 ndkeen
commented
1 year ago
ndkeen
commented
1 year ago With ne256 monogrid, which we were already using, I also see similar error. It happens approximately similar model date as well model date = 00010525 (with ne120 failing about a month after this).
0: MCT::m_Router::initp_: GSMap indices not increasing...Will correct
311: WARNING: Tl1_1 has 1 values <= allowable value. Resetting to minimum value.
285: WARNING:CAAR: k=128,theta(k)=99.975185<100.000000=th_thresh, applying limiter
285: WARNING:CAAR: k=128,theta(k)=99.975185<100.000000=th_thresh, applying limiter
285: WARNING:CAAR: k=128,theta(k)=99.723051<100.000000=th_thresh, applying limiter
...
236: what(): /global/cfs/cdirs/e3sm/ndk/repos/se53-feb13/components/eamxx/src/share/atm_process/atmosphere_process.cpp:307: FAIL:
236: false
236: Error! Failed post-condition property check (cannot be repaired).
236: - Atmosphere process name: SurfaceCouplingImporter
236: - Property check name: NaN check for field surf_radiative_T
236: - Atmosphere process MPI Rank: 236
236: - Message: FieldNaNCheck failed.
236: - field id: surf_radiative_T[Physics PG2] <double:COL>(4096) [K]
236: - entry (815857)
236: - lat/lon: (-33.207194, 291.181688)
236:
236: *************************** INPUT FIELDS ******************************
236:
236: ------- INPUT FIELDS -------
236:
236: ************************** OUTPUT FIELDS ******************************
236: T_2m<COL>(4096)
236:
236: T_2m(3696)
236: 152.521,
236: -----------------------------------------------------------------------
236: qv_2m<COL>(4096)
236:
236: qv_2m(3696)
236: 1.44605e-06,
236: -----------------------------------------------------------------------
236: sfc_alb_dif_nir<COL>(4096)
236:
236: sfc_alb_dif_nir(3696)
236: 0.221189,
236: -----------------------------------------------------------------------
236: sfc_alb_dif_vis<COL>(4096)
236:
236: sfc_alb_dif_vis(3696)
236: 0.120901,
236: -----------------------------------------------------------------------
236: sfc_alb_dir_nir<COL>(4096)
236:
236: sfc_alb_dir_nir(3696)
236: 0.215391,
236: -----------------------------------------------------------------------
236: sfc_alb_dir_vis<COL>(4096)
236:
236: sfc_alb_dir_vis(3696)
236: 0.12062,
236: -----------------------------------------------------------------------
236: snow_depth_land<COL>(4096)
236:
236: snow_depth_land(3696)
236: 0.000192775,
236: -----------------------------------------------------------------------
236: surf_evap<COL>(4096)
236:
236: surf_evap(3696)
236: -6.77864e-06,
236: -----------------------------------------------------------------------
236: surf_lw_flux_up<COL>(4096)
236:
236: surf_lw_flux_up(3696)
236: -48.6872,
236: -----------------------------------------------------------------------
236: surf_mom_flux<COL,CMP>(4096,2)
236:
236: surf_mom_flux(3696,:)
236: -33.4984, -10.6215,
236: -----------------------------------------------------------------------
236: surf_radiative_T<COL>(4096)
236:
236: surf_radiative_T(3696)
236: -nan,
236: -----------------------------------------------------------------------
236: surf_sens_flux<COL>(4096)
236:
236: surf_sens_flux(3696)
236: 5089.09,
236: -----------------------------------------------------------------------
236: wind_speed_10m<COL>(4096)
236:
236: wind_speed_10m(3696)
236: 61.7287,
236: -----------------------------------------------------------------------
236:
236:
236: Program received signal SIGABRT: Process abort signal.
236:
236: Backtrace for this error:
/pscratch/sd/n/ndk/e3sm_scratch/pm-gpu/se53-feb13/t.se53-feb13.F2010-SCREAMv1.ne256pg2_ne256pg2.pm-gpu.n096t4xX.long bartgol
bartgol crterai
crterai


 whannah1
whannah1
 PeterCaldwell
PeterCaldwell mt5555
mt5555 bogensch
bogensch And associated convergence/divergence from domega/dP
And associated convergence/divergence from domega/dP

 I've changed the T diff color bars to a wider color range.
I've changed the T diff color bars to a wider color range.  oksanaguba
oksanaguba If we compare with the actual timestep-to-timestep temperature differences (top row of plot below), the radiative temperature tendencies (including the cooling) are larger in magnitude (bottom row of plot below). However, it's not clear whether the radiative cooling is located in the same location as the actual cooling, so I'll need to look at this more carefully.
If we compare with the actual timestep-to-timestep temperature differences (top row of plot below), the radiative temperature tendencies (including the cooling) are larger in magnitude (bottom row of plot below). However, it's not clear whether the radiative cooling is located in the same location as the actual cooling, so I'll need to look at this more carefully.

 1) It's odd that the SUM of processes does not add up to be the delta T_mid, but
2) overall, even with the lack of closure, it looks quite convincingly that the temperature tendency in homme is the largest contributor to the temperature change.
Sanity check: we're not dribbling any temperature tendencies from physics in homme, are we (I always mix up what the different ftypes connote)?
1) It's odd that the SUM of processes does not add up to be the delta T_mid, but
2) overall, even with the lack of closure, it looks quite convincingly that the temperature tendency in homme is the largest contributor to the temperature change.
Sanity check: we're not dribbling any temperature tendencies from physics in homme, are we (I always mix up what the different ftypes connote)? 
 So there are clouds, both qc and qi. And the units for the rrtmgp temp tendencies say
So there are clouds, both qc and qi. And the units for the rrtmgp temp tendencies say {kind=link}
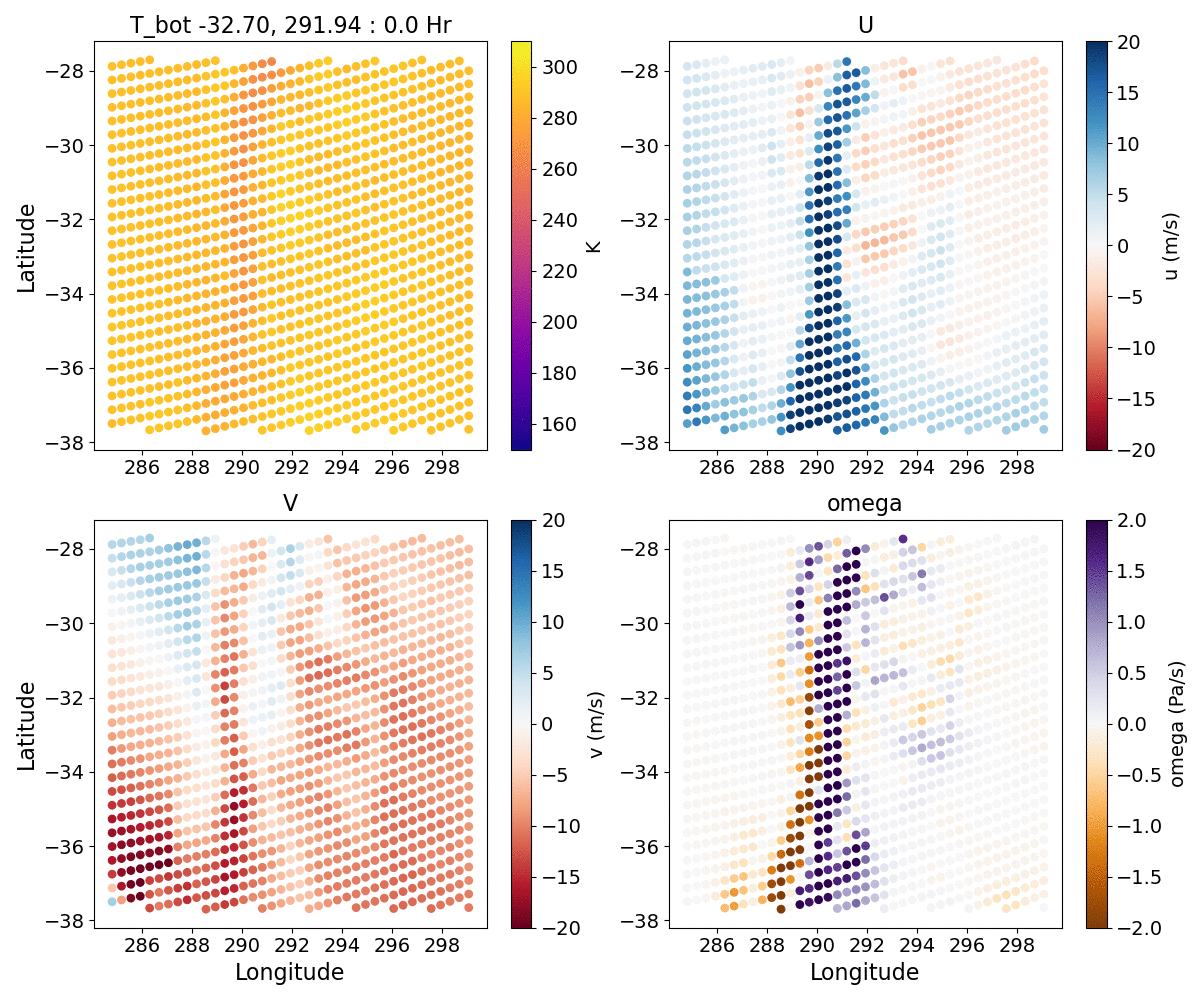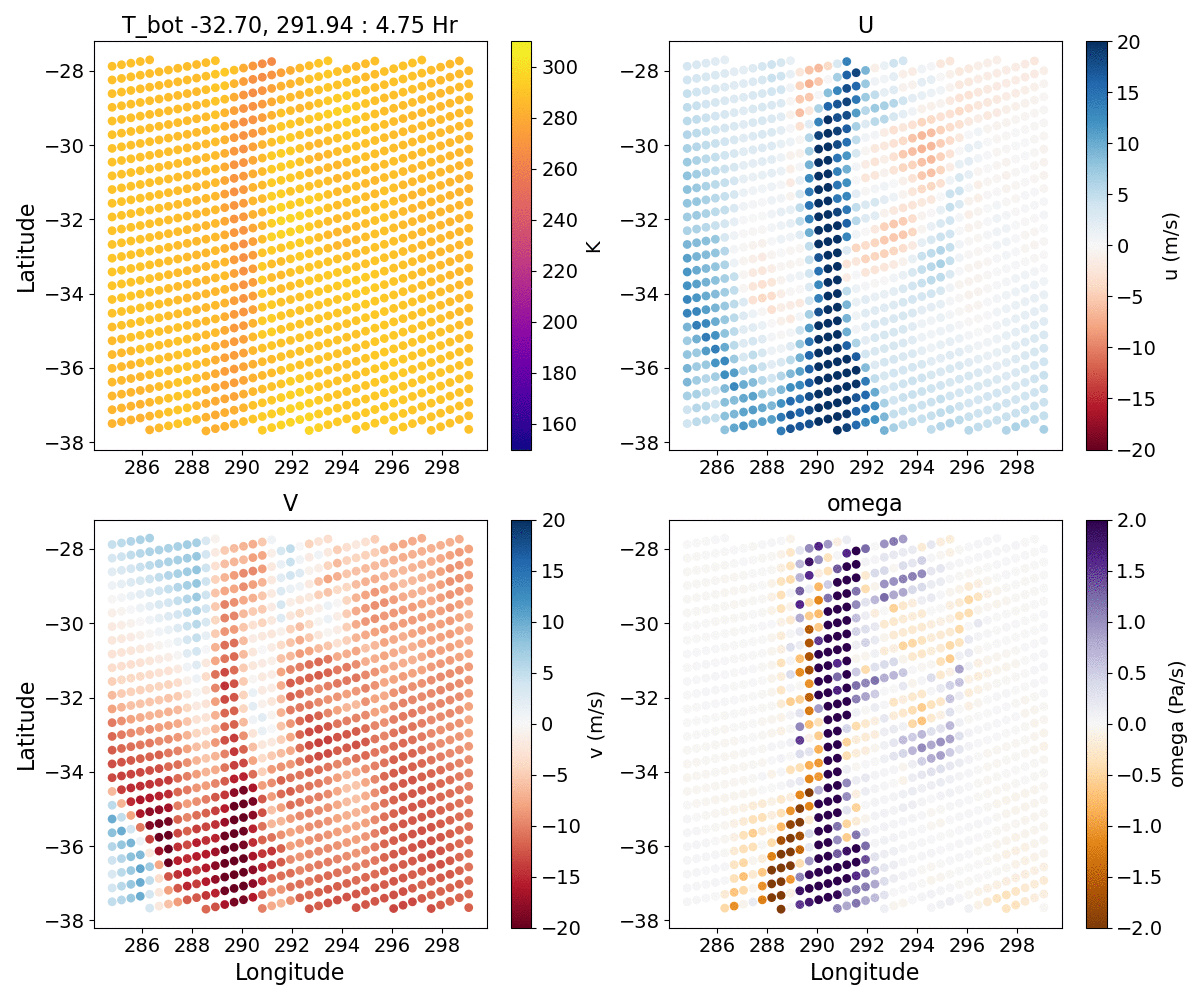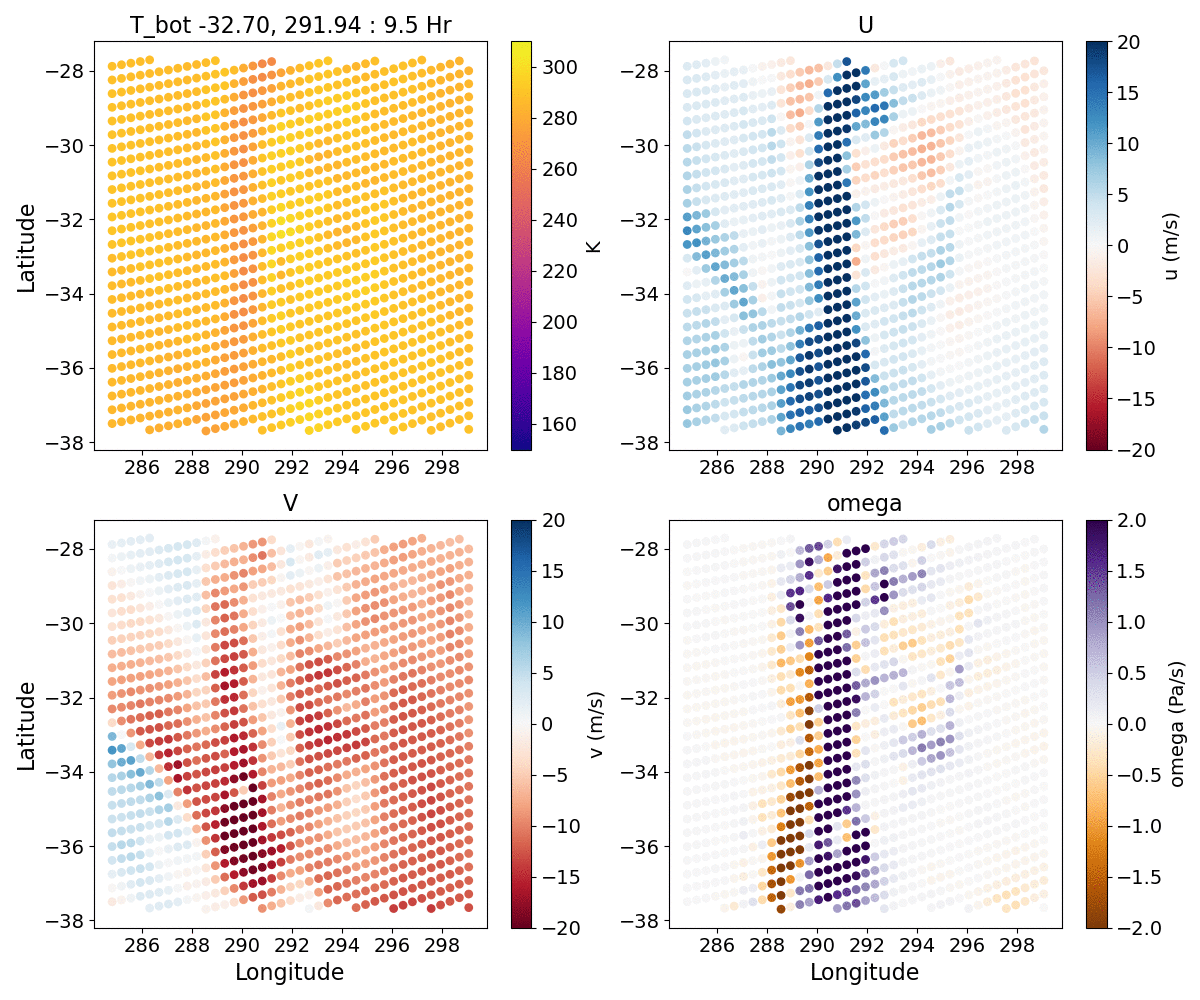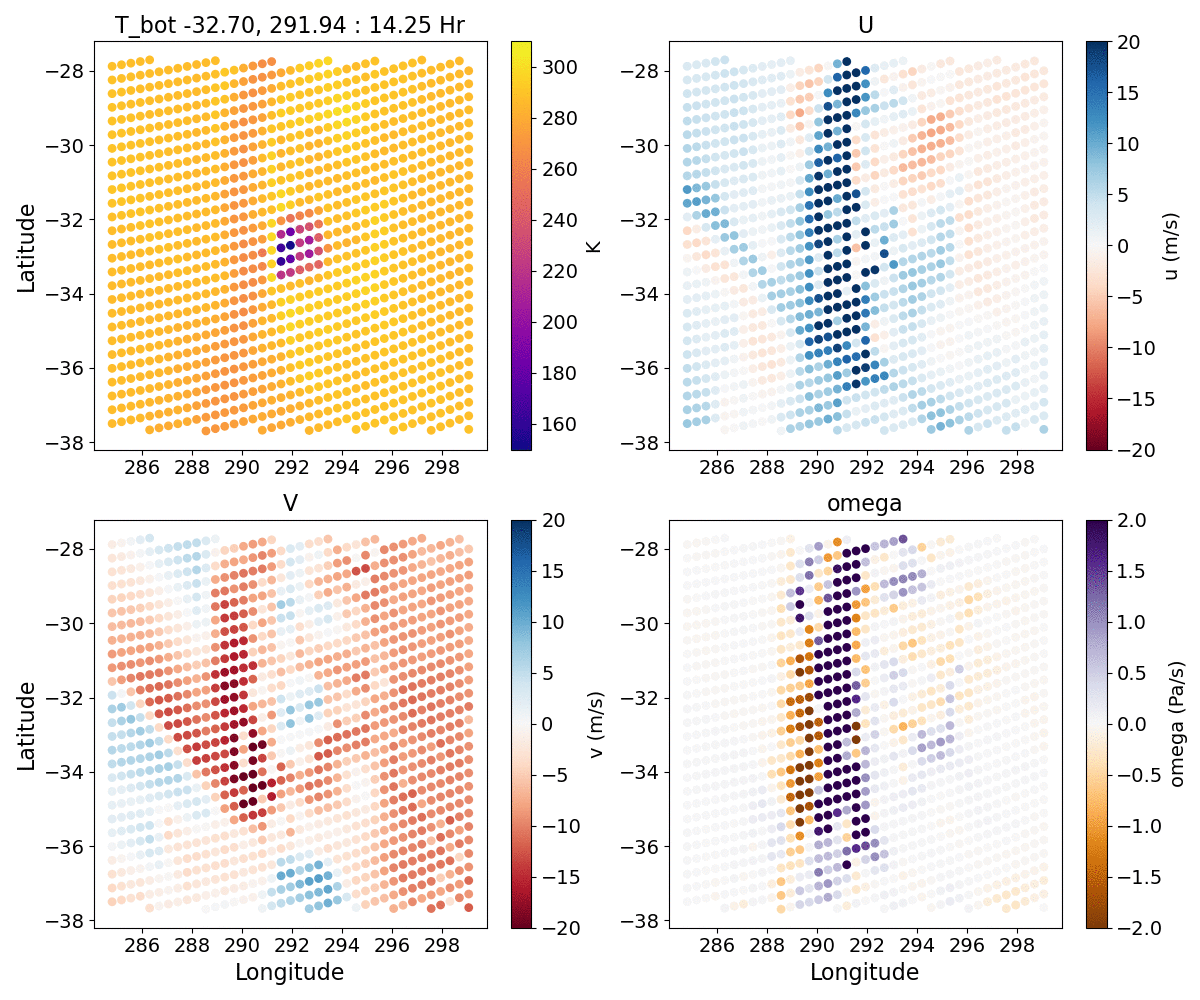{kind=link}
Using ne120 monogrid, and the recently created 128 vertical level IC, I tried to run longer on pm-gpu, but it failed
I have two cases that fail the same way, one with 43 nodes and one using 85 nodes. Both stop at
model date = 00010630, step 17336.First I see the
Tl1_1 has 1 values <= allowable value, immediately followed by the CAAR warnings:And then first Error! message: