We present MocapNET, a real-time method that estimates the 3D human pose directly in the popular Bio Vision Hierarchy (BVH) format, given estimations of the 2D body joints originating from monocular color images. Our contributions include: (a) A novel and compact 2D pose NSRM representation. (b) A human body orientation classifier and an ensemble of orientation-tuned neural networks that regress the 3D human pose by also allowing for the decomposition of the body to an upper and lower kinematic hierarchy. This permits the recovery of the human pose even in the case of significant occlusions. (c) An efficient Inverse Kinematics solver that refines the neural-network-based solution providing 3D human pose estimations that are consistent with the limb sizes of a target person (if known). All the above yield a 33% accuracy improvement on the Human 3.6 Million (H3.6M) dataset compared to the baseline method (MocapNET) while maintaining real-time performance
I am not sure that I understand your question. There is no clear "mapping" part. MocapNET is an end-to-end neural network 3D pose estimator. The neural network has been trained to get NSDM matrices as Input and directly output BVH output.
The MNET3Classes function receives a populated std::vector mnetInput with the input packed in a NSDM matrix and will give you back a vector that is ready to be appended to a BVH file.
 AmmarkoV
commented
4 years ago
AmmarkoV
commented
4 years ago 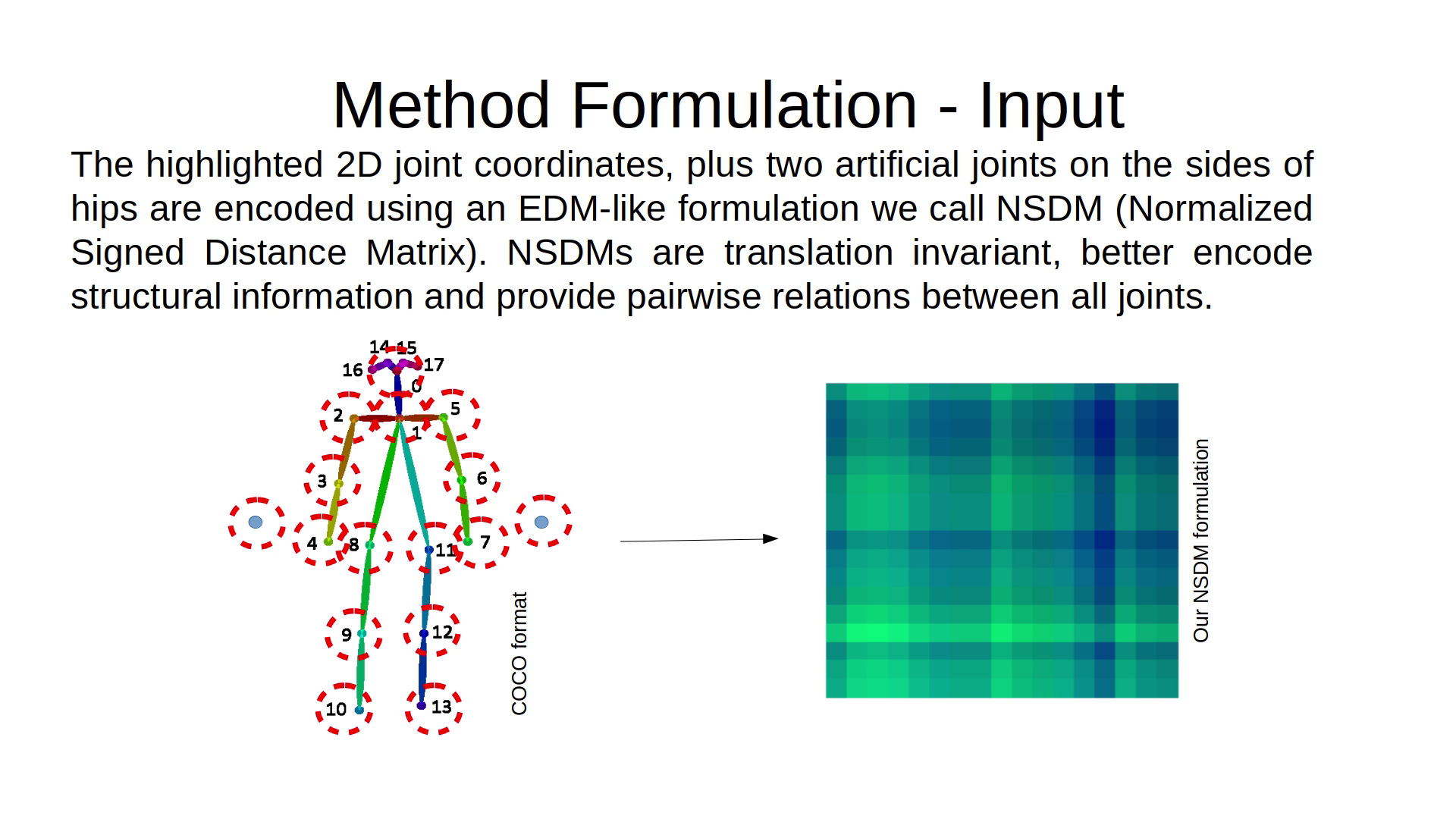

Hi,
Can I learn where the mapping part is where 2D-3D conversion is performed.
Thanks