 sam-paech
commented
7 months ago
sam-paech
commented
7 months ago Hi Krisseck,
There isn't currently a formal submission process for the creative writing test. However if you have interesting models / results to share I will be happy to take a look and reproduce any that look interesting using claude-opus, for inclusion on the leaderboard.
 Krisseck
Krisseck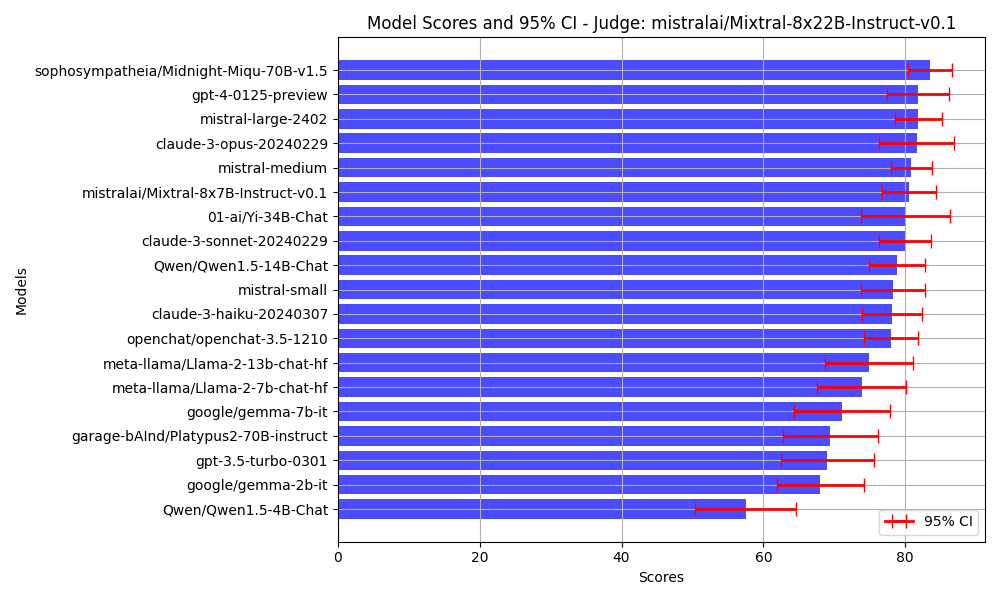{kind=link}
I'd like to contribute the Creative Writing benchmark.
Since I live in the EU, I do not have access to the Claude API. I am currently running using Mixtral 8x22B as the judge via Mistral API.
Can I contribute those results? Also, is there any tutorial on how to share the results, do I just make a PR? 🙂