 Draymonders
commented
4 years ago
Draymonders
commented
4 years ago Open Draymonders opened 4 years ago
Draymonders
commented
4 years ago Draymonders
commented
4 years ago 其中zk-kafka_kafka_1是docker container唯一标识
docker exec zk-kafka_kafka_1 kafka-topics.sh --create --topic draymonder --partitions 3 --zookeeper zookeeper:2181 --replication-factor 1docker exec zk-kafka_kafka_1 kafka-topics.sh --list --zookeeper zookeeper:2181 draymonder
docker exec zk-kafka_kafka_1 kafka-topics.sh --describe --topic draymonder --zookeeper zookeeper:2181Topic: draymonder PartitionCount: 3 ReplicationFactor: 1 Configs: Topic: draymonder Partition: 0 Leader: 1001 Replicas: 1001 Isr: 1001 Topic: draymonder Partition: 1 Leader: 1001 Replicas: 1001 Isr: 1001 Topic: draymonder Partition: 2 Leader: 1001 Replicas: 1001 Isr: 1001
4. 消费者消费消息
```shell
docker exec zk-kafka_kafka_1 kafka-console-consumer.sh --topic draymonder --bootstrap-server 10.40.58.64:9092docker exec -it zk-kafka_kafka_1 kafka-console-producer.sh --topic draymonder --broker-list 10.40.58.64:90921. new Producer()
2. producer.send()
3. producer.close() // 重要,必须要关闭close, 否则会导致缓冲区的数据发送不出去。 close会先把缓冲区的数据分发出去再关闭。todo: 阅读producer源码
负载均衡需要client来定义, 继承Partitioner接口
Draymonders
commented
4 years ago kafka-consumer-groups.sh --bootstrap-server localhost:9092 --all-groups --listkafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group manual_commit_offset --offsetsDraymonders
commented
4 years ago 数据流向
todo: 以后用到了再学
Draymonders
commented
4 years ago message length: 4 bytes (value: 1+4+n) // 消息长度, 不算自身, 可以理解为header
"magic" value: 1 byte //版本号
crc: 4 bytes //CRC校验码
payload: n bytes // 具体的消息 segement_index -> real_offset -> real_record 的映射,并利用顺序append,提高了效率文件->内核->用户缓冲区->socket->消费者进程文件->内核->socket->消费者进程 auto.create.topics.enable = falsedelete.topic.enable=trueDraymonders
commented
4 years ago 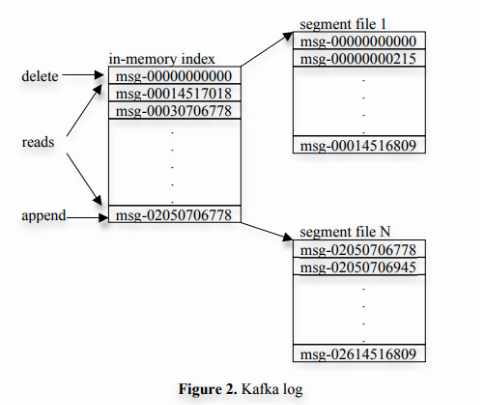
 youge-dev
commented
4 years ago
youge-dev
commented
4 years ago
名词解释
Producer生产者Consumer消费者kafka server
Record消息 Kafka 处理的主要对象。Topic主题 主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。生产者生产Topic, 消费者消费TopicOffset表示分区中每条消息的位置信息,是一个单调递增且不变的值。BrokerKafka 的服务器端由被称为Broker的服务进程构成,即一个Kafka集群由多个Broker组成,Broker负责接收和处理客户端发送过来的请求,以及对消息进行持久化。Partition分区,Kafka中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区 0 中,要么在分区 1 中。如你所见,Kafka的分区编号是从 0 开始的,如果 Topic 有 100 个分区,那么它们的分区号就是从 0 到99。副本, 副本是在分区概念下的,每个分区下可以配置若干个副本。
Leader, 提供client读写Follower, 只用于高可用,client不可读写。点对点模型
p2pConsumer Group在 Kafka 中实现这种 P2P 模型的方法就是引入了消费者组(Consumer Group)。所谓的消费者组,指的是多个消费者实例共同组成一个组来消费一组主题。这组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费它。Consumer Offset每个消费者在消费消息的过程中必然需要有个字段记录它当前消费到了分区的哪个位置上,这个字段就是消费者位移(Consumer Offset)Kafka为什么客户端不可读写Follower副本
Leader-Follower同步Consumer Offset存在一致性问题, 实现复杂。