 HanatoK
commented
1 week ago
HanatoK
commented
1 week ago Hi @giacomofiorin! It seems there is no change to the SMP related code, but maybe I miss somethign. If a cvc reuses other ones, how does the SMP work?
Open giacomofiorin opened 6 months ago
HanatoK
commented
1 week ago Hi @giacomofiorin! It seems there is no change to the SMP related code, but maybe I miss somethign. If a cvc reuses other ones, how does the SMP work?
 giacomofiorin
commented
1 week ago
giacomofiorin
commented
1 week ago Hi @giacomofiorin! It seems there is no change to the SMP related code, but maybe I miss somethign. If a cvc reuses other ones, how does the SMP work?
See the last paragraph description. What I would like to do is keep a list of reusable CVCs, and run those first over SMP.
HanatoK
commented
1 week ago Hi @giacomofiorin! It seems there is no change to the SMP related code, but maybe I miss somethign. If a cvc reuses other ones, how does the SMP work?
See the last paragraph description. What I would like to do is keep a list of reusable CVCs, and run those first over SMP.
Thanks! I am working on linearCombination and customColvar at first, and they are supposed to reuse all other CVCs. In my opinion, all CVCs should be reusable. Maybe we can add a new user option like reuseThisCV for all CVCs to let the users control whether a CVC is reused.
giacomofiorin
commented
1 week ago Thanks! I am working on
linearCombinationandcustomColvarat first, and they are supposed to reuse all other CVCs. In my opinion, all CVCs should be reusable. Maybe we can add a new user option likereuseThisCVfor all CVCs to let the users control whether a CVC is reused.
That's one option, but then all CVC classes would then need to have the necessary API changes. Okay with you if we discuss more next week?
HanatoK
commented
1 week ago Thanks! I am working on
linearCombinationandcustomColvarat first, and they are supposed to reuse all other CVCs. In my opinion, all CVCs should be reusable. Maybe we can add a new user option likereuseThisCVfor all CVCs to let the users control whether a CVC is reused.That's one option, but then all CVC classes would then need to have the necessary API changes. Okay with you if we discuss more next week?
OK.
giacomofiorin
commented
1 week ago Also, linearCombination and customColvar are cheap enough that we can always run them at the end, outside of SMP (the same as the polynomial superposition code in colvar::collect_cvc_values()).
So it would make sense to make them special cases.
HanatoK
commented
1 week ago I just doubt if it is really necessary to distribute the CVCs to different threads. On one hand, if the thread for CVC_A takes longer time to finish, then the thread for CVC_B has to wait. On the other hand, it makes the reusable CVCs complicated. I still think it would be better if Colvars can give up distributing CVCs among threads completely, and use the threads in fine-grained cases, such as calculating correlation and overlapping matrices in optimal rotation, rotating atoms, and projecting a hill in metadynamics...
 jhenin
commented
1 week ago
jhenin
commented
1 week ago The main use case for distributing CVCs over threads is that of multiple, expensive CVCs of similar computational cost. It is hard to know how widespread it is, but in that case, the current implementation has the benefit of improving performance transparently without user intervention.
HanatoK
commented
1 week ago The main use case for distributing CVCs over threads is that of multiple, expensive CVCs of similar computational cost. It is hard to know how widespread it is, but in that case, the current implementation has the benefit of improving performance transparently without user intervention.
If the expensive CVCs refer to RMSD, anything related to optimal alignment and coordNum, then it is still better to distribute the expensive loops in a single CVC over threads instead of distribute CVCs themselves over threads. The former approach is more friendly to CPU caches, especially the shared L3 cache, because the CPU could fetch a large chunk of continuous data, instead of many small blocks, from the main memory to L3 directly for all threads. Moreover, distributing the inner loops in a CVC over threads can guarantee to accelerate the calculation of the most expensive CVC. Distributing CVCs over threads means that the slowest CVC uses always a single thread, and if there are other fast CVs (for example, using RMSD, gyration and a few distances), then the other threads have to wait for the slowest done.
HanatoK
commented
1 week ago I am looking into ways to parallelize the computation of CVCs even if there are interdependencies. With the dependencies the CVCs are in a compute graph. A way to parallelize the computation could be:
For example, in the following compute graph,
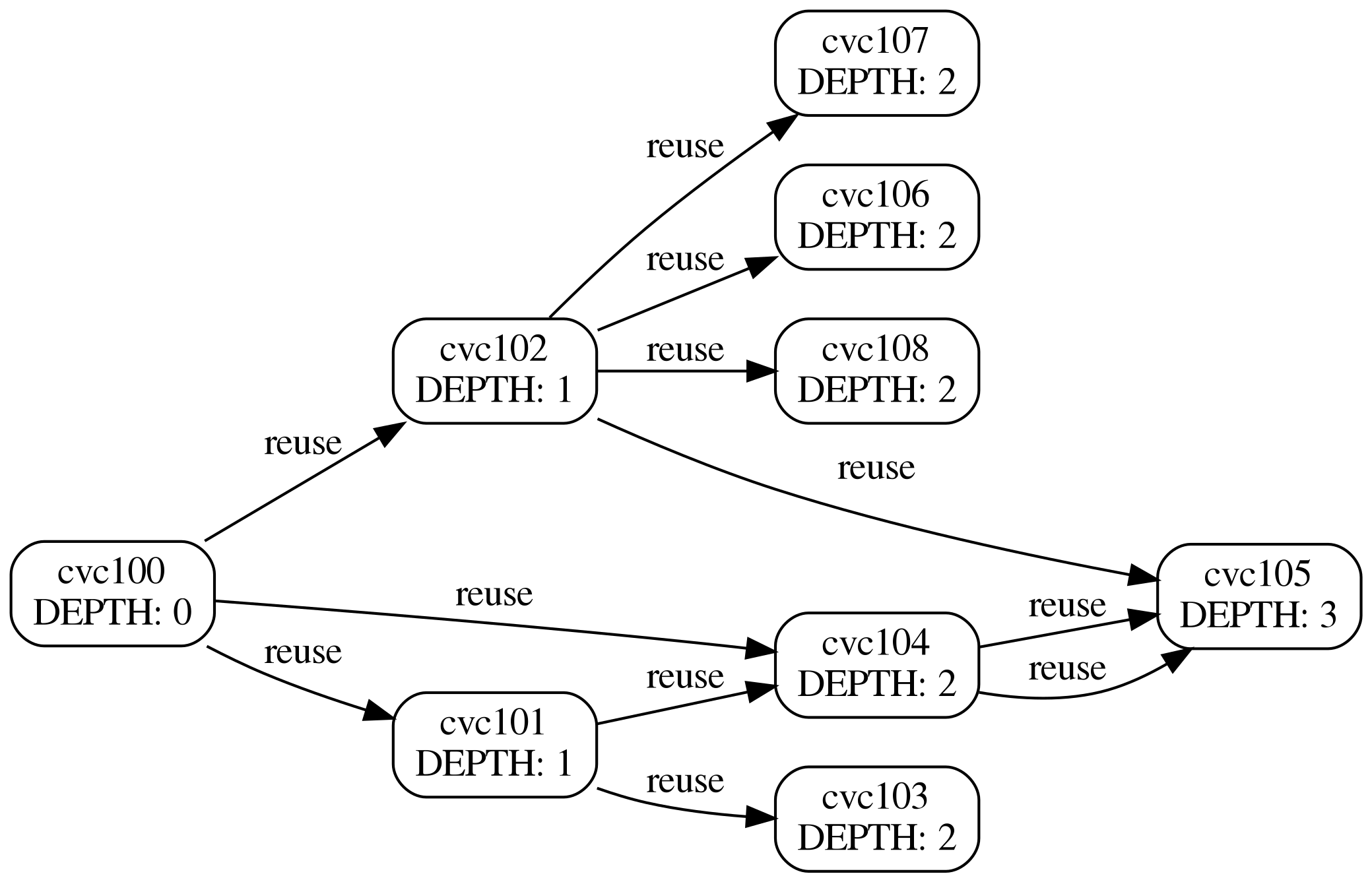 we can compute all "depth=3" cvcs at first, and the all "depth=2". Each depth group could be parallelized. The code can be found in https://github.com/HanatoK/miscellaneous_scripts/blob/8ed465bbe5f7ccf0d950b7d10449be95443c386d/walk_graph/test.cpp#L112-L143
we can compute all "depth=3" cvcs at first, and the all "depth=2". Each depth group could be parallelized. The code can be found in https://github.com/HanatoK/miscellaneous_scripts/blob/8ed465bbe5f7ccf0d950b7d10449be95443c386d/walk_graph/test.cpp#L112-L143
Now the major issue is that Colvars actually does not distribute CVCs over threads, and instead, the parallelization scheme is worse than I expect. It distributes the outermost colvar over threads!
HanatoK
commented
1 week ago There should be an additional reusability improvement about applying biasing force only to a single value of a vector CV, so that we can safely compute some CVs in a single CVC and output a vector, and then bias only a scalar part of the vector.
giacomofiorin
commented
6 days ago Now the major issue is that Colvars actually does not distribute CVCs over threads, and instead, the parallelization scheme is worse than I expect. It distributes the outermost
colvarover threads!
Hi @HanatoK the loop is done over colvar objects to avoid having the top-level class reach too deep into the CVCs. However, in the case of a colvar with multiple CVCs, that colvar will appear in the loop multiple times to achieve parallelism over the entire collection of CVC objects. https://github.com/Colvars/colvars/blob/0f2d6829a8ceb6e0af9335e46ffa5cb16bd7120c/src/colvarmodule.h#L273-L277
Your other comments all make sense, especially regarding building a dependency tree and do multiple parallel loops, one for each level. This PR is meant to introduce only one level to start with.
This draft PR contains an implementation of the code to reuse the output of certain computations between colvar component (CVC) objects. The scheme aims to provide support a broader set of use cases than the ones described in #232, i.e. it aims to share specific pieces of computation between CVCs of different types, as well as allowing concurrent application of forces.
The proposed scheme works as follows. In the configuration string of CVC_B, a reference is provided to CVC_A, which is an object been defined previously in the Colvars config. The type of CVC_A may be the same as CVC_B (in which case its value is simply copied), or it may be a base class of CVC_B, or the same as one of its members. In the latter two cases, It's assumed that the computation of CVC_B can be written as follows:
When CVC_A is an object that was already computed, CVC_B can skip the first two steps altogether, and just replace the third step with an assignment.
Potential use cases are the following. This PR contains so far only an implementation for the first case.
orientationcomponent in atilt,spinAngle,euler{Phi,Theta,Psi}, component.distanceVeccomponent as input todistance,distanceZ,distanceXY, etc.gyration,inertia,inertiaZ, etcIn all of the above, the speedup would be a factor of 2 or 3, assuming that the explicit loop over atoms is speed-limiting and depending on the configuration. (The inertia tensor has six independent components, but I assume that very few would be interested in biasing them all!)
Opening as a draft because the SMP loop is currently unaware of the mutual dependencies, leading to race conditions. I would also like to cover some of the simpler use cases listed above. (More complex ones, e.g. RMSD and path CVs, should be in their own PRs.)
Implements #232