 AmmarkoV
commented
5 years ago
AmmarkoV
commented
5 years ago Hello! Thank you for your kind words!
Any source of 2D joints can be used "out of the box" as long as it has the following Joints : HIP,NECK,HEAD,RSHOULDER,RELBOW,RHAND,LSHOULDER,LELBOW,LHAND,RHIP,RKNEE,RFOOT,LHIP,LKNEE,LFOOT since they are the joints used to generate the NSDM matrices internally used by the neural network, as seen in the following illustrations.
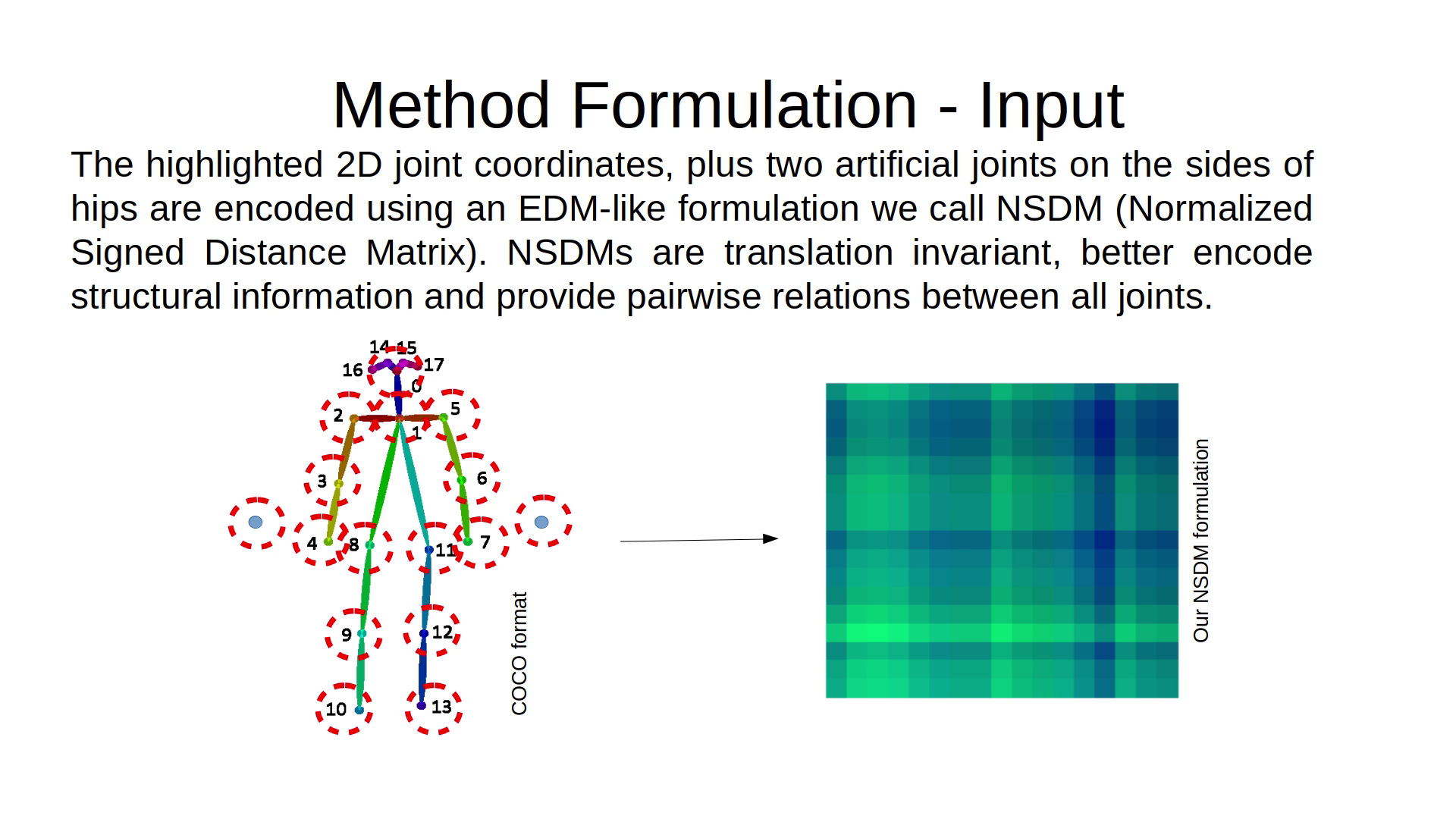

Right now the use case was a real-time demo of a single person, but due to the fast-enough evaluation speed on the 2D to 3D part multiple persons could be handled using iterative runs for every skeleton detected ( framerate should be ok for 1-3 persons but gradually slower ).
The easiest way to do a conversion from an arbitrary 2D joint estimator I think is by using the CSV file format -> https://github.com/FORTH-ModelBasedTracker/MocapNET/blob/master/dataset/sample.csv
If the output is dumped in a csv file using this format then output can be very quickly tested through MocapNET using :
./MocapNETJSON --from YourDataset.csv --visualize
The CSV file format is very easy to write and parse (especially from python), the only caveat and possible pitfall is that the csv file has normalized coordinates that are expected to have a 1.777* aspect ratio since the original cameras I am targeting are GoPro cameras configured for 1920x1080@120fps+. If you have a different video input resolution the normalization step will have to respect this aspect ratio. Of course the code that I use to preserve the aspect ratio regardless of input is included in the repository and can be used for reference https://github.com/FORTH-ModelBasedTracker/MocapNET/blob/master/MocapNETLib/jsonMocapNETHelpers.cpp#L498 and using the normalizeWhileAlsoMatchingTrainingAspectRatio call https://github.com/FORTH-ModelBasedTracker/MocapNET/blob/master/MocapNETLib/jsonMocapNETHelpers.cpp#L174
That being said, I will clone HRNET and try it out :) 2D accuracy is very important in two-stage 3D pose estimation! Multiple person 3D tracking would also be very cool!
 timtensor
timtensor
Hi , first of all great work. I was wondering if it could be extended to
HrNETas it is supposed to highly accurate ? Here is an implementation of it . I think it is possible , to dump thejsonfile per frame format in for the keypoints. It is based oncocokeypoints . Link to the repo simpleHRNETThere is a demo script here demo_script
The keypoints are outputted here keypoints The keypoint is array type of
Nx17x3where N is number of persons. Please let me know what you think about it ?