 Crissium
commented
9 months ago
Crissium
commented
9 months ago 欢迎建议 :)
增加对compact html紧凑格式的支持
这两天会实现。
简繁通搜如果能实现不依赖标记组的语言为 zh ,直接在默认组就能实现就好了
这个不会支持。简繁转换和希腊文阿拉伯文 ASCII 转写用的是同一套 API, 如果我默认支持 zh, 要不要默认支持 el, ar, 甚至是以后可能加上的 Farsi, Urdu, 各种 Perso-Arabic 的/用西里尔字母的语言,印地语梵语呢?即便只加上 zh 也会影响从 suggestions 到查词各种功能的性能。
加上 zh 十分容易,新建一个 group, 语言填上 zh 就行了,然后把词典加进去。直接强行修改 Default group 的 lang 字段不是不行,这么写:
- lang: !!set
zh: null
name: Default Group三栏宽度可调整 词典名称字体大小可以稍微小一些
我不是设计师,前端的一点东西也都是为了这个项目自学的,所以水平有限。我这几天把后端该实现的都实现之后会用一些业界成熟框架(而不是直接用 React 自己 home-grow components)重新设计前端,这些建议我都会记下来。
 czz404
czz404 大佬有空再看下这个,部分内容不显示 词典:
大佬有空再看下这个,部分内容不显示 词典: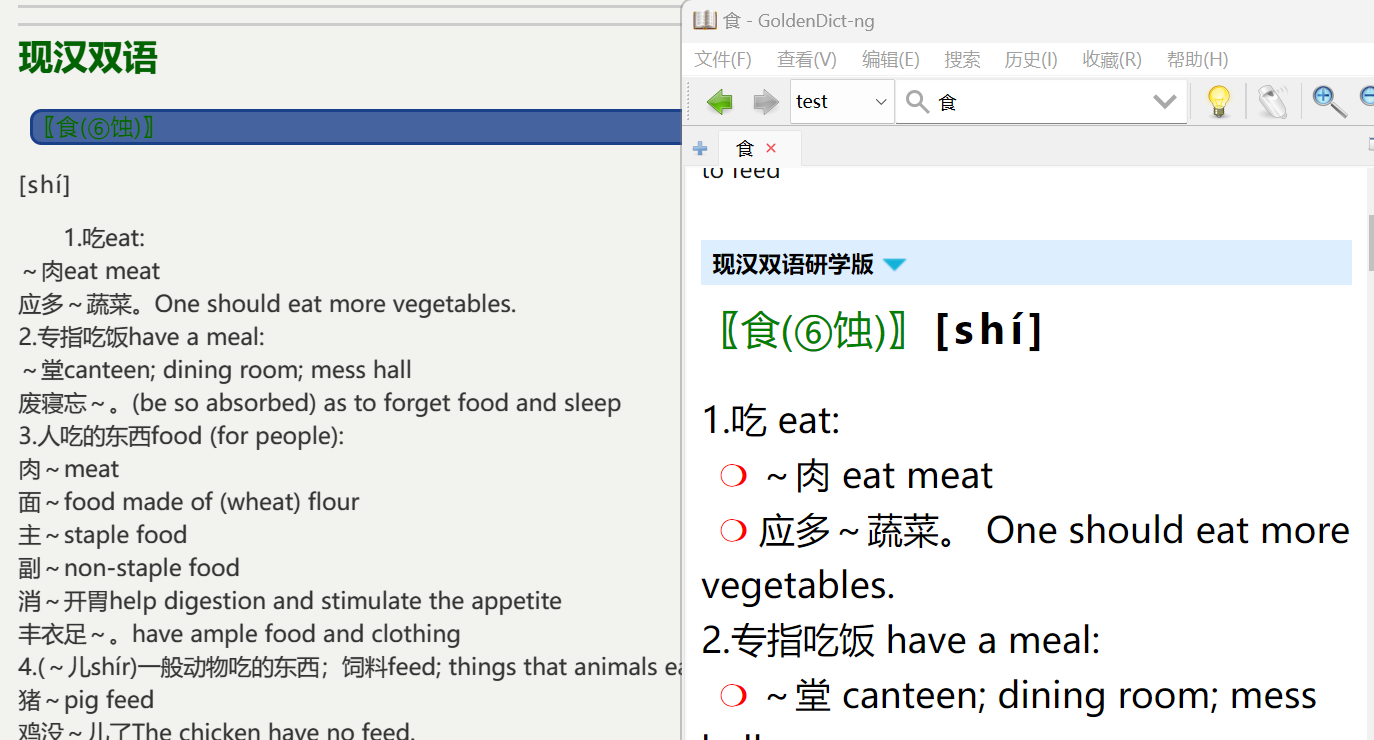 不知道是不是因为结构什么的写的不太好,和 GD-ng 呈现出来的区别很大
感谢!
不知道是不是因为结构什么的写的不太好,和 GD-ng 呈现出来的区别很大
感谢!

大佬您好,我是论坛过来的,老占楼回复不太方便,在这里记录一下我的小建议
功能上:
界面上: