 Draymonders
commented
3 years ago
Draymonders
commented
3 years ago 基础篇
查询
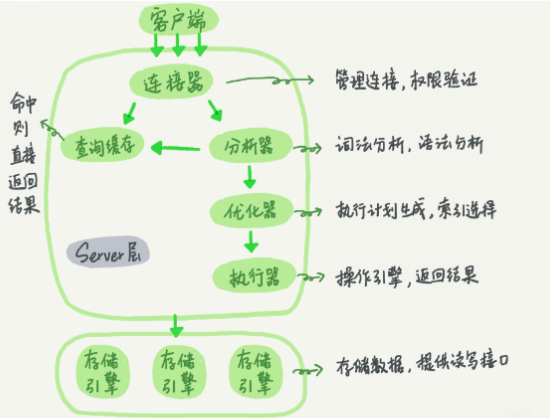
更新
- redolog
WAL(write ahead logging),关键点就是先写日志,再写磁盘。
redolog可以感性的认为是个环状链表, head到tail中间的是已经写log到磁盘,但还没写数据到磁盘中。
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe
redo log 是 InnoDB 引擎特有的日志
- binlog
redolog和bin的log不同
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
示例
update T set c = c+1 where ID = 2; 这句话执行pipeline
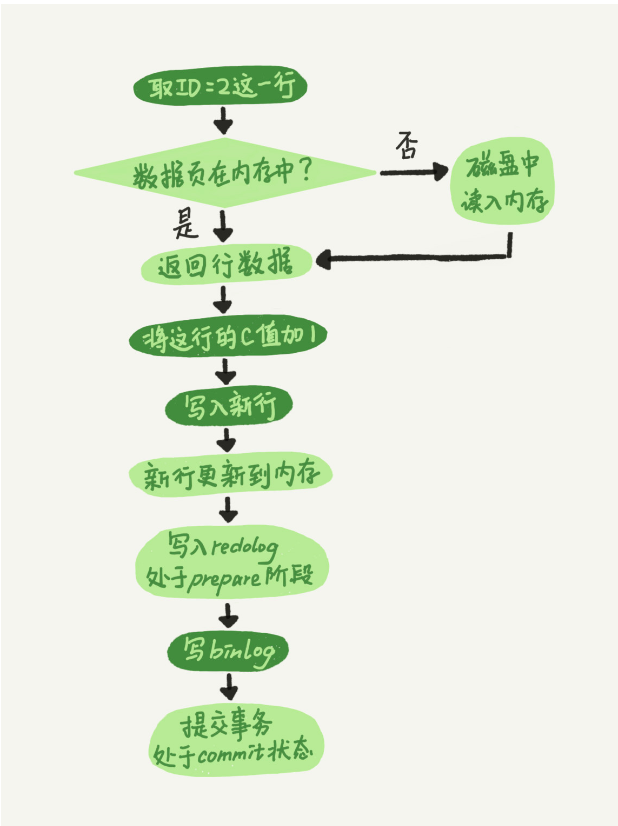
redo log 的写入拆成了两个步骤:prepare 和 commit,这就是"两阶段提交"
现在常见的做法也是用全量备份加上应用binlog 来实现的,这个“不一致”就会导致你的线上出现主从数据库不一致的情况。
简单说,redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。
事务
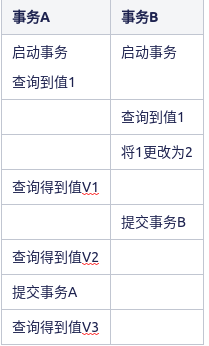
若隔离级别是“读未提交”, 则 V1 的值就是 2。这时候事务 B 虽然还没有提交,但是结果已经被 A 看到了。因此,V2、V3 也都是 2”的时候,会被锁住。直到事务
若隔离级别是“读提交”,则 V1 是 1,V2 的值是 2。事务 B 的更新在提交后才能被 A看到。所以, V3 的值也是 2。
若隔离级别是“可重复读”,则 V1、V2 是 1,V3 是 2。之所以 V2 还是 1,遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的。
在实现上,数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准。在“可重复读”隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图。在“读提交”隔离级别下,这个视图是在每个 SQL 语句开始执行的时候创建的。这里需要注意的是,“读未提交”隔离级别下直接返回记录上的最新值,没有视图概念;而“串行化”隔离级别下直接用加锁的方式来避免并行访问。
若隔离级别是“串行化”,则在事务 B 执行“将 1 改成 2”的时候,会被锁住。直到事务 A 提交后,事务 B 才可以继续执行。所以从 A 的角度看, V1、V2 值是 1,V3 的值是 2。
查看当前数据库隔离级别 show variables like "transaction_isolation";
索引
索引的出现是为了提高查询效率
- hash索引,单数据
O(1),区间查O(n) - 多叉搜索树,但数据和区间查都是
O(logn)
InnoDB使用B+树作为索引存储结构。
主键索引和普通索引
create table T (
id int primary key,
k int not null,
name varchar(16) ,
index(k)
) engine=InnoDB;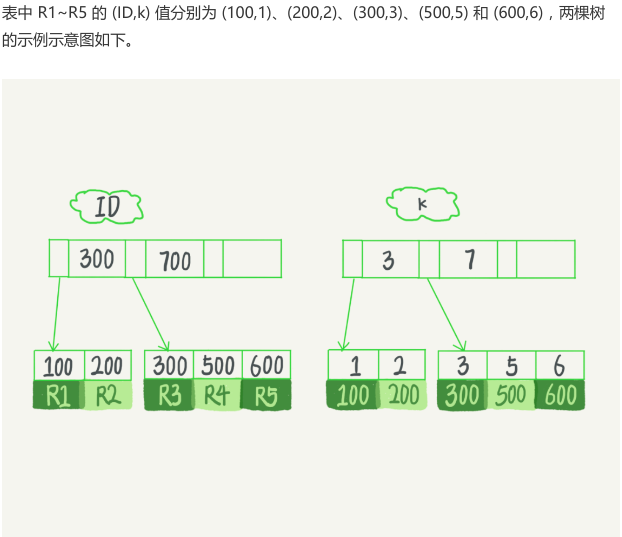
根据叶子节点的内容,索引类型分为主键索引(聚簇索引)和非主键索引
- 主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引
基于主键索引和普通索引的查询有什么区别?
- 如果语句是
select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵B+ 树 - 如果语句是
select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
覆盖索引
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段(覆盖索引可以理解为,where的字段和select的字段的组合,这样就不需要回表了)
比如根据身份证查询名称业务,可以建(id_card, name)的索引,这样就不用查到id_card还回主键索引树上去查对应的name。
最左匹配原则
拍拍脑袋都知道233
索引下推
就是个trick,能在当前普通索引里做的检索,就在当前索引里面做,避免一些回表情况。
总结
当数据量大的时候,可以适当重建索引,减少索引文件的大小,提升索引检索的效率
锁
分为全局锁,表锁,行锁
全局锁
全局锁的典型使用场景是,做全库逻辑备份。
Flush tables with read lock (FTWRL)
如果是InnoDB引擎,可以使用 mysqldump备份数据; 当 mysqldump 使用参数–single-transaction的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于 MVCC 的支持,这个过程中数据是可以正常更新的。
表级锁
lock tables T read/write, unlock tables
行级锁
行级锁,也是锁的有索引的,如果要查的表的列没有加索引,则是 表级锁。
在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
如果事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁的申请时机尽量往后放。
考虑到用锁就会发生,死锁和死锁检测
MVCC
同一行不同transaction_id,每次需要的时候根据当前版本和 undo log去取对应行的对应数据
在事务可重复读中,读的时候是按照创建时候的快照去读的,但是如果中间已经有其他事务更新了对应字段的值,那么当前事务是会取该字段最新的值去做更新操作的。

更新数据都是先读后写的,而这个读,只能读当前的值,称为“当前读”(current read)
事务 C’没提交,也就是说 (1,2) 这个版本上的写锁还没释放。而事务 B 是当前读,必须要读最新版本,而且必须加锁,因此就被锁住了,必须等到事务 C’释放这个锁,才能继续它的当前读
MySQL
MySQL存储引擎
InnoDB,MyISAM,Memory查看变量
SHOW VARIABLES LIKE 'default_storage_engine';默认存储引擎SHOW VARIABLES LIKE 'max_connections';最大连接数SHOW VARIABLES LIKE 'default%';支持模糊匹配SHOW STATUS LIKE 'thread%';查看当前会话的线程状态字符集
有⼀点需要注意,在MySQL中
utf8是utf8mb3的别名,所以之后在MySQL中提到utf8就意味着使⽤1~3个字节来表⽰⼀个字符,如果⼤家有使⽤4字节编码⼀个字符的情况,⽐如存储⼀些emoji表情啥的,那请使⽤utf8mb4SHOW VARIABLES LIKE 'character_set_server';查看服务端的字符集SHOW VARIABLES LIKE 'collation_server';查看服务端的字符排序规则当前我的系统排序规则为
utf8_general_ci_aiaccent insensitive 不区分重⾳_asaccent sensitive 区分重⾳_cicase insensitive 不区分⼤⼩写_cscase sensitive 区分⼤⼩写_binbinary 以⼆进制⽅式⽐较MyISAM和InnoDB的区别
MyISAM相比InnoDB不支持事务,MVCC,外键; 以及MyISAM是表级锁,InnoDB是行级锁看到P55