 CNugteren
commented
6 years ago
CNugteren
commented
6 years ago Agree, makes sense. I'll put it on the road map, probably for April/May
Closed Ulfgard closed 5 years ago
CNugteren
commented
6 years ago Agree, makes sense. I'll put it on the road map, probably for April/May
 Ulfgard
commented
6 years ago
Ulfgard
commented
6 years ago thanks! Please keep me in the loop. I would like to test it as soon as you have it working!
CNugteren
commented
6 years ago By the way, do you have any link to a reference API for this, e.g. from cuDNN or some other library? Just want to make sure I implement this using the preferred interface.
Ulfgard
commented
6 years ago Hi,
the cuDNN interface is horrible, see here for a somewhat minimal example:
https://gist.github.com/goldsborough/865e6717e64fbae75cdaf6c9914a130d starting at around line 62.
I am not a huge fan of many of the convolution extensions like striding or dilations, those things are what makes interfaces complex. I like different image ordering and i also like the distinction between convolution & cross-correlation, but i would rather put the latter in two different functions(the difference is flipping the filter and different padding for uneven pad-sizes). In terms of extensibility it is probably better to have a descriptor object, this way one could start minimal and expand from there.
 kodonnell
commented
6 years ago
kodonnell
commented
6 years ago This is something I was planning to try too (though I'd need to learn a lot first), so I'm definitely in favor. The response by Scott Gray here might be useful - though it was a bit above my level, so I'm not sure.
@Ulfgard - my use case (like most others, I imagine) is convolutional neural nets etc. - I'd say kernel size, padding (generally just 'SAME' or 'VALID'), and stride are the most common arguments, and I'd favour using them. I haven't seen e.g. dilation used yet.
@CNugteren - if implementing a convolution kernel, would it pay to look at other approaches, as well as im2col + gemm? There are heaps lying round, which you're probably more aware of them than me, but libDNN and clDNN (which has multiple kernels, including winograd) come to mind.
Ulfgard
commented
6 years ago @kodonnell At the level of such a routine, talking about padding at the level of "same" or "valid" is not sufficient, because "same" does not only decide the amount of padding, but also what to pad (pad with zero, pad by repeating the boundary, pad by using mirror-tiling...).
Even after we picked a padding algorithm, we can not just go with "either pad or don't pad" - if you want to implement a CNN, you need different amounts of padding for forward- and backpropagation.
If we pick "valid" for our CNN, once we backpropagate, we need to convolve the backpropagated derivatives (a smaller image) to the input. This requires a larger padding than for "same". See for example my implementation here: https://github.com/Shark-ML/Shark/blob/0bcedae001914bfcd8d5ea2be64ba94e8a11447e/include/shark/Models/ConvolutionalModel.h#L264
And if we pick "same" and the value of padding is not even, we have to decide on which side we pad more when computing the forward pass - and do it exactly the opposite way for backpropagation (which i am not doing correctly in my implementation). This can be resolved by treating the backpropagation pass as a cross-correlation.
kodonnell
commented
6 years ago pad with zero, pad by repeating the boundary, pad by using mirror-tiling...
I'd suggest padding by zero is what most expect, and covers most common CNNs?
padding for forward- and backpropagation ...
Can't this all be handled by the host? If padding changes forward/backward, just pass the appropriate parameter.
In general, I think padding and stride are pretty commonly expected. At least in my experience of some (mainly python) APIs (including those for image processing, and not just CNNs), pad and stride are nearly always options (though the definition of pad can vary). And doesn't cuDNN support it via cudnnSetConvolutionNdDescriptor (link). (I have no experience whatsoever with cuDNN, just searched the API docs - so that comment might be invalid etc.)
That said, both can be done on the host. Padding really only requires copying the array, which is pretty cheap I guess. Stride you can get around (as I've seen in the one API which doesn't support it) by doing it with the default stride=1, and then e.g. sampling every 'Nth' value from the result for stride=N ... but this will be very inefficient, as you'll be N**2 slower than a solution using strides (I think). Another downside of doing both in the kernel is that you don't know the size of the array to allocate beforehand - but there are probably pretty straightforward ways around that. Anyway - @Ulfgard, how were you proposing to handle pad/stride if it's not supported in the kernel?
Ulfgard
commented
6 years ago Hi,
i just argued that "padding (generally just 'SAME' or 'VALID')" is not enough of an interface to describe padding on the level of a convolution implementation. this has nothing to do with host vs device vs speed. just: the interface.
//edit just to be more clear: i clearly argued for more convolution parameters. see my own interface of conv2d in the link above...
//edit2: to be 100% clear: I need:
i don't care about the rest.
kodonnell
commented
6 years ago Ah, sorry, I misinterpreted you - I took 'I am not a huge fan of many of the convolution extensions like striding or dilations, those things are what makes interfaces complex.' to mean you weren't a fan of strides/padding at all.
I agree that something more versatile that 'same' and 'valid' padding would be good. I do care about strides (and the same stride in every dimension). I don't are about dilation. Some of the neural net APIs include other operations within convolution (batch norms, activation, etc.) but I wouldn't include them (though I might add them in later myself).
Ulfgard
commented
6 years ago To get a bit back on topic regarding the interface.
I would propose splitting the current Im2Col in two functions, one defining the parameters and returning a config object, the other than takes the config as input and creates the matrix. This way the user can decide whether he wants to create the matrix (by calling Im2Col) or wants to run the convolution directly (by calling conv2d or similar). This way we also split configuration from usage allowing the users to keep their code more tidy.
So something like this:
struct im2colconf_t; //implementation defined.
//creates a configuration object for Im2Col matrix objects
im2colconf_t Im2colConf(const size_t channels, const size_t height, const size_t width,
const size_t kernel_h, const size_t kernel_w, const size_t pad_h, const size_t pad_w,
const size_t stride_h, const size_t stride_w, const size_t dilation_h, const size_t dilation_w)
//explicitely create im2Col matrix. new cross_correlate parameter
// will interpret padding differently if amount of padding is not divisible by 2.
// this ensures that cross-correlation and conv2d can be seen as a call to gemm with the Im2Col matrix.
//maybe also add image layout?
StatusCode Im2col(im2colconf_t config, bool cross_correlate
const cl_mem im_buffer, const size_t im_offset,
cl_mem col_buffer, const size_t col_offset,
cl_command_queue* queue, cl_event* event)
//new conv2d. maybe also add image layout?
template<class T>
StatusCode conv2d(im2colconf_t config, const size_t num_images, const size_t num_filters,
const cl_mem images_buffer, const size_t im_offset,
const cl_mem filters_buffer, const size_t filter_offset,
cl_mem results_buffer, const size_t results_offset,
cl_command_queue* queue, cl_event* event)
//cross-correlation. maybe also add image layout?
template<class T>
StatusCode ccorr2d(im2colconf_t config, const size_t num_images, const size_t num_filters,
const cl_mem images_buffer, const size_t im_offset,
const cl_mem filters_buffer, const size_t filter_offset,
cl_mem results_buffer, const size_t results_offset,
cl_command_queue* queue, cl_event* event)Sorry for my late reply, it's been a month, but some of the other issues took a bit longer than I hoped.
Thanks for all the suggestions. We do have to realise CLBlast is primary a BLAS library and although I am OK with adding some features for deep learning, it should become not too much, since I can't develop/maintain all that. There are other dedicated deep learning solutions available such as libDNN.
So I'm in favour of using a simpler interface, perhaps just a combination of the im2col interface and GEMM? That should do it, right? Because if I understand it correctly, col = im2col(image); result = col * weights. Thus the new interface would have 2 inputs, image and b (or weights above), and one output c (or result above). Thus a combination of im2col input and GEMM b & c would do it, e.g. like this:
// 2D convolution as GEMM (non-BLAS function):
// SCONVGEMM/DCONVGEMM/CCONVGEMM/ZCONVGEMM/HCONVGEMM
template <typename T>
StatusCode Convgemm(const size_t channels, const size_t height, const size_t width,
const size_t kernel_h, const size_t kernel_w,
const size_t pad_h, const size_t pad_w,
const size_t stride_h, const size_t stride_w,
const size_t dilation_h, const size_t dilation_w,
const cl_mem b_buffer, const size_t b_offset, const size_t b_ld,
const cl_mem im_buffer, const size_t im_offset,
cl_mem c_buffer, const size_t c_offset, const size_t c_ld,
cl_command_queue* queue, cl_event* event = nullptr);This way I can also test it easily, since im2col and GEMM are already implemented obviously. Is that the way forward or are there really things missing?
Ulfgard
commented
6 years ago Hi,
the real important thing is that im_buffer should be able to get a batch of images as input, i.e.
const cl_mem im_buffer, const size_t im_offset -> const cl_mem im_buffer, const size_t im_offset, const size_t num_images
Otherwise, the use is quite limited. in DL you rather have many small images than one big image. Thus only using one image per call will lead to bad GPU utilisation. This is implemented by simply cocatenating the im2col(image) matrices.
From: Cedric Nugteren [notifications@github.com] Sent: Wednesday, May 02, 2018 9:01 PM To: CNugteren/CLBlast Cc: Oswin Krause; Mention Subject: Re: [CNugteren/CLBlast] Merge Im2Col with GEMM into a new convolution API (#267)
Sorry for my late reply, it's been a month, but some of the other issues took a bit longer than I hoped.
Thanks for all the suggestions. We do have to realise CLBlast is primary a BLAS library and although I am OK with adding some features for deep learning, it should become not too much, since I can't develop/maintain all that. There are other dedicated deep learning solutions available such as libDNNhttps://github.com/naibaf7/libdnn.
So I'm in favour of using a simpler interface, perhaps just a combination of the im2col interface and GEMM? That should do it, right? Because if I understand it correctly, col = im2col(image); result = col * weights. Thus the new interface would have 2 inputs, image and b (or weights above), and one output c (or result above). Thus a combination of im2col input and GEMM b & c would do it, e.g. like this:
// 2D convolution as GEMM (non-BLAS function): SCONVGEMM/DCONVGEMM/CCONVGEMM/ZCONVGEMM/HCONVGEMM
template
This way I can also test it easily, since im2col and GEMM are already implemented obviously. Is that the way forward or are there really things missing?
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHubhttps://github.com/CNugteren/CLBlast/issues/267#issuecomment-386085445, or mute the threadhttps://github.com/notifications/unsubscribe-auth/AOWTBuaJ_zIruQLuKoeqAXtNtMRmW0aDks5tugKHgaJpZM4SyFHv.
Ulfgard
commented
6 years ago also uneven padding is still problematic (one can not decide how pad_h is split for padding left/right). This makes it impossible to implement any DL application with even kernel-size directly (or one needs the workaround of padding the kernel with zeros to make padding even)
i am not sure what the c_ld parameter is supposed to mean. using the implementation based on gemm one can assume that this is somehow "store it in an image that has more filters" but without knowing this implementation detail, it could also mean "store it in a sub-image".
CNugteren
commented
6 years ago OK, yes indeed, the 'batch' argument was missing. I just the "b" and "c" naming from GEMM, but probably to give it better names indeed, and omit the ld parameter. What about the following:
// Convolution as GEMM (non-BLAS function): SCONVGEMM/DCONVGEMM/CCONVGEMM/ZCONVGEMM/HCONVGEMM
template <typename T>
StatusCode Convgemm(const size_t channels, const size_t height, const size_t width,
const size_t kernel_h, const size_t kernel_w,
const size_t pad_h, const size_t pad_w,
const size_t stride_h, const size_t stride_w,
const size_t dilation_h, const size_t dilation_w,
const size_t num_kernels, const size_t batch_count,
const cl_mem im_buffer, const size_t im_offset,
const cl_mem kernel_buffer, const size_t kernel_offset,
cl_mem result_buffer, const size_t result_offset,
cl_command_queue* queue, cl_event* event = nullptr);So in this case the sizes of the 3 buffers are:
image = height * width * channels * batch_count
kernel = kernel_h * kernel_w * num_kernels
result = height_out * width_out * num_kernels * batch_countHere I can use the same definition of height_out and width_out as for im2col.
The bit about splitting the padding for left/right I don't understand. You would want e.g. padding on the left but not on the right? If so, this is currently also already an issue for the im2col implementation, right? Perhaps we can leave this feature out for now and add it later?
Ulfgard
commented
6 years ago This looks good.
regarding the padding: yes, this is already an issue there. But the issue is not about choosing freely, how much padding is added on each side, but resulting from an issue with even kernel sizes.
Assume the kernel size is 4 and we want to have the same output size as the input, thus pad_h and pad_w are 3. In that case we can not pad all sides evenly. One can decide to pad 2 on the left and one on the right(same for up/down). This corresponds to choosing pixel 3/3 as the center pixel of the filter.
For some operations, the kernel needs to be flipped before the computation can happen(this flip is formally turning the cross-correlation[1] most DL guys call convolution into a proper convolution[2]. This flip results in different computation properties, e.g. convolution is commutative, cross-correlation is not). After flipping the kernel around the x/y axis, the center pixel will be at 2/2, thus the padding needs to be flipped as well.
This is the one case that is needed in a more than academical sense. adding padding on each side freely is maybe "nice" but no must-have.
[1] https://en.wikipedia.org/wiki/Cross-correlation [2] https://en.wikipedia.org/wiki/Convolution
From: Cedric Nugteren [notifications@github.com] Sent: Friday, May 04, 2018 9:06 PM To: CNugteren/CLBlast Cc: Oswin Krause; Mention Subject: Re: [CNugteren/CLBlast] Merge Im2Col with GEMM into a new convolution API (#267)
OK, yes indeed, the 'batch' argument was missing. I just the "b" and "c" naming from GEMM, but probably to give it better names indeed, and omit the ld parameter. What about the following:
// Convolution as GEMM (non-BLAS function): SCONVGEMM/DCONVGEMM/CCONVGEMM/ZCONVGEMM/HCONVGEMM
template
So in this case the sizes of the 3 buffers are:
image = height width channels batch_count kernel = kernel_h kernel_w num_kernels result = height_out width_out num_kernels batch_count
Here I can use the same definition of height_out and width_out as for im2col.
The bit about splitting the padding for left/right I don't understand. You would want e.g. padding on the left but not on the right? If so, this is currently also already an issue for the im2col implementation, right? Perhaps we can leave this feature out for now and add it later?
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHubhttps://github.com/CNugteren/CLBlast/issues/267#issuecomment-386702859, or mute the threadhttps://github.com/notifications/unsubscribe-auth/AOWTBqcdm3pKhGAlt81wFl7FY77_3mkCks5tvKapgaJpZM4SyFHv.
CNugteren
commented
6 years ago OK, thanks for the explanation. Let's consider this use-case after a first implementation is complete.
I have also made everything a 4D tensor and will use (initially) the NCHW ordering, as that is the best for a GPU as I understand it. For the weights tensor I went with outputC-inputC-height-width, I hope that makes sense:
// 4D: NCHW == batch-channel-height-width
image_size = batch_count * channels * height * width
// 4D: KCHW == kernel-channel-height-width (num_kernels == number of output channels)
kernel_size = num_kernels * channels * kernel_h * kernel_w
// 4D: NCHW == batch-channel-height-width
result_size = batch_count * num_kernels * output_height * output_widthI have just pushed a first version of the interface, a skeleton implementation (nothing in there really), and the test infrastructure to a new CLBlast-267-convgemm branch. Perhaps most interesting for you would be to have a look at the reference implementation here.
CNugteren
commented
6 years ago As a test, the CLBlast-267-convgemm now contains a working implementation of convgemm, but just based on calling the regular im2col and GEMM in a loop over batches.
 haolongzhangm
commented
6 years ago
haolongzhangm
commented
6 years ago Dear CNugteren any plan implement the convgemm with one kenrel , not calling the regular im2col and GEMM in a loop
Ulfgard
commented
6 years ago Thanks for your efforts. This is now enough (modulo the padding issue) to write a binding and test it. I hope we can get the "full thing" in the near future :)
do you want me to benchmark it, maybe against a naive kernel?
CNugteren
commented
6 years ago Thanks for the help so far. @haolongzhangm: Yes, currently I'm working on it, I'll update here as soon as there is something to update :-)
CNugteren
commented
6 years ago It should be quite easy to do this
Quite an understatement it seems, but I'm getting there :-)
There is now something implemented in the CLBlast-267-convgemm branch, which still has code in place to switch to an im2col based approach as well (mostly for debugging, but could be a nice user option later). It has a fully custom kernel, based on direct single-kernel GEMM approach (see also here), I hope that is the right choice.
Currently performance is quite poor and there are two things to look at: improving the kernel further, and creating a set of specific parameters for this routine plus a kernel tuner. Furthermore, I'm not sure about correctness yet. Although the tests pass, I'm doing some vectorised loads I have to double check if I'm actually allowed to do. So still a lot of work to do.
Ulfgard
commented
6 years ago When i wrote this i did not even once look at your kernel generation code :) I thought "there should be one kernel generating a block of the im2col matrix. so we should be able to use it as an argument for the direct gemm kernel...". Maybe i didn't think of all the different special cases. But I think the direct kernel is the right thing to do.
It might be that the outer loop over the gemm-blocks needs to be different than in standard gemm. It might be better to assume that a) generating the im2col block is rather expensive and b) the filter matrix only has a few tiles. Therefore it might be beneficial to compute all filters for the same block in a loop. Maybe, it might pay off doing a "semi-direct" approach, i.e. preprocess the filter matrix so that the direct kernel is in the "fast" special case for that argument.
I am super busy until Wednesday afternoon. I might be able to get a Benchmark in place and have a look over the code. What arguments are you using? typical inputs for deep leaning applications are
image: 32x32xk (where k is 1,3,32,64), 50 images in a batch. filter: nxnxkxl (where n is 3 or 5, l is max(2k,32)
the other use-case is one large image (same k and filter as before).
there is also the super nasty special case of filter size being close to the image size, so that matrix C is quite small. I think this the "death to gemm" case as parallelization is hard without additional memory. But we can ignore it for now...
haolongzhangm
commented
6 years ago @CNugteren
Dear CNugteren
look at U new API DoConvgemm, the param now merge from im2col and gemm API,
but all the scene of use convgemm in DL or scientific calculation, after conv API will
do bias, So I suggest add a new param named const Buffer
CNugteren
commented
6 years ago Thanks both for the feedback. Here's some reactions:
When i wrote this i did not even once look at your kernel generation code :) I thought "there should be one kernel generating a block of the im2col matrix. so we should be able to use it as an argument for the direct gemm kernel...".
It is not that easy indeed. If this would be pure C++ code I would have written it like that with templates and such, but since it is an OpenCL C kernel I have it all just as a big string, so there is some duplication. I decided against using kernel generation code, as that makes it quite unreadable.
It might be that the outer loop over the gemm-blocks needs to be different than in standard gemm. It might be better to assume that a) generating the im2col block is rather expensive and b) the filter matrix only has a few tiles. Therefore it might be beneficial to compute all filters for the same block in a loop. Maybe, it might pay off doing a "semi-direct" approach, i.e. preprocess the filter matrix so that the direct kernel is in the "fast" special case for that argument.
OK, seems like a logical thing to evaluate. I'll try this when I have time.
I am super busy until Wednesday afternoon. I might be able to get a Benchmark in place and have a look over the code. What arguments are you using?
I haven't really done benchmarking yet, but I have been using ./clblast_client_xconvgemm -channels 32 -width 64 -height 64 -num_kernels 32 -batch_num 16 to test, which means a stride 1 3x3 kernel because that's the default if no argument is geven.
after conv API will do bias, So I suggest add a new param named const Buffer &bias_buffer, then we can do DL conv only with DoConvgemm API, how do U think about this ?
OK, I understand. But it also seems bias is often omitted nowadays in favour of batch norm. So if I start adding the bias, I'll have to add BN, and perhaps support for a non-linearity, ... I have to be careful CLBlast become a deep learning library, because the BLAS API is not really suited for it, it would be better to go for an Eigen-like approach or something. So perhaps let's postpone this topic a bit to later, OK?
kodonnell
commented
6 years ago But it also seems bias is often omitted nowadays in favour of batch norm
Except that convolution (with or without bias) + batchnorm can be fused into just a convolution with bias, with different weights/bias.
Ulfgard
commented
6 years ago I think, we can all live with the complexity of adding a constant/scaling each channel independently. There is so much missing in CLBlast to make it a deep learning library, this one kernel does not make a difference (i bet you will also not see in in the runtime).
one could as well fuse it with the nonlinear activation afterwards.
From: kodonnell [notifications@github.com] Sent: Tuesday, May 22, 2018 11:04 PM To: CNugteren/CLBlast Cc: Oswin Krause; Mention Subject: Re: [CNugteren/CLBlast] Merge Im2Col with GEMM into a new convolution API (#267)
But it also seems bias is often omitted nowadays in favour of batch norm
Except that convolution (with or without bias) + batchnorm can be fused into just a convolution with bias, with different weights/bias.
— You are receiving this because you were mentioned. Reply to this email directly, view it on GitHubhttps://github.com/CNugteren/CLBlast/issues/267#issuecomment-391140094, or mute the threadhttps://github.com/notifications/unsubscribe-auth/AOWTBk4ptJ7IjEJCtJzZeZXczDisyWj-ks5t1H1BgaJpZM4SyFHv.
 TaihuLight
commented
6 years ago
TaihuLight
commented
6 years ago @CNugteren Do you have implement gemm+col2im batched for backward conv?
CNugteren
commented
6 years ago @TaihuLight No, there is another issue open for col2im. As Ulfgard also argues above, not sure if that will ever be implemented. First priority will be on this issue though.
Ulfgard
commented
6 years ago The current implementation is sufficient for uneven kernel sizes. Luckily the back propagation step can be completely described via a convolution as well. No more work needed. (shameless drop of my own implementation of a CNN in that case: https://github.com/Shark-ML/Shark/blob/master/include/shark/Models/ConvolutionalModel.h )
For even kernel sizes the padding issue would need to be resolved.
TaihuLight
commented
6 years ago @CNugteren Do you continue to finish xCONVGEMM: Batched convolution as GEMM (non-BLAS function) ?
CNugteren
commented
6 years ago Yes, give it another month or two... Although not sure about speed benefits, mostly seems to be memory benefits so far, at least in its first implementation.
CNugteren
commented
6 years ago I haven't had the time to work on this for a while unfortunately. Therefore I decided to take the branch and set the defaults to batched im2col + batched gemm, so that I have something to merge in. I tested everything, and it works. This is now merged in, see here for details. In other words, the convolution API can be used but it still uses a lot of memory, since it runs in im2col + GEMM mode.
I also merged in master to the old CLBlast-267-convgemm branch, which now contains more or less the same code, but runs the (non bug-free) single-kernel code now. It also has a tuner to test different parameters, see here for the diff. Next thing to do is catch those bugs from the single-kernel version. Running the tuner shows that not all parameter combinations yield the same result, so there must still be some things wrong.
 tingxingdong
commented
5 years ago
tingxingdong
commented
5 years ago Thanks for the code. Can you clarify this comment in this kernel: https://github.com/CNugteren/CLBlast/blob/83ba3d4b7ba3a9cb5fbd2c1ad2bb14b2addd39fb/src/kernels/levelx/xconvgemm_part2.opencl
// This uses "CONVGEMM_WITH_IM2COL" as a switch to select between direct convgemm or first running // the im2col kernel to create a 'col' temporary matrix. // TODO: Currently only works with 'CONVGEMM_WITH_IM2COL' set
So, "if defined(CONVGEMM_WITH_IM2COL)", what is the consequences? Will it use direct convgemm ( I assume im2col & gemm in the same kernel? ) or it will assume im2col kernel has been called outside this kernel?
Also, do you have a formal write-up to describe your implementation? instead of code comments and issue discussions?
Thank you.
CNugteren
commented
5 years ago Currently, the only thing that is implemented is CONVGEMM_WITH_IM2COL: running first a batched version of im2col to prepare the data, and then running a batched version of GEMM. The implementation is just as the regular im2col and GEMM kernels in CLBlast, but it is implemented as a separate kernel so all the non-needed features can be stripped out and some optimizations can be made.
The next step would be to load the data in such a way that the im2col kernel is no longer needed, i.e. loading the data as the im2col transformation does it. That way it will be a single kernel and there will be no need for an intermediate large buffer. However it will most likely be a slower than the current approach I guess.
tingxingdong
commented
5 years ago The second way (fusing im2col, not explicit large intermediate large matrix) is the cuDNN's approach.
TaihuLight
commented
5 years ago @CNugteren @Ulfgard @vbkaisetsu The XCONVGEMM routine is add to CLBlast 1.5.0. Unfortunately, its performance (relative speedups as the batch_count increases) is not good as desired, as the batchedstridedGEMM is not noticeably accelerated as the batch_count increases. The test results with different sizes of batch_count and other default parameters on Intel Graphics HD630 are shown as following:
Batch_num = 1
Average result of 2.80 ms: 27.0 GFLOPS
Best result 1.05 ms: 72.2 GFLOPS
Batch_num = 2
Average result of 2.80 ms: 28.4 GFLOPS
Best result 1.05 ms: 72.8 GFLOPS
Batch_num = 4
Average result of 2.80 ms: 28.7 GFLOPS
Best result 1.05 ms: 73.3 GFLOPS
Batch_num = 8
Average result of 2.80 ms: 29.0 GFLOPS
Best result 1.05 ms: 75.3 GFLOPS
Batch_num = 16
Average result of 2.80 ms: 29.1 GFLOPS
Best result 1.05 ms: 74.4 GFLOPS
Batch_num = 32
Average result of 2.80 ms: 29.2 GFLOPS
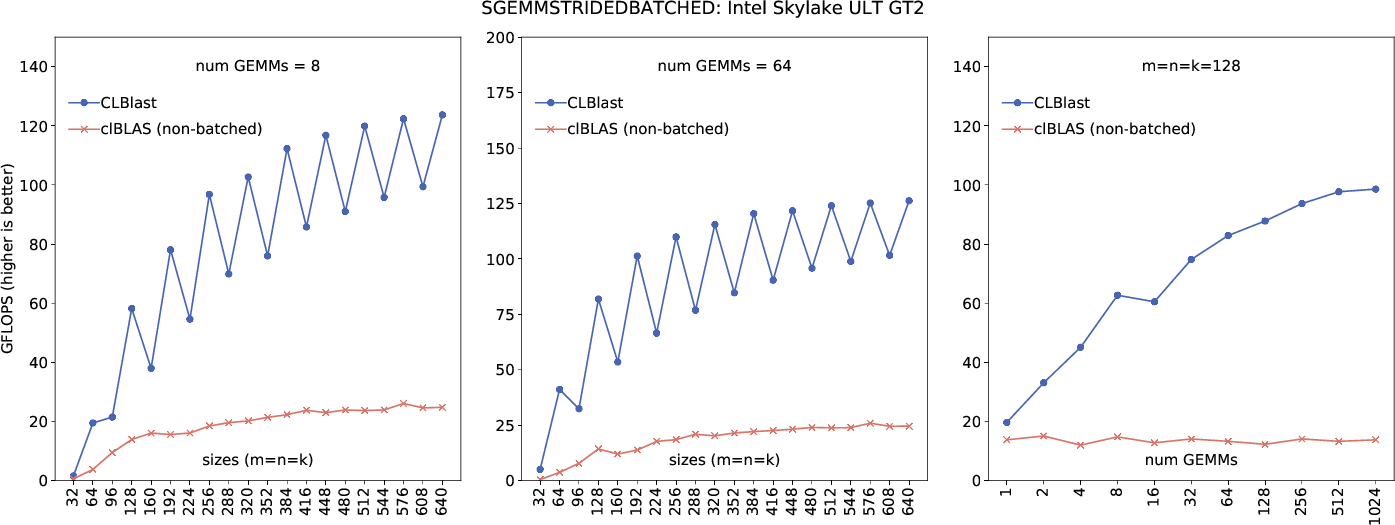
Best result 1.05 ms: 74.0 GFLOPSOK, so what you are saying is that the speed of sgemmstridedbatched is disappointing, because you expect better speed as the batch size is increased? And that is because you have a roofline of 704 GFLOPS? Note that on my Intel GPU I can't get close to the roofline either. For comparison, the graphs I obtain are: https://cnugteren.github.io/clblast/results/SkylakeULTGT2/sgemmstridedbatched_plot.png
So you get around 200 GFLOPS. How much do you get with a regular SGEMM from CLBlast at the maximum?
TaihuLight
commented
5 years ago @CNugteren

 That is, the ideal performance for m=n=k=96 should be shown as following: But the tested results are not the same with the ideal statues.
That is, the ideal performance for m=n=k=96 should be shown as following: But the tested results are not the same with the ideal statues.
batch_count=1(regular SGEMM from CLBlast) GFLOPS=13 baseline
batch_count=2 GFLOPS=19.5~25 relative speedups=1.5x~2x
batch_count=4 GFLOPS=32.5~50 relative speedups=2.5x~4x
batch_count=8 GFLOPS=53.3~100 relative speedups=4.1x~8x
batch_count=16 GFLOPS=89.7~200 relative speedups=6.9x~16x

Why the XCONVGEMM routine does not get ideal speedups with the growth of the size of batch_count. It is implemented with direct convolutions and sgemmstridedbatched is better for accelerate convolutions?
CNugteren
commented
5 years ago OK, so you are saying that in sgemmstridedbatched on your device, results for m=n=k=128 and larger are fine, since speed increases as you increase the number of batches. However, for m=n=k=96 and smaller there is no benefit of the batch size, as speed remains more or less constant?
Well in that case I think your observation is related to the fact that the GEMM routines (also including the strided batched GEMM) have a tuning parameter to select between the two types of implementations: XGEMM_MIN_INDIRECT_SIZE. See also the docs. Most probably in your case for your experiment this parameter is set too high, and if you lower it (e.g. to 16 or so), you'll be using the indirect kernel for 32, 64, and 96 as well (as you did before for 128 and up) and the issue will be resolved.
TaihuLight
commented
5 years ago @CNugteren @Ulfgard
No. Instead, for sgemmstridedbatched when m=n=k=96 and smaller there is benefit of the batch size. The results for m=n=k=128 and larger are not fine, since as speed remains more or less constant as I increase the number of batches. And this also shown in your results https://cnugteren.github.io/clblast/results/SkylakeULTGT2/sgemmstridedbatched_plot.png For instance, some cases coming from your results are shown as follow.
m=n=k=64 GFLOPS=20(batchsize=8), GFLOPS=40(batchsize=64) speedup=40/20=2.0x
m=n=k=96 GFLOPS=25(batchsize=8), GFLOPS=30(batchsize=64) speedup=30/25=1.2x
m=n=k=640 GFLOPS=125(batchsize=8), GFLOPS=125(batchsize=64) speedup=125/125=1.0xThe XCONVGEMM routine also has the same problem for its performance, since as speed remains more or less constant as I increase the number of batches. Why? How can I resolve it. For sgemmstridedbatched and XCONVGEMM, their speeds should increase as the number of batches increase. In fact, their speeds remains more or less constant as I increase the number of batches.
CNugteren
commented
5 years ago But then you are talking about larger matrices, and for those the bottleneck lies elsewhere apparently. Increasing the batch size doesn't help with the speed indeed, as you rightly observe. For smaller matrices there is something to gain (they don't fill the GPU entirely on itself and suffer from limited parallelism), which you can also find in your results. But for large matrices not, they already hit other bottlenecks which you can't cure by just simply running more of the same. I'm not really sure what kind of magic you expect to happen here...
TaihuLight
commented
5 years ago I got it. These two routines fit to smaller matrices instead of larger matrices, as increasing the batch size doesn't help with the speed for larger matrices. I expect that increasing the batch size can help with the speed for sgemmstridedbatched and XCONVGEMM with larger matrices. Maybe I am wrong?
CNugteren
commented
5 years ago I'm not sure how it should improve speed. At least not in the current implementation: it just computes other batches separately in the third thread dimension (e.g. see here in code. This has a few overheads (some extra index calculations, other threads potentially polluting caches and so), but has as a main advantage that there is more work to do. For small matrices the work-size (parallelism, latency hiding, etc.) can cause them to go slow. Now, with batches, that can be alleviated. If we have enough threads for our GPUs, batched operations could in theory even harm performance a bit compared to running GEMM sequentially. If you feel this is indeed a problem and have some theory, then feel free to open a separate issue here on GitHub.
CNugteren
commented
5 years ago Separate from above discussion, I can now also announce that (with the help of @vbkaisetsu) the single kernel version got merged yesterday! That means we can close this issue.
For more info on both convolution implementations, see the new documentation.
{kind=link}
Hi, This is a feature request.
The standard approach of first using im2col and then using gemm for a convolution has the disadvantage that one very easily runs out of memory. There is actually no reason to call im2col directly, ever(the three convolution primitives, convolution, derivative wrt the input and derivative wrt filter can be formulated as convolutions themselves). The approach that for example cuDNN follows is that the im2col matrix is only created implicitely inside the convolution-gemm kernel. instead of loading the part of the im2col matrix into local memory, it is created on the fly. It should be quite easy to do this in the framework provided by CLBlast.
Further, batch-processing of images should be made possible.