 blueberry
commented
8 years ago
blueberry
commented
8 years ago Unfortunately, I cannot help by implementing this, but I just want to give thumbs up for this functionality. Currently, I resort to writing my own special-case kernels for such cases.
 bhack
bhack gcp
gcp naibaf7
naibaf7 CNugteren
CNugteren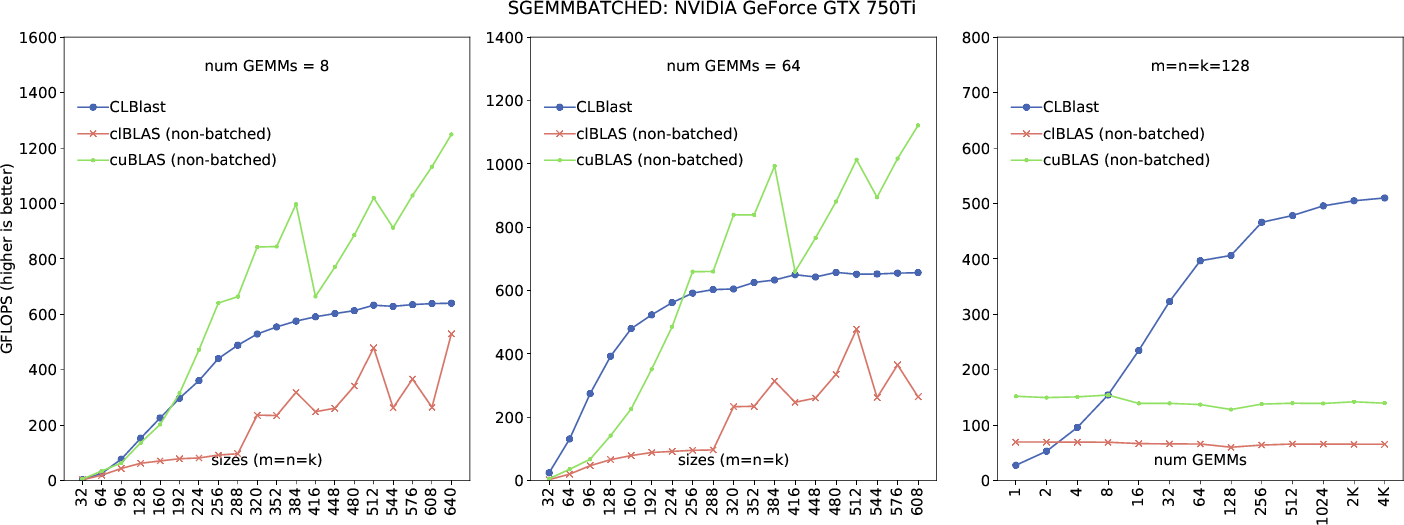{kind=link}
Batched operations involve performing many small linear-algebra operations, such as GEMV or GEMM. In particular batched GEMM has become increasingly popular due to deep learning. More parallelism can be exploited when making a single batched BLAS call compared to multiple regular BLAS calls on small matrices. NVIDIA's cuBLAS for example has a batched GEMM interface.
Two potentially related papers are: