 Bryce1010
commented
4 years ago
Bryce1010
commented
4 years ago 找工作,刷题记录
leetcode [77]
- 表示写过且一次性过
- [x] 表示已经写过,但是需要复习
- [ ] 表示还没写过
LeetCode 周赛
第 178 场周赛
- [x] 5346. 二叉树中的列表
bfs+dfs - [ ] 5347. 使网格图至少有一条有效路径的最小代价
bfs+dfs最短路0-1BFS[题解]结论,复习树上搜索和图论
第 177场周赛
-
- 日期之间隔几天
-
- 验证二叉树
-
- 最接近的因数
-
- 形成三的最大倍数
第 176 场周赛
Ref
STL
1. heap
/*
堆
常用有两种构建堆的方式:
1. 使用“优先队列”
2. 使用`make_heap` (todo)
*/
#pragma once
#include "../../all.h"
#include <queue>
using namespace std;
class Solution {
public:
struct node {
int v1;
int v2;
//bool operator () (const node &l, const node &r) {
// return l.v1 != r.v1 ? l.v1 < r.v1 : l.v2 < r.v2;
//}
};
// 仿函数比较器 - 降序
struct cmp {
bool operator () (int l, int r) {
return l > r;
}
};
// 自定义比较:先比较元素 1,再比较元素 2
struct cmp2 {
bool operator () (const node &l, const node &r) {
return l.v1 != r.v1 ? l.v1 < r.v1 : l.v2 < r.v2;
}
};
void test() {
// vector 转优先队列
// 如果是传统 ACM 的数据读取方式,可以不必这么做,在读取数据时,直接传入优先队列
// 如果是 LeetCode 的方式,如果直接接受的是一个 vec 参数,那么可能需要用到这种方法
vector<int> v1 = { 1,2,3 };
//priority_queue<int> p1(v1); // 没有直接将 vec 转 pri_que 的构造
priority_queue<int> p1(v1.begin(), v1.end());
cout << p1.top() << endl; // 3
// 添加数据
p1.push(5);
// 获取顶部数据
auto top = p1.top();
cout << top<< endl; // 5
// 弹出顶部数据
p1.pop(); // 没有返回值,所以如果要使用顶部的数据,需要先接收
// 数组转优先队列
int arr[] = { 1,2,3 };
priority_queue<int, vector<int>, cmp> p2(arr, arr + 3); // 使用仿函数构建最小堆,默认最大堆
cout << p2.top() << endl; // 1
// 自定义结构体
node arr2[] = { {1, 1}, {2, 2}, {2, 4}, {2, 3}, {1, 2} };
priority_queue<node, vector<node>, cmp2> p3(arr2, arr2 + 5);
p3.pop(); // {2, 4}
p3.pop(); // {2, 3}
p3.pop(); // {2, 2}
p3.pop(); // {1, 2}
p3.pop(); // {1, 1}
}
};2. list
/*
链表常用操作:
1. 前插
2. 尾插
3. 指定位置插入
4. 查找
5. 删除
6. 移除全部某个值
链表的使用频率不高
注意:
链表的迭代器不支持随机存取,即 `l.begin() + 1` 这种操作
*/
#pragma once
#include "../../all.h"
#include <list>
using namespace std;
class Solution {
public:
void test() {
list<int> l1{ 1,2,3,4,5 };
// 前插
l1.push_front(0);
// 获取第一个元素
auto top = l1.front();
cout << top << endl; // 0
// 弹出第一个元素
l1.pop_front();
cout << l1.front() << endl; // 1
// 尾插
l1.push_back(6);
// 获取最后一个元素
auto back = l1.back();
cout << back << endl; // 6
// 弹出最后一个元素
l1.pop_back();
cout << l1.back() << endl; // 5
// 删除
auto ret = find(l1.begin(), l1.end(), 3);
cout << *ret << endl;
l1.erase(ret);
ret = find(l1.begin(), l1.end(), 3);
if (ret == l1.end())
cout << "have erase 3" << endl;
// 移除某个值,会全部移除,如果该值不存在,无返回值
ret = find(l1.begin(), l1.end(), 5);
cout << *ret << endl;
l1.push_back(5); // 再添加一个 5
l1.push_back(5); // 再添加一个 5
cout << l1.size() << endl; // 6
l1.remove(5); // 移除所有 5
cout << l1.size() << endl; // 3
ret = find(l1.begin(), l1.end(), 5);
if (ret == l1.end())
cout << "have remove all 5" << endl;
// 插入 - 有 4 种插入
l1.insert(l1.begin(), 3); // 1. 在开头插入 3
l1.insert(l1.begin(), 5, 3); // 2. 在开头插入 5 个 3
l1.insert(l1.begin(), l1.begin(), l1.end()); // 3. 在指定位置插入一个范围
l1.insert(l1.begin(), { 1,2,3 }); // 4. 在指定位置插入一个初始化列表
// 清空
l1.clear();
}
};3. map
/*
字典 map
注意:
map 没有内置通过 value 找 key 的方法
一种当然是迭代器遍历,
下面还介绍了一种更高级的方法,通过 lambda 表达式查找
*/
#pragma once
#include <map>
#include <iostream>
using namespace std;
class Solution {
public:
void test() {
// 构造函数
map<int, int> m1{ { 1,2 },{ 2,3 },{ 3,4 } };
map<int, int> m2(m1.begin(), m1.end());
map<int, int> m3(m2);
m3[1] = 3; // 更新
m3[4] = 5; // 插入,无返回值
// 插入,如果存在则插入失败;注意与 [] 的区别
pair<map<int, int>::iterator, bool> ret;
ret = m3.insert(pair<int, int>(1, 4));
if (ret.second == false)
cout << "exist" << endl;
// hint 插入(不常用)
auto it = m3.begin();
it = m3.insert(it, pair<int, int>(6, 7)); // 效率不是最高的
// 这个跟效率有关,不深入
// > 我在 stack overflow 上的提问:
// c++ - Does it matter that the insert hint place which is close the final place is before or after the final place? - Stack Overflow https://stackoverflow.com/questions/49653112/does-it-matter-that-the-insert-hint-place-which-is-close-the-final-place-is-befo
// C++11 新语法,更快
ret = m3.emplace(5, 6); // 插入成功
ret = m3.emplace(1, 4); // 插入失败,key=1 存在了
it = m3.emplace_hint(it, 8, 9); // hint 插入
// 删除 by key
m3.erase(3);
// 查找 by key
it = m3.find(7); // 删除 by iterator
if (it == m3.end())
m3[7] = 77;
// 查找 by value
// 遍历方法,略
// lambda 方法
int v = 77;
it = find_if(m3.begin(), m3.end(),
[v](const std::map<int, int>::value_type item) {
return item.second == v;
});
if (it != m3.end()) {
int k = (*it).first;
cout << k << endl; // 7
}
// 此外,还有函数对象的方式
// > C++ map 根据value找key - CSDN博客 https://blog.csdn.net/flyfish1986/article/details/72833001
for (auto& i : m3)
cout << i.first << ": " << i.second << endl;
}
};4. queue
- empty
- size
- front
- back
- push
- emplace
- pop
- swap
proority_queue
- empty
- size
- top
- push
- pop
- swap
/*
队列:
队列的性质是“先进先出”
队列包括常规的队列 queue 和双端队列 deque
queue 的内部就是 deque 实现的,
因为双端队列包括的队列的所有功能,所以推荐使用 deque —— 它会使用 _front 和 _back 来区分头插和尾插
因为 list 也满足 queue 的接口,所以可以使用 list 作为 queue 背后的容器
*/
#pragma once
#include <list>
#include <deque>
#include <vector>
#include <queue>
#include <iostream>
#include <memory>
using namespace std;
class Solution {
public:
void test() {
// 双端队列
deque<int> d1 = { 1,2,3 };
d1.push_front(0); // {0,1,2,3}
for (auto i : d1)
cout << i << ' ';
cout << endl;
auto front_val = d1.front();
d1.pop_front(); // {1,2,3}
for (auto i : d1)
cout << i << ' ';
cout << endl;
// 一般队列
queue<int> q1(d1);
q1.push(12);
// 因为 list 也满足 queue 的接口,所以可以使用 list 作为 queue 背后的容器
list<int> l = { 1,2,3,4,5 };
queue<int, list<int>> q2(l);
//queue<int> q3{ 1,2,3 }; // error,没有相应的构造函数
//queue<int, vector<int>> q4; // warning
}
};
////优先队列
5. set [doc]
- begin
- end
- rbegin
- rend
- empty
- size
- insert
- erase
- swap
- clear
- find
- count
- lower_bound
- upper_bound
- equal_range
multiset
/*
集合 set
set 和 map 基本一致,相当于没有 value 的 map,或者说的 map 的 key 就是一个 set
因此,set 跟 map 的 key 一样是不允许重复的
如果需要重复,可以使用 multiset
set 的内部实现默认是红黑树——Python 默认是 HashSet
因此 set 中的元素是默认有序的——升序
如果需要降序的 set,可以使用仿函数
~~STL 也提供了 hash_set 的实现~~
STL 已经移除了 hash_set,改用 unordered_set 实现 Hash Set(可能)
注意:使用 unordered_set 并不会改变插入元素的顺序,这一点跟 Python 中的 set 不太一样——注意:但如果使用 Ipython,它会自动帮你有序显示
C++:
vector<char> vc{ 'a', 'r', 'b', 'c', 'd' };
unordered_set<char> hs(v.begin(), v.end());
for (auto i : hs)
cout << i << ' '; // a b r c d
cout << endl;
hs.emplace('e');
for (auto i : hs)
cout << i << ' '; // a b r c d e 插入位置不变
cout << endl;
Python:
>>> a = set('abracadabra')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a.add('e')
>>> a
{'a', 'e', 'r', 'b', 'c', 'd'} # 'e' 的插入位置变了,但是无序
Ipython:
In [1]: a = set('abracadabra')
In [2]: a
Out[2]: {'a', 'b', 'c', 'd', 'r'}
In [3]: a.add('e')
In [4]: a
Out[4]: {'a', 'b', 'c', 'd', 'e', 'r'} # 'e' 的插入位置变了,有序
*/
#pragma once
#include "../../all.h"
#include <set>
#include <unordered_set> // #include <hash_set>
using namespace std;
class Solution {
public:
struct cmp {
bool operator () (int l, int r) {
return l > r;
}
};
void test() {
set<int> s1;
set<int> s2{ 3,1,2 };
vector<int> v { 3,2,1,5,4 };
set<int> s3(v.begin(), v.end());
set<int, cmp> s4(v.begin(), v.end()); // 利用仿函数构造降序集
set<int, greater<int>> s5(v.begin(), v.end()); // STL 提供的 greater 仿函数
// 正序遍历
for (auto i : s3)
cout << i << ' ';
cout << endl;
// 逆序遍历
for (auto it = s4.rbegin(); it != s4.rend(); it++)
cout << *it << ' ';
cout << endl;
//size
len=s2.size()
// 增
s2.insert(4); // {1,2,3,4}
// 删
s2.erase(3); // {1,2,4}
// 改
auto it = s2.find(4);
if (it != s2.end()) { // 找到了
//
}
// 查
auto ii = s2.count(4);
for (auto i : s2)
cout << i << ' ';
cout << endl;
// 允许重复的集合
multiset<int> ms1{ 1,2,2,2,3,4 };
auto itp1 = ms1.find(2); // No.2
auto itp2 = ms1.lower_bound(2); // No.2
cout << (itp1 == itp2) << endl; // True
auto itp3 = ms1.upper_bound(2); // No.5
cout << *itp3 << endl; // 3
// Hash Set
vector<char> vc{ 'a', 'r', 'b', 'c', 'd' };
unordered_set<char> hs(vc.begin(), vc.end());
for (auto i : hs)
cout << i << ' '; // a b r c d
cout << endl;
hs.emplace('e');
for (auto i : hs)
cout << i << ' '; // a b r c d e
cout << endl;
}
};6. stack
/*
栈 stack
栈的性质是“先进后出”
其内部是使用双端队列 deque 实现的,屏蔽了部分接口
*/
#pragma once
#include <list>
#include <vector>
#include <stack>
#include <iostream>
using namespace std;
class Solution {
public:
void test() {
stack<int> s1;
s1.push(1);
s1.push(2);
s1.push(3);
// pop() 没有返回值,因此如果需要使用弹出的值,需要先接收
auto top_val = s1.top(); // 3
s1.pop();
// 可以使用 deque 来构造 stack
deque<int> d1 = { 1,2,3 };
stack<int> s2(d1);
s2.push(4);
top_val = s2.top(); // 4
s2.pop(); // {1,2,3}
}
};7. vector
- begin
- end
- rbegin
- rend
- size
- max_size
- resize
- empty
- at
- front
- back
- data
- push_back
- pop_back
- insert
- swap
- clear
/*
向量/动态数组
最常用的容器
*/
#pragma once
#include <vector>
#include <iostream>
#include <algorithm>
#include <functional>
using namespace std;
class Solution {
public:
bool is_in(vector<int> v, int target) {
auto it = v.begin();
for (; it != v.end(); it++)
if (*it == target)
break;
return it != v.end();
}
void test() {
vector<int> v1; // {}
vector<int> v2 = { 1,2,3,4 };
vector<int> v3(3, 10); // {10,10,10}
vector<int> v4(v2.begin() + 1, v2.end()); // {2,3,4}
vector<int> v5(v4); // {2,3,4}
// 尾插
v1.push_back(3);
v1.push_back(2);
v1.push_back(1);
v1.pop_back();
for (auto i : v1)
cout << i << ' ';
cout << endl;
// 头插、指定位置插入
v1.insert(v1.begin() + 1, 0);
v1.insert(v1.begin() + 1, v2.begin(), v2.end());
v1.insert(v1.end(), v2.begin(), v2.end());
auto it = v1.erase(v1.begin() + 1);
cout << *it << endl;
for (auto i : v1)
cout << i << ' ';
cout << endl;
// 删除
vector<int> v6 = { 1,2,3,4,5 };
v6.erase(v6.begin() + 1); // { 1,3,4,5 }
v6.erase(v6.begin() + 1, v6.begin() + 3); // { 1,5 }
v6.clear();
for (auto i : v6)
cout << i << ' ';
cout << endl;
// 查找
it = find(v2.begin(), v2.end(), 5);
if (it != v2.end()) { // 找到了,必须做一次判断,以防空迭代器异常
//
}
// 获取数组大小
cout << "v4 size: " << v4.size() << endl;
// 整个数组交换
v1.swap(v2);
v2.swap(v1);
// 交换内部元素
swap(v2[1], v2[2]);
swap(v2[1], v2[2]);
// 不同的遍历方法
cout << "v3: ";
for (auto i : v3)
cout << i << ' ';
cout << endl;
cout << "v4: ";
for (size_t i = 0; i < v4.size(); i++)
cout << v4[i] << ' ';
cout << endl;
cout << "v5: ";
for (auto it = v5.begin(); it != v5.end(); it++)
cout << *it << ' ';
cout << endl;
cout << "r v5: "; // 逆序遍历
for (auto it = v5.rbegin(); it != v5.rend(); it++)
cout << *it << ' ';
cout << endl;
// 获取第一个/最后元素
v2.front() = 12; // 因为返回的是引用,所以可以直接修改
v2.back() -= v2.front();
cout << v2.front() << ", " << v2.back() << endl;
// 判断空
if (v1.empty())
cout << "v1 is empty" << endl;
// 排序
// 默认升序
sort(v2.begin(), v2.end());
// 降序
sort(v2.begin(), v2.end(), greater<int>());
// 自定义排序
typedef pair<int, int> ii;
vector<ii> vp{ { 1,1 },{ 1,2 },{ 2,2 },{ 2,3 },{ 3,3 } };
sort(vp.begin(), vp.end(), [](const ii &l, const ii &r) { // 按第一个数字升序,第二个降序
return l.first != r.first ? l.first < r.first : l.second > r.second;
});
for (auto i : vp)
cout << '{' << i.first << ',' << i.second << "} ";
cout << endl;
}
};
8. STL数据结构
- [x] (List)Leetcode 24. 两两交换链表中的节点 [problem] [[迭代解法]] [[递归解法]]
递归回溯
递归回溯一般模板:
'''
backtracking使用dfs的模板,基本跟dfs的模板一模一样
'''
class Backtracking(object):
def backtracking(self, input):
self.res = []
def dfs(input, temp, [index]):
# 边界
if 非法数据:
return
# 终止条件
if len(input) == len(temp):
self.res.append(temp[:])
return
# for循环
for i range(len(input)):
##1. 修改path
temp.append(input[i])
##2. backtracking
dfs(input, temp, [index])
##3. 退回原来状态,恢复path
temp.pop()
# 执行
dfs(input, [], 0)
return self.resString 字符串
- [x] 编辑距离 (f-zjy)
- [ ] KMP算法 [理解KMP]
暴力匹配
// 暴力匹配(伪码) int search(String pat, String txt) { int M = pat.length; int N = txt.length; for (int i = 0; i < N - M; i++) { int j; for (j = 0; j < M; j++) { if (pat[j] != txt[i+j]) break; } // pat 全都匹配了 if (j == M) return i; } // txt 中不存在 pat 子串 return -1; }KMP代码:
搜索
参考如下:
- 夜深人静写算法-搜索 [blog]
1. DFS
算法描述
DFS的算法具体描述为选择一个起点v作为当前节点,执行如下操作:
a. 访问当前节点,并且标记当前节点已被访问过,然后跳转到b;
b. 如果存在一个和当前节点相邻并且尚未被访问的节点u,则将节点u设为当前节点,继续执行a;
c. 如果不存在这样的u,则进行回溯,回溯的过程就是回退当前节点;
上述当前节点需要用一个栈来维护,每次访问到得到节点入栈,回溯的时候出栈(也可以用递归来实现,更佳直观和方便)。
- DFS实现
def DFS(v): vistited[v]=true dosomething() for u in adjcent_list[v]: if visited[v] is false: DFS(u) //其中dosomething 表示访问时具体要干的事,根据情况而定,并DFS是可以有返回值的;
基础应用
- 求N的阶乘;
//f(n)=n*f(n-1), n>0 - 求斐波那契数列的第N项
//f(n)=f(n-1)+f(n-2), n>2,f(0)=f(1)=1 //记忆化搜索 - 求n个数的全排列
//建立全连接图
DFS高级应用
- 枚举
数据较小的排列、组合的穷举; - 容斥原理
利用深搜计算一个公式,本质上还是枚举; - 基于状态压缩的动态规划
一般解决棋盘摆放问题,k进制表示状态,然后利用深搜进行状态转移; - 记忆化搜索
某个状态被计算过了,就将它cache住,下次要用到的时候就不需要再一次计算; - 有向图的强连通分量
经典的Tarjan算法;
求解2-sat问题的基础; - 无向图割边割点和双连通分量
经典的Tarjan算法; - LCA
最近公共祖先递归求解; - 博弈
利用深搜计算SG值; - 二分图最大匹配
经典的匈牙利算法;
最小顶点覆盖,最大独立集,最小值支配集向二分图的转化; - 欧拉回路
经典的圈套圈算法; - K短路
依赖数据,数据不卡的话可以采用二分答案+深搜或者广搜+A*; - 线段树
二分经典思想,配合枚举深搜左右子树; - 最大团
极大完全子图的优化算法; - 最大流
EK算法求任意路径中有涉及; - 树形DP
即树形动态规划;父节点的值由各子节点计算得出;
1.1 基于DFS的记忆化搜索
1.2 基于DFS的剪枝
好的剪枝可以大大提升程序的运行效率,那么问题来了,如何进行剪枝?我们先来看剪枝需要满足什么原则:
a. 正确性
剪掉的子树中如果存在可行解(或最优解),那么在其它的子树中很可能搜不到解导致搜索失败,所以剪枝的前提必须是要正确;
b. 准确性
剪枝要“准”。所谓“准”,就是要在保证在正确的前提下,尽可能多得剪枝。
c. 高效性
剪枝一般是通过一个函数来判断当前搜索空间是否是一个合法空间,在每个结点都会调用到这个函数,所以这个函数的效率很重要。
-
可行性剪枝
可行性剪枝一般是处理可行解的问题,如一个迷宫,问能否从起点到达目标点之类的。 -
最优化剪枝
最优性剪枝一般是处理最优解的问题。以求两个状态之间的最小步数为例,搜索最小步数的过程:一般情况下,需要保存一个“当前最小步数”,这个最小步数就是当前解的一个下界d。在遍历到搜索树的叶子结点时,得到了一个新解,与保存的下界作比较,如果新解的步数更小,则令它成为新的下界。搜索结束后,所保存的解就是最小步数。而当我们已经搜索了k歩,如果能够通过某种方式估算出当前状态到目标状态的理论最少步数s时,就可以计算出起点到目标点的理论最小步数,即估价函数h = k + s,那么当前情况下存在最优解的必要条件是h < d,否则就可以剪枝了。最优性剪枝是不断优化解空间的过程。
1.3 基于DFS的A算法 (迭代加深IDA)
1) 算法原理
迭代加深分两步走:
- 枚举深度。
- 根据限定的深度进行DFS,并且利用估价函数进行剪枝。
DFS题集
Leetcode DFS:
ACM DFS:
-
[x] Red and Black ★☆☆☆☆ FloodFill
-
[ ] The Game ★☆☆☆☆ FloodFill
-
[ ] Frogger ★☆☆☆☆ 二分枚举答案 + FloodFill
-
[ ] Nearest Common Ancestors ★☆☆☆☆ 最近公共祖先
-
[ ] Robot Motion ★☆☆☆☆ 递归模拟
-
[ ] Dessert ★☆☆☆☆ 枚举
-
[ ] Matrix ★☆☆☆☆ 枚举
-
[ ] Frame Stacking ★☆☆☆☆ 枚举
-
[ ] Transportation ★☆☆☆☆ 枚举
-
[ ] Pairs of Integers ★★☆☆☆ 枚举
-
[ ] Machine Schedule ★★★☆☆ 二 IDA*(确定是迭代加深后就一个套路,枚举深度,然后 暴力搜索+强剪枝)
-
[ ] Addition Chains ★★☆☆☆
-
[ ] DNA sequence ★★☆☆☆
-
[ ] Booksort ★★★☆☆
中序遍历
递归法
public void helper(TreeNode* root, vector<int>res){
if(root!=NULL){
if(root->left!=NULL)helper(root->left,res);
res.push_back(root->val);
if(root->right!=NULL)helper(root->right,res);
}
}基于栈的遍历
TreeNode* current=root;
stack<TreeNode*>stack;
while(current!=NULL||!stack.empty()){
while(current!=NULL){
stack.push(current);
cuttent=current->left;
}
res.push_back(current->val);
current=current->right;
}2. BFS
BFS的具体算法描述为选择一个起始点v放入一个先进先出的队列中,执行如下操作:
a. 如果队列不为空,弹出一个队列首元素,记为当前结点,执行b;否则算法结束;
b. 将与 当前结点 相邻并且尚未被访问的结点的信息进行更新,并且全部放入队列中,继续执行a;
维护广搜的数据结构是队列和HASH,队列就是官方所说的open-close表,HASH主要是用来标记状态的,比如某个状态并不是一个整数,可能是一个字符串,就需要用字符串映射到一个整数,可以自己写个散列HASH表,不建议用STL的map,效率奇低。
算法实现
广搜一般用队列维护状态,写成伪代码如下:
def BFS(v):
resetArray(visited,false)
visited[v] = true
queue.push(v)
while not queue.empty():
v = queue.getfront_and_pop()
for u in adjcent_list[v]:
if visited[u] is false:
dosomething(u)
queue.push(u)基础应用
- 最短路:bellman-ford最短路的优化算法SPFA,主体是利用BFS实现的。
绝大部分四向、八向迷宫的最短路问题。 - 拓扑排序:
首先找入度为0的点入队,弹出元素执行“减度”操作,继续将减完度后入度为0的点入队,循环操作,直到队列为空,经典BFS操作; - FloodFill:
经典洪水灌溉算法; - 0-1BFS [01BFS tutorial]
高级应用
- 差分约束:
数形结合的经典算法,利用SPFA来求解不等式组。 - 稳定婚姻:
二分图的稳定匹配问题,试问没有稳定的婚姻,如何有心思学习算法,所以一定要学好BFS啊; - AC自动机:
字典树 + KMP + BFS,在设定失败指针的时候需要用到BFS。
详细算法参见:http://www.cppblog.com/menjitianya/archive/2014/07/10/207604.html - 矩阵二分:
矩阵乘法的状态转移图的构建可以采用BFS; - 基于k进制的状态压缩搜索:
这里的k一般为2的幂,状态压缩就是将原本多维的状态压缩到一个k进制的整数中,便于存储在一个一维数组中,往往可以大大地节省空间,又由于k为2的幂,所以状态转移可以采用位运算进行加速,HDU1813和HDU3278以及HDU3900都是很好的例子;
2.1 基于BFS的A*算法
在搜索的时候,结点信息要用堆(优先队列)维护大小,即能更快到达目标的结点优先弹出。
BFS题集
-
[ ] Pushing Boxes ★☆☆☆☆ 经典广搜 - 推箱子
-
[ ] Jugs ★☆☆☆☆ 经典广搜 - 倒水问题
-
[ ] Space Station Shielding ★☆☆☆☆ FloodFill
-
[ ] Knight Moves ★☆☆☆☆ 棋盘搜索
-
[ ] Knight Moves ★☆☆☆☆ 棋盘搜索
-
[ ] Eight ★★☆☆☆ 经典八数码
-
[ ] Currency Exchange ★★☆☆☆ SPFA
-
[ ] The Postal Worker Rings ★★☆☆☆ SPFA
2.2 双向广搜 (适用于起始状态都给定的问题,一般一眼就能看出来,固定套路,很难有好的剪枝)
初始状态 和 目标状态 都知道,求初始状态到目标状态的最短距离;
利用两个队列,初始化时初始状态在1号队列里,目标状态在2号队列里,并且记录这两个状态的层次都为0,然后分别执行如下操作:
a.若1号队列已空,则结束搜索,否则从1号队列逐个弹出层次为K(K >= 0)的状态;
i. 如果该状态在2号队列扩展状态时已经扩展到过,那么最短距离为两个队列扩展状态的层次加和,结束搜索;
ii. 否则和BFS一样扩展状态,放入1号队列,直到队列首元素的层次为K+1时执行b;
b.若2号队列已空,则结束搜索,否则从2号队列逐个弹出层次为K(K >= 0)的状态;
i. 如果该状态在1号队列扩展状态时已经扩展到过,那么最短距离为两个队列扩展状态的层次加和,结束搜索;
ii. 否则和BFS一样扩展状态,放入2号队列,直到队列首元素的层次为K+1时执行a;
-
[ ] Solitaire ★★★☆☆
-
[ ] A Game on the Chessboard ★★★☆☆
-
[ ] 魔板 ★★★★☆
-
[ ] Tobo or not Tobo ★★★★☆
-
[ ] Eight II ★★★★★
图论
一、最短路
1. Dijkstra算法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KE09cfBz-1586394424158)(https://upload.wikimedia.org/wikipedia/commons/thumb/5/57/Dijkstra_Animation.gif/220px-Dijkstra_Animation.gif)]
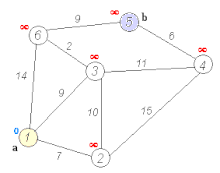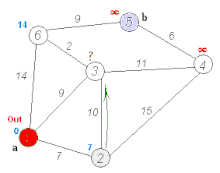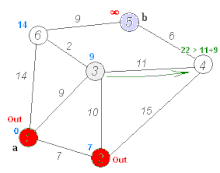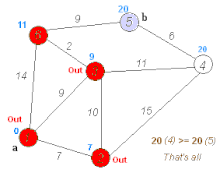{kind=link}
权值必须是非负的。
伪代码:
function Dijkstra(G,w,s): # G 表示图,w表示w(i,j)表示边权
Initialize-single-source(G,w)
S <- O
Q <- s
while(!Q):
do u <- Extract-Min(Q)
S <- S U u
for each vertex v from Adj[u]:
do Relax(u,v,w)
数组实现:
//单源最短路径,邻接矩阵形式,复杂度为O(n^2)
const int MAXN=1010;
const int INF=0x3f3f3f3f; //防止后面溢出,这个不能太大
bool vis[MAXN]; //vis记录了节点i是在Q中还是S中
#define typec int
int pre[MAXN]; // pred[i]记录beg到i路径上的父节点,pre[beg]=-1
void Dijkstra(typec cost[][MAXN],typec lowcost[],int n,int beg){
for(int i=0;i<n;++i){
lowcost[i]=INF;vis[i]=false;pre[i]=-1;
}
lowcost[beg]=0;
for(int j=0;j<n;++j){
int k=-1;
int Min=INF;
for(int i=0;i<n;++i){
if(!vis[i]&&lowcost[i]<Min){
Min=lowcost[i];
k=i;
}
}
if(k==-1)break;
vis[k]=true;
for(int i=0;i<n;++i){
if(!vis[i]&&lowcost[k]+cost[k][i]<lowcost[i]){
lowcost[i]=lowcost[k]+cost[k][i];
pre[i]=k;
}
}
}
}优先队列堆优化:
const int INF=0x3f3f3f3f;
const int MAXN=100010;
struct qnode{
int v;
int c;
qnode(int _v=0,int _c=0):v(_v),c(_c){}
bool operator < (const qnode& r)const{
return c>r.c;
}
};
struct Edge{
int v,cost;
Edge(int _v=0,int _cost=0):v(_v),cost(_cost){}
};
vector<Edge>E[MAXN];
bool vis[MAXN];
int dist[MAXN];
//点的编号从1开始
void Dijkstra(int n,int start){
memset(vis,false,sizeof(vis));
for(int i=1;i<=n;++i)dis[i]=INF;
priority_queue<qnode>que;
while(!que.empty())que.pop();
dis[start]=0;
que.push(qnode(start,0));
qnode tmp;
while(!que.empty()){
tmp=que.top();
que.pop();
int u=tmp.v;
if(vis[u])continue;
vis[u]=true;
for(int i=0;i<E[u].size();++i){
int v=E[tmp.v][i].v;
int cost=E[u][i].cost;
if(!vis[v]&&dist[u]+cost<dist[v]){
dist[v[=dist[u]+cost;
que.push(qnode(v,dist[v]));
}
}
}
}
void addedge(int u,int v,int w){
E[u].push_back(Edge(v,w));
}2. 单源最短路SPFA算法
权值可以使负值
时间复杂度O(kE)
队列实现,有时候改成栈实现会加快
允许多次扩展同一个点。只要当前边能够更新节点的权值,就将节点再次入队。(有点类似数组实现)
如果一个节点已经在队列中,其实就没有必要将其再次入队了,这是 SPFA 算法的基本思想。
const int MAXN=1010;
const int INF=0x3f3f3f3f;
struct Edge{
int v;
int cost;
Edge(int _v,int _cost):v(_v),cost(_cost){}
};
vector<Edge>E[MAXN];
void addedge(int u,int v,int w){
E[u].push_back(E(v,w));
}
bool vis[MAXN];//判断在队列标注
int cnt[MAXN];//判断每个点入队列次数,以判断是否存在负环回路
int dist[MAXN];
bool SPFA(int start, int n){
memset(vis,false,sizeof(vis));
for(int i=1;i<=n;++i)dist[i]=INF;
queue<int>que;
while(!que.empty())que.pop();
que.push(start);
vis[start]=true;
dist[start]=0;
memset(cnt,0,sizeof(cnt));
cnt[start]=1;
while(!que.empty){
int u=que.front();
que.pop();
if(vis[u])continue;
vis[u]=false;
for(int i=0;i<E[u].size();++i){
int v=E[u][i].v;
if(dist[u]+E[u][i].cost<dist[v]){
dist[v]=dist[u]+E[u][i].cost;
if(!vis[v]){
vis[v]=true;
que.push(v);
if(++cnt[v]>n)return false;
}
}
}
}
return true;
}二、最小生成树
三、次小生成树
四、 有向图的强连通分量
五、二分图匹配
六、 最大流
七、 最小费用最大流
动态规划 DP
ref:
- 夜深人静写算法——动态规划 [blog]
一、动态规划初探
1、递推
2、记忆化搜索
递推说白了就是在知道前i-1项的值的前提下,计算第i项的值,而记忆化搜索则是另外一种思路。它是直接计算第i项,需要用到第 j 项的值( j < i)时去查表,如果表里已经有第 j 项的话,则直接取出来用,否则递归计算第 j 项,并且在计算完毕后把值记录在表中。记忆化搜索在求解多维的情况下比递推更加方便。
-
[x] 87. 扰乱字符串 [problem]
-
[ ] Function Run Fun [proble] ★☆☆☆☆ 【例题3】
-
[ ] FatMouse and Cheese [problem] ★☆☆☆☆ 经典迷宫问题
-
[ ] Cheapest Palindrome [problem] ★★☆☆☆
-
[ ] A Mini Locomotive [problem] ★★☆☆☆
-
[ ] Millenium Leapcow [problem] ★★☆☆☆
-
[ ] Brackets Sequence [problem] ★★★☆☆ 经典记忆化
-
[ ] Chessboard Cutting [problem] ★★★☆☆ 《算法艺术和信息学竞赛》例题
-
[ ] Number Cutting Game [problem] ★★★☆☆
4、最优化原理和最优子结构
5、决策和无后效性
二、动态规划的经典模型
1、线性模型
3、状态和状态转移
4、最优化原理和最优子结构
5、决策和无后效性
二、动态规划的经典模型
1、线性模型
2、区间模型
3、背包模型
5、树状模型
三、动态规划的常用状态转移方程
1、1D/1D
2、2D/0D
3、2D/1D
4、2D/2D
四、动态规划和数据结构结合的常用优化
1、滚动数组
2、最长单调子序列的二分优化
3、矩阵优化
4、斜率优化
5、树状数组优化
6、线段树优化
7、其他优化
五、动态规划题集整理
精选技巧
1. 双指针
-
- 无重复字符的最长子串 [problem]
class Solution { public: int lengthOfLongestSubstring(string s) { int len=s.size(); int i=0,j=0; vector<int>vec(128,-1); int maxlen=0; while(i<len&&j<len){ char tmp=s[j]; if(vec[int(tmp)]>=i){ i=vec[int(tmp)]+1; } vec[int(tmp)]=j; maxlen=max(maxlen,j-i+1); j++; } return maxlen; } };
- 无重复字符的最长子串 [problem]
-
- 盛最多水的容器
class Solution { public: int maxArea(vector<int>& height) { int len=height.size(); int i=0,j=len-1; int maxArea=min(height[i],height[j])*(j-i); while(i<j){ if(height[i]>=height[j]){ j--; } else if(height[i]<height[j]){ i++; } maxArea=max(maxArea,min(height[i],height[j])*(j-i)); } return maxArea; } };
- 盛最多水的容器
2. 二分
-
左闭右开
[l,r)int l=0,r=n; while(l<r) { r=middle; l=middle+1; } -
左闭右闭
[l,r]int l=0,r=n-1; while(l<=r) { r=middle-1; l=middle+1; } -
左开右开
(l,r)int l=-1,r=n; while(l+1!=r) { r=middle; l=middle; } -
二分模板 (求非下降序列的首次首次出现的位置)
int binary(int array[],int n,int target) { int left,right,middle; left=-1,right=n; while(left+1!=right){ middle=left+(right-left)/2; if(array[middle]>=target){ right=middle; }else{ left=middle; } } if(right==n||array[right]!=target) return -1; return right; }
快速幂(也算是二分的一种思想)
Matrix quickPower(Matrix A, int k){
Matrix result=I;
while(k>0)
{
if(k%1==1)result=result*A;
k=k/2;
result=result*result;
}
return result;
}- 二分搜索题集 [leetcode]
3. 排序
- 归并排序
时间复杂度: O(nlogn)
归并排序是基于分治思想的排序方法。
归并排序a[l,r]的算法,简要描述为:
(1)将a[l,r]拆成a[l,mid],a[mid+1,r]两部分
(2)调用MergeSort(l,mid)和MerSort(mid+1,r),将这两部分分别排好序
(3)合并排好序的两部分,覆盖a[l,r]
关于合并过程:
(1)如果A取完,那么直接从B中取;
(2)如果B取完,那么直接从A中取;
(3)如果A,B都没取完,那么从A,B的头部,取更小的那个;int source[100],target[100]; void merge(int left,int mid,int right) { int i=left,j=mid+1,k=left; while(i<=mid&&j<=right) { if(source[i]<source[j]) { target[k++]=source[i++]; } else { target[k++]=source[j++]; } } while(i<=mid) { target[k++]=source[i++]; } while(j<=right) { target[k++]=source[j++]; } for(int ss=left;ss<=right;++ss) source[left]=target[left];
} void MergeSort(int left,int right) { int mid=(left+right)/2; MergeSort(left,mid); MergeSort(mid+1,right); merge(left,mid,right); }
- **快排**
时间复杂度:O(nlogn)
以身高排序为例:
(1)选择一个人
(2)将比这个人矮的放到左边去
(3)将比这个人高的放到右边去
(4)对这个人坐便和右边分别进行相似的递归排序
```cpp
template<class Type>
int partition(Type array[],int left,int right)
{
int flag=array[left];
while(left<right)
{
//put all x < flag to left
while(left<right&&array[right]>=flag)
{
right--;
}
if(left<right)
{
array[left]=array[right];
left++;
}
//put all x>flag to right
while(left<right&&array[left]<=flag)
{
left++;
}
if(left<right)
{
array[right] = array[left];
right--;3
}
}
//left and right 重合时,将flag放置中间
array[left]=flag;
return left;
}
template<class Type>
void quick_sort(Type array[],int left,int right)
{
if(left<right)
{
int position=partition(array,left,right);
quick_sort(array,left,position-1);
quick_sort(array,position+1,right);
}
}
Update
Leetcode
在线平台
教程
KuangBin ACM模板
算法竞赛入门经典
学习资源
OI wiki
[OI & ACM 课件分享]
Just Code [github]
fucking-algorithm [github]
写在20年初的校招面试心得与自学CS经验及找工作分享 [github]
labuladong的算法小抄 [github]