 sunaynagoel
commented
5 years ago
sunaynagoel
commented
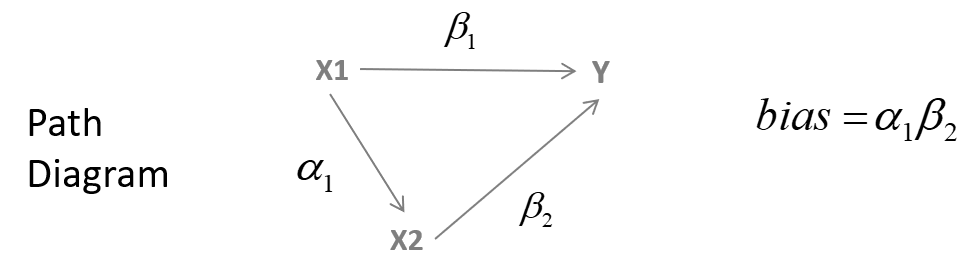
5 years ago Page #12-13 of Omitted Variable PDF. It says " Bias is difference between Truth and Naive Slopes" shouldn't it be other way around? Which is what it shows by calculation in page 14
"b1 = Direct Effect + Indirect Effect
β1 = Direct Effect
bias = b1 – β1 = Indirect Effect "Unless I am referring the terms intangibly.
 lecy
lecy jmacost5
jmacost5
 castower
castower
 JasonSills
JasonSills
 cjbecerr
cjbecerr


{kind=link}
Would you be bale to open the unit overview and lab for week 04 ? please.