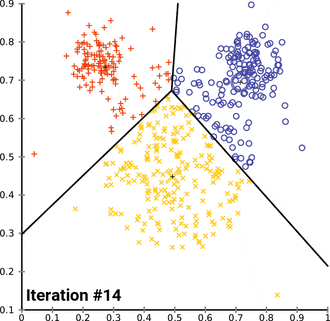
-
算法步骤
首先随机选取k个对象,然后n个对象初始化的分配给这k各族,代表每个族的平均值或中心点;
然后对剩余的所有对象,根据其到不同族中心的距离,将它赋给最近的族,重新计算每个族的平均值或中心;
迭代进行这两个步骤直到族中心不再变化。
-
代码实现
#创建k个点作为初始的质心点(随机选择) #当任意一个点的簇分配结果发生改变时 #对数据集中的每一个数据点 #对每一个质心 #计算质心与数据点的距离 #将数据点分配到距离最近的簇 #对每一个簇,计算簇中所有点的均值,并将均值作为质心import math import matplotlib.pyplot as plt import random def getEuclidean(point1, point2): dimension = len(point1) dist = 0.0 for i in range(dimension): dist += (point1[i] - point2[i]) ** 2 return math.sqrt(dist) def k_means(dataset, k, iteration): #初始化簇心向量 index = random.sample(list(range(len(dataset))), k) vectors = [] for i in index: vectors.append(dataset[i]) #初始化标签 labels = [] for i in range(len(dataset)): labels.append(-1) #根据迭代次数重复k-means聚类过程 while(iteration > 0): #初始化簇 C = [] for i in range(k): C.append([]) for labelIndex, item in enumerate(dataset): classIndex = -1 minDist = 1e6 for i, point in enumerate(vectors): dist = getEuclidean(item, point) if(dist < minDist): classIndex = i minDist = dist C[classIndex].append(item) labels[labelIndex] = classIndex for i, cluster in enumerate(C): clusterHeart = [] dimension = len(dataset[0]) for j in range(dimension): clusterHeart.append(0) for item in cluster: for j, coordinate in enumerate(item): clusterHeart[j] += coordinate / len(cluster) vectors[i] = clusterHeart iteration -= 1 return C, labels
-
层次聚类算法
凝聚将所有对象看成单独的一个类,计算两两之间的距离,将距离最小的两类合并成一个新类;重新计算新类与其他所有类的距离,重复以上步骤,直至所有类最后合并成要求的类别数量。
-
SOM聚类算法
self-Organization Maps
(1) 网络初始化,对输出层每个节点权重赋初值; (2) 从输入样本中随机选取输入向量并且归一化,找到与输入向量距离最小的权重向量; (3) 定义获胜单元,在获胜单元的邻近区域调整权重使其向输入向量靠拢; (4) 提供新样本、进行训练; (5) 收缩邻域半径、减小学习率、重复,直到小于允许值,输出聚类结果。
-
FCM聚类算法
Fuzzy C-Means(1) 标准化数据矩阵; (2) 建立模糊相似矩阵,初始化隶属矩阵; (3) 算法开始迭代,直到目标函数收敛到极小值; (4) 根据迭代结果,由最后的隶属矩阵确定数据所属的类,显示最后的聚类结果。
-
四种聚类算法比较
| 聚类方法 | 聚错样本数 | 运行时间/s | 平均准确率/(%) |
|---|---|---|---|
| K-Means | 17 | 0.146001 | 89 |
| 层次聚类 | 51 | 0.128744 | 66 |
| SOM | 22 | 5.267283 | 86 |
| FCM | 12 | 0.470417 | 92 |
两种常用的降维方法
-
PCA
- PCA思想总结
- PCA算法推理
- PCA算法流程
-
LDA
- LDA核心思想 我们以分类为例, 将高维空间的特征属性映射到低维或者是一维空间, 然后使得类内的数据点尽可能的接近, 而类间的数据点尽可能的原理, 当我们采用测试点进行测试的时候, 也将其投影到这样一条直线上, 根据投影点的位置来确定类别.
- LDA算法原理
- LDA算法流程







 第一步, 读入 h_{t-1} 和 输入x_t, sigmoid得到 it 表示要更要什么?
第二步, 读入h{t-1}和输入x_t, tanh得到一个替代的细胞状态 \hat{C_t}
第三步,结合遗忘们和输入门, 决定遗忘什么, 更新什么, 然后得到输出结果C_t
第一步, 读入 h_{t-1} 和 输入x_t, sigmoid得到 it 表示要更要什么?
第二步, 读入h{t-1}和输入x_t, tanh得到一个替代的细胞状态 \hat{C_t}
第三步,结合遗忘们和输入门, 决定遗忘什么, 更新什么, 然后得到输出结果C_t




找工作面试经验记录
自我介绍
时长:3 Min
Detection方向。
在科研方面:
个人博客
简历
面试准备
找到一个自己突出的方向,比较重要