 ajlennon
commented
5 years ago
ajlennon
commented
5 years ago The SSH server is also not accepting connections.
Open amcewen opened 5 years ago
ajlennon
commented
5 years ago The SSH server is also not accepting connections.
ajlennon
commented
5 years ago My suspicion is we finally filled up the uSD card with data
 MatthewCroughan
commented
5 years ago
MatthewCroughan
commented
5 years ago Don't wipe anything before backing up the grafana dashboard json!
ajlennon
commented
5 years ago Do you hear the bell tolling @MatthewCroughan ?
ajlennon
commented
5 years ago All seems to be running ok

ajlennon
commented
5 years ago So, I think this is working ok. Dunno why we were having a problem. Might just have been the m-DNS
We DO urgently need to look at dealing with the contents of the InfluxDB as we're on about 75% disk usage.
So changing the issue name for now. Change it back if it falls over again
Not sure whether we
MatthewCroughan
commented
5 years ago Will set this up tonight on the NAS Alex. Perhaps we should really be running a large grafana server here.
 amcewen
commented
5 years ago
amcewen
commented
5 years ago I'd had the mqtt.local Node RED open in a tab all afternoon, and just spotted there'd been a bunch of the "failed to connect to host" errors and a few connection refused ones too. Plus the power usage messages aren't being generated and it had crashed, so I don't think it's just an "it might fill the disk" issue
 johnmckerrell
commented
5 years ago
johnmckerrell
commented
5 years ago I said I'd reboot the electricity meter device but forgot, FYI.
On 8 Aug 2019, at 18:15, Adrian McEwen notifications@github.com wrote:
I'd had the mqtt.local Node RED open in a tab all afternoon, and just spotted there'd been a bunch of the "failed to connect to host" errors and a few connection refused ones too. Plus the power usage messages aren't being generated and it had crashed, so I don't think it's just an "it might fill the disk" issue
— You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub https://github.com/DoESLiverpool/somebody-should/issues/1210?email_source=notifications&email_token=AAAGU25AITSGHIWABILQOY3QDRICDA5CNFSM4IKITKW2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD34JVGA#issuecomment-519608984, or mute the thread https://github.com/notifications/unsubscribe-auth/AAAGU22QQRXGQEUCG25YF3TQDRICDANCNFSM4IKITKWQ.
MatthewCroughan
commented
5 years ago I got sidetracked tonight, I'll be providing NFS storage for this tomorrow, you've also mentioned needing storage for other things you're doing.
ajlennon
commented
5 years ago If it happens again @amcewen can you check if the IP is still working.
amcewen
commented
5 years ago What do you mean by "check if the IP is still working"? The Pi will still have been on the network when it was reporting the errors, as it'll have had a websocket connection to my browser for the debug output.
Happy to check things if I spot the problem (hasn't happened so far today), but not sure what I'm checking ;-)
ajlennon
commented
5 years ago Checking the IP address is responding rather than checking mqtt.local is responding
MatthewCroughan
commented
5 years ago @ajlennon in 2 hours I'm free, so I'll be setting it up then. What is it exactly that you need?
MatthewCroughan
commented
5 years ago NFS, or Influx? Because I can probably make a 1TB influx container that's available network-wide if that suits the architecture.
ajlennon
commented
5 years ago Dunno really. We need a policy on archiving data in the database...
MatthewCroughan
commented
5 years ago Well it seems to me that it would be as simple as running a single process and making it available on the network, and giving influx access to storage, wherever that may be. So this could be done one of two ways:
Nfs + Influx, where the Pi's all run influx servers and clients, and all talk to a single NFS or Influx + Direct I/O (Dedicated hardware for influxd, and also storage)
I don't know how realistic of a concern timestamping would be if we were to be writing to the database using a FUSE filesystem VS actually writing to Influx via HTTP as intended. I feel they're identical outcomes, but that writing to Influx via the network is more intended than via a networked filesystem, I'm sure the timestamps are preserved either way.
But what if the NFS were to go down? The failure mode is probably catastrophic for Influx, since it wouldn't know how to handle the filesystem not responding or going missing, or its response would be generic and unhelpful in debugging, whereas the http scenario probably has a sane response and is a documented scenario.
I think we should run Influx in a container on a machine with large storage, rather than providing arbitrary NFS to the Pi's for now, to make the problem easy to tackle, and provide some serious reliability. I'll take responsibility for maintaining that storage and server, although I can hand out ssh access to the container to anyone at DoES.
If we want to mesh this setup, we could have a bunch of Pi's running replicated instances and a few load balancer pi's, along with sort of notification/status that lets us see the status of each server. I don't like the idea of this data going missing, so we do need to set up fail-over.
We should be able to handle the load balancing and stuff like that with Balena easily shouldn't we @ajlennon ?
ajlennon
commented
5 years ago Firstly we want to ask @goatchurchprime if we want to retain all the data or bucket it up for archival somehow
MatthewCroughan
commented
5 years ago The server in question is already mirrored between two 4TB drives. Although we only have 4TB in that server at the moment which may need to increase, and no offsite backup. I have a bunch of 1TB drives going spare if we want to set up a decentralized 1TB setup between multiple nodes with Pi's. @ajlennon
How much data is currently in use that we're having trouble with it? I'm going to guess 32GB? What's the rate at which we were accumulating data? 16GB/month?
In fact, the data rate should be a metric in influx itself if we could prevent that from being a feedback loop, so we can see how fast we're ballooning up our storage.
amcewen
commented
5 years ago But if mqtt.local is responding then presumably the IP address is also responding, no?
ajlennon
commented
5 years ago In any sane world that would of course be true but no. I’ve chatted to @goatchurchprime about this as sometimes the m-DNS mapping somehow fails but the IP itself is reachable. So I’m interested to know if this might be happening here
MatthewCroughan
commented
5 years ago @ajlennon @amcewen I think that's because of the way the router is working. There's some sort of cache, I'm not familiar with why this happens, and it'll be a setting somewhere in the networking hardware we have.

The gateway remembers the mac address of hardware unit, in this case the Pi, and responds on both hangspot.local (it's previous recorded hostname) and also on mqtt.local

This is a caching feature, somewhere.
amcewen
commented
5 years ago yes, the mDNS mapping doesn't always work, so there are times when the mDNS doesn't work but the IP address does. However, I've not encountered the reverse where the mDNS works but the IP address doesn't. (Mostly because that's impossible :-D)
When I see the errors, they're transmitted over the network to my browser, so the IP address must be responding, no? They show up in the debug window of Node RED. I'm not doing any mDNS lookups.
ajlennon
commented
5 years ago Maybe I’m misunderstanding. Is your nodered flow talking to the IP address or MQTT.local?
amcewen
commented
5 years ago It's not my nodered flow, it's whatever you or @goatchurchprime set up.
Have had a look and it seems to be talking to influxdb. That doesn't resolve at present on my machine (either with ping influxdb or ping influxdb.local), so I don't know which IP address I'd need to try
MatthewCroughan
commented
5 years ago @ajlennon
Here's a comparison of what various operating systems and distros use for their domain, and there is a difference, annoyingly.



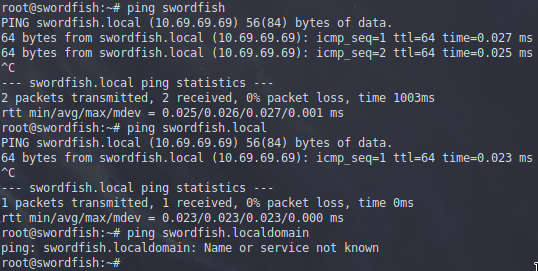
For some reason Debian (BalenaOS?) uses .localdomain
I'm testing lots of machines in DoES now and here's what I've found:
Adrian's laptop in Firefox works going to http://mqtt.local:1880 My laptop in Firefox *does not work going to http://mqtt.local:1880 Alex's PC works going to http://mqtt.local:1880 My Windows 10 Virtual machine does not work going to http://mqtt.local:1880 The Vinyl Cutter PC works going to http://mqtt.local:1880
The Vinyl Cutter PC pinging mqtt.local returns nothing Alex's PC pinging mqtt.local returns an IPV6 address. Adrian's laptop pinging mqtt.local returns an IPV4 address My Windows 10 Virtual machine pinging mqtt.local returns nothing. My laptop in Windows 10 pinging mqtt.local returns nothing.
ping mqtt and accessing http://mqtt:1880 works on everything
Why is is that Adrian's laptop might resolve these things, but that both my laptop and the virtual machine I have running wouldn't? I'm especially surprised that the Win10 virtual machine doesn't work, since I didn't think the hypervisor's networking would have anything to do with it, maybe it doesn't and I'm being paranoid. Am I missing a package that Adrian doesn't have?
MatthewCroughan
commented
5 years ago @amcewen I think influxdb/influxdb.local is only accessible from within the device itself, since this is all happening with Docker via BalenaOS, so this is just an internal hostname for the containers to speak to. @ajlennon will correct me if I'm wrong.
ajlennon
commented
5 years ago The host is mqtt as I recall. There’s internal networking which allows containers to talk to each other (hence influxdb as this is the name of a container) but I don’t think there’s any reason these should be accessible externally ...
MatthewCroughan
commented
5 years ago @ajlennon I'm about to make an InfluxDB container on my server here in the space with access to 1TB of storage, that should be enough to keep us happy for a while, is this acceptable?
amcewen
commented
5 years ago I've changed the title of this issue, given that the influxdb hadn't run out of space; the original issue was that the mqtt.local had stopped responding (the Node RED install accessed via mqtt.local was definitely not accessible; IIRC @ajlennon tried to ssh in, or pinged it too, so maybe tried that via its IP address(?))
A (potentially secondary issue, or maybe the actual issue) is that the energy usage reporting still isn't working.
I've spun the influxdb storage issue out as #1213. @MatthewCroughan, if there's an actual (DoES Liverpool-related) issue you're trying to solve with all your mDNS ramblings, can you spin that out on its own.
ajlennon
commented
5 years ago I guess I’m not making myself clear enough:
Thanks
amcewen
commented
5 years ago For future reference (although I don't think it's going to affect anything) the (current) IP address for mqtt.local is 10.0.30.194.
However, I'm obviously not making myself clear enough. The "failed to connect to host" and "ECONNREFUSED" errors that I've been reporting are things that I can see on the Node RED debug window from the Node RED instance running on mqtt.local.
So the fact that I can see those messages means that that text has been transmitted from the IP address 10.0.30.194 to my computer. So when it happens, the computer at mqtt.local is working. The errors seem to be coming from the InfluxDB node in the Node RED flow, and that seems to be talking to a server at host influxdb.
I am not trying to connect to the host influxdb. I can well believe that it's some internal networking thing happening between containers on the Raspberry Pi at mqtt.local
If I notice it happening I will see if I can ping mqtt.local and 10.0.30.194, but I'm pretty sure that's got nothing to do with it
ajlennon
commented
5 years ago Excellent. That's what's needed. Thanks. We'll move on from there when it fails again.
amcewen
commented
5 years ago It seems that mqtt.local has been rebooted at some point since Saturday evening, and is now at 10.0.30.130.
ajlennon
commented
5 years ago @MatthewCroughan I see the broker box has been nicely mounted on the wall now. Would you have rebooted it since Saturday evening doing that?
MatthewCroughan
commented
5 years ago @ajlennon I should have documented it here, I didn't do it Saturday evening, I did it Sunday evening. I unplugged the orange ethernet cable for 25 seconds about whilst hanging up a new ethernet switch to provide ethernet to more things, since that was the only socket that seemed to give me a local IP.
ajlennon
commented
5 years ago The dashboard display is failing to connect to grafana on the broker box this morning
ajlennon
commented
5 years ago I seem to be able to ping it though and I can connect to the grafana instance from my laptop
ajlennon
commented
5 years ago This was because the IP had changed of the broker. I've updated the IP for the dash board
ajlennon
commented
5 years ago Did a quick test SSHing to mqtt.local. It doesn't work although mqtt.local is running.
I think this must be because we have a "Prod" BalenaOS image on it which doesn't provide an SSH server.
I mention this as we can't take lack of an ability to make an SSH connection from a device on the local network segment as an indication that the broker has failed (which I assumed in my quick testing last Thursday)
 skos-ninja
commented
5 years ago
skos-ninja
commented
5 years ago @ajlennon fyi I have made it so that our router will now respond to mqtt.local with 10.0.100.1 even if the devices don't support mDNS but are respecting the network level DNS server
ajlennon
commented
5 years ago oh that's lovely! great job! can we do that with other DNS entries...?
skos-ninja
commented
5 years ago Not easily no. It's a bit of a hack with the security gateway as it's technically not a supported feature.
I might be able to work on enabling their multicast support that will allow the router to announce mDNS responses so that it will work for any address however it's one we have to be careful with as it can also be very easily abused.
ajlennon
commented
5 years ago OK no worries. Thanks. It's just I'm going to need a number of DNS entries somewhere for the OpenBalena server I need to set up in #1221
skos-ninja
commented
5 years ago @ajlennon As that's part of the management infra that's required to keep some stuff running then if you ping me at the time of needing the addresses I can set them up it just involves me having to directly SSH into our router to run some commands 😂
ajlennon
commented
5 years ago Sounds good to me! Will let you know when I have a DoES OpenBalena setup then
 goatchurchprime
commented
5 years ago
goatchurchprime
commented
5 years ago The patch file that enables mDNS in ESP32s is here: https://github.com/micropython/micropython/commit/2ccf030fd1ee7ddf7c015217c7fbc9996c735fd1#diff-f988a2802dfa37e6f8f64fd5b634fd57R61
Note that, as per the specification, it's only ".local" that this applies to. The same is probably true with our sonoff plugs. I have no idea where this ".localdomain" stuff is coming from.
If I ping julianlaptop.localdomain I get: 10.0.29.2.
If I ping julianlaptop.local I get: 172.17.0.1. (I have no idea what this ipnumber means.)
Using the new firmware on the ESP32, the function socket.getaddrinfo("julianlaptop.local", 80) now returns: [(2, 0, 0, 'julianlaptop.local', ('10.0.29.2', 80))].
The "mqtt.local" doesn't convert/respond when I ping it or try to get info on it from my laptop of the ESP32. This is probably why the power meter downstairs isn't working, since it cannot find the mqtt broker.
Doing some searching around, it appears that the ".localdomain" thing might be a cockup, leaked from redhat linux, and initially it was only as "localhost.localdomain" as being an alias of "localhost". https://x-yuri.github.io/pages/mailing-lists/localhost.localdomain.html#id_44 Possibly some nasty feature creep caused it to do something similar (but not exactly the same) as the ".local".
skos-ninja
commented
5 years ago In this case it seems like the flakeyness in mDNS respons is due to the fact that mqtt runs on .local however our network runs on .localdomain. This can be changed however we need to make sure this doesn't cause any other issues by doing so
goatchurchprime
commented
5 years ago I can only find "*.local" mentioned in any documentation, eg: https://en.wikipedia.org/wiki/Multicast_DNS
I can't find any sources for what "*.localdomain" is supposed to mean. Is it something implemented in the router, and is there some documentation about what it's doing that could resolve all these strange happenings?
ajlennon
commented
5 years ago We've been wondering for a very long time why Windows boxes don't resolve correctly on .local and you have to use .localdomain instead....
Let's use .local
Since yesterday the Liverbird hasn't been showing our energy usage.
Doing a bit of poking into it, I found that
mqtt.localwas offline. @ajlennon power-cycled it, which has brought it back up, but it's failing to connect to its influxdb instance.