 GENZITSU
commented
3 years ago
GENZITSU
commented
3 years ago Open GENZITSU opened 3 years ago
GENZITSU
commented
3 years ago GENZITSU
commented
3 years ago オプティム社のテックブログ。 オプティムはKDDIと上野公園の混雑度情報を提供しているさん会社です。
Multiple Object Tracking(MOT)とは、映像に写っている複数の物体を追跡する手法。 MOTではそれぞれの追跡物体にIDを割り振りますが、同じ対象物には可能な限り同じIDを与え続ける

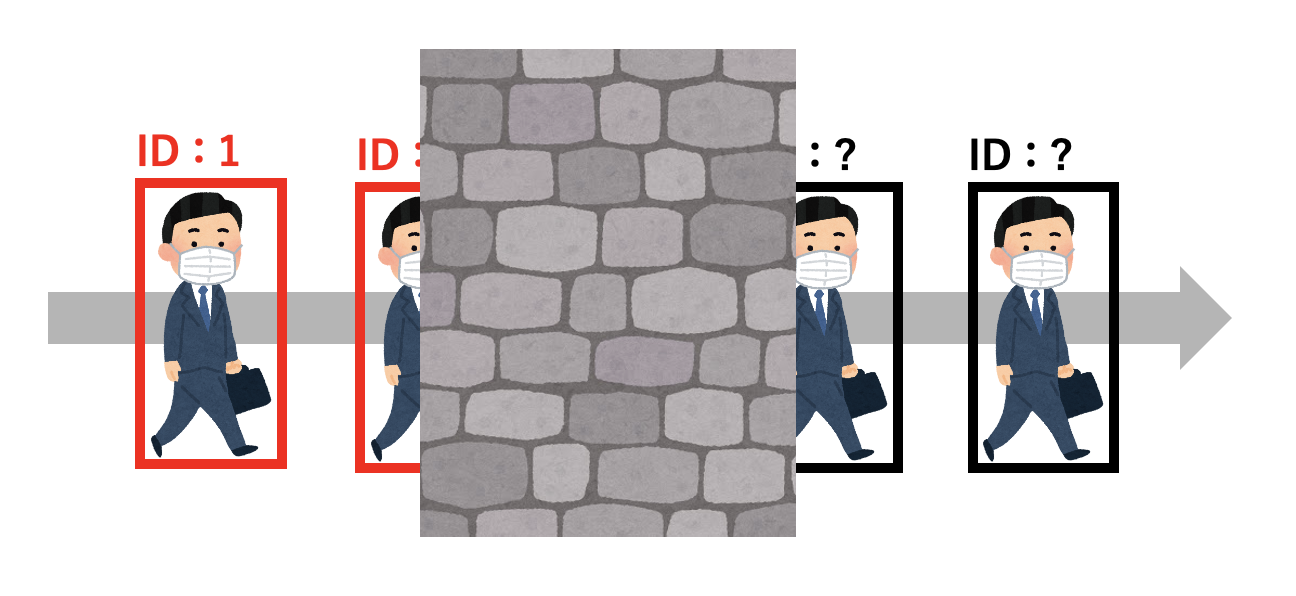

MOTにはTracking-by-Detectionというパラダイムがあります。物体検出(Detection)した結果を用いて、別の手法によって物体追跡(Tracking)を行うというもの 物体追跡の手法は多種多様ですが、多くはカルマン・フィルタやパーティクル・フィルタ 、SORT やオプティカル・フローといった複数の手法を組み合わせて実現 最近では、TrackingとDetectionをまとめた E2E モデルも増えてきています。
処理速度的にはtracing by detectionの方が早い。
FairMOTやTransMOTなどがsotaなモデル。
FairMOT
FairMOT は少し前まで多くのベンチマークでsotaを獲得していた手法。 One-Shotなモデルであり、フレームを入力することでDetectionとReIDがまとめて出力される FairMOTのポイントは、それ以前精度が低めだったReID部分の精度を強化する工夫を導入している点です。 それ以前のAnchor に則ったモデルでは対象物体の特徴量の計算に"不公平"が生じるため、FairMOTではAnchor-freeなReID計算を実現
TransMOT(STGT)
残念ながらまだ実装は公開されていないのですが、多くのベンチマークでstate-of-the-artを獲得している(2021/07 現在)のがTransMOT(STGT)です。 Spatial-Temporal Graph Transformerという独自のTransformer を利用し、end-to-endなトラッキングを実現
FastMOT
トラッキングのアルゴリズムの概要は以下
- 物体検出(デフォルトでYOLOv4 9 とSSD 10 が搭載)
- OSNet :Detectionの各bboxに対する特徴ベクトルを取得
- KLT Tracker:オプティカル・フローにより特徴点の抽出をし、カメラ自体の運動を推定、追跡物体の位置を予測
- カルマン・フィルタ:追跡物体に対するKLT Trackerの結果を利用し、最終的な物体の動きを予測
- 上記の計算を元に検出物体と追跡中の物体をマッチング (a) 特徴ベクトルと動き予測を基にしたマッチング (b) aでマッチしなかったものについて、追跡中の物体(active)とIoUでマッチング (c) bでマッチしなかったものについて、まだ一度もマッチしたことが無い追跡物体とIoUでマッチング (d) cでマッチしなかったものについて、過去にlostしたものと特徴ベクトルによりマッチング
FastMOTの利点としては、精度と速度の両面でバランスが良い点が。 デフォルトでTensorRTやNumbaを使って高速化・最適化されているため、雑にそのまま動かしても速いのも嬉しい点です。
物体検出の部分は自由な手法で良いため、RefineDetやYOLOv5など他のモデルにつけ替えが可能
motpy
motpyはTracking-by-Detectionの"Tracking"の部分をサクッと実装したいときに便利なライブラリです。独自に用意した物体検出のデータを使って、簡単にMOT機能を実装することができます 内部的にはIoUによるマッチングやカルマン・フィルタ等を主に使用しているようです。
# from https://tech-blog.optim.co.jp/entry/2021/07/07/100000
import numpy as np
from motpy import Detection, MultiObjectTracker
# 物体検出のデータを次のフォーマットで用意:[xmin, ymin, xmax, ymax]
# step timeを秒単位で指定し、Trackerを初期化
tracker = MultiObjectTracker(dt=0.1)
# トラッキング処理を走らせる
for step in range(len(object_box)):
# フレームのbboxを更新する
# ここではobject_boxは1フレームの[xmin, ymin, xmax, ymax]のデータが格納されたlistとする
tracker.step(detections=[Detection(box=object_box)])
# アクティブな追跡物体を取得する
tracks = tracker.active_tracks()
# trackはID、bbox、検出スコアの情報を持つ
print('MOT tracker tracks %d objects' % len(tracks))
print('first track box: %s' % str(tracks[0].box))trackingアルゴリズムはかなり複雑なので、motpyとかかなりありがたい。 FastMOTのアルゴリズムも参考になりそうだ。
GENZITSU
commented
3 years ago aria2を用いると、ダウンロードを並列化して待ち時間を短縮できる。 もちろん、相手サーバーにはそれだけ負荷がかかるので、注意しよう。
aria2c -x5 ftp://ftp.nara.wide.ad.jp/pub/Linux/centos/7.3.1611/isos/x86_64/CentOS-7-x86_64-Minimal-1611.iso便利そう。
自分のec2インスタンスとかだったら迷惑もかからないし、良さそ。
GENZITSU
commented
3 years ago GENZITSU
commented
3 years ago 下図のように長大なシリーズもの。

huggingface transformerで実装したいことがあったら、ここを見に来ると良いだろう。
GENZITSU
commented
3 years ago GENZITSU
commented
3 years ago GENZITSU
commented
3 years ago 機械学習の精度改善は必ずしも利益に結びつかないということである。
受託開発を主としている組織であれば工数にはシビアなので、売上の立たない工数をかけることはあまりない しかし自社で製品やサービスを作って提供しているような組織の場合、利益にならない精度改善をしているのを時折見かける。 なぜか? → データサイエンティスト/機械学習エンジニアとしての倫理感からなのではないだろうか。 倫理感や興味が先行してしまっているのだ。 しかしその精度を上げた先に利益があるとは限らない。
利益に結びつかない、または間接的にしか結びつかないような精度改善をやることが許されるというのは組織に余裕があるということで悪いことではない
しかし単によいイシューの設定ができてないだけという可能性もある。 自社で製品やサービスを作って提供しているような組織において、単純なロジスティック回帰でコアなところのビジネスを大きく加速させることができた時期を過ぎると機械学習で解くのに適したよい問題を恒常的に見つけ出すのは実は難しい
"倫理観"の強い人間なので、精度や完璧さをつい求めがちなのだが、PJT上それが必要なのか?売り上げにつながっているのか?は常に自問しないといけないのかも。
まぁ余裕がある時は、PJTをメンバーのスキルアップさせる機会と割り切ってしまうのもありだと思うけど。 ここら辺のバランス感覚難しい気がする。
GENZITSU
commented
3 years ago ビジネスモデルにはさまざまな型がある。

どの型に当てはまるかは、立場によっても変わるし、提供価値のタイプによっても変わる。




案件的に一番危険なのは、かなり高い精度が求められるのにall or nothingな案件

可能であれば問題の変換をするべき


分析コストと売り上げの関係を注意するのも大事。

外注という立場だと、ロジスティック型のビジネスモデルになるというのは目から鱗。
ロジスティックなのだけど、その閾値がだんだん上がっているイメージがある。
分析コストをかければかけるほど精度は上がるが、それに売り上げがどう相関するかは注視した方がよい。
GENZITSU
commented
3 years ago GENZITSU
commented
3 years ago こんな感じの内容がまとめられているが、自分が勉強になったのはここ

引数にbooleanを渡すということは、その値がtrueかfalseかを判定するメソッドが必要。即ち、boolean以外の引数がある場合、関数が複数のことを行うことにつながってしまいます。
# from https://zenn.dev/syouya/articles/c385870fc621bb#%E5%BC%95%E6%95%B0%E3%81%ABboolean%E3%82%92%E6%B8%A1%E3%81%99
def calculate_annual_income( is_there_bonus, saraly, monthly_benefit):
all_months = 12
total_saraly = salary * all_months
yearly_benefit = monthly_benefit * all_months
annual_income = (total_saraly + yearly_benefit) * 0.8
# この時点で年収計算しているのに、booleanがあることでボーナスがあるか否かの判定もしなければならない。
if is_there_bonus:
bonus_magification = 2.5
annual_income += salary * bonus_magification
return annual_income# from https://zenn.dev/syouya/articles/c385870fc621bb#%E5%BC%95%E6%95%B0%E3%81%ABboolean%E3%82%92%E6%B8%A1%E3%81%99
def calculate_annual_income(bonus, saraly, monthly_benefit):
all_months = 12
total_saraly = salary * all_months
yearly_benefit = monthly_benefit * all_months
annual_income = (total_saraly + yearly_benefit) * 0.8 + bonus
return annual_income引数にboolean渡しがちなので、気をつけないと。
たしかに、booleanで渡すくらいだったら、関数の外でちゃんと制御したほうがよいか。
GENZITSU
commented
3 years ago ML系プロジェクトでよくある3つの課題に対する解決策についての発表



Foldごと / 対象ユーザーごとにノードを分割して処理可能にしている。
さらに、処理ごとに必要なリソースに変更したり、プリエンティブルノードを利用している。
プリエンティブルノードとは稼働保証のないスポットインスタンス的なもの







ただただレベル高いなぁ。
gokart結構便利そう。
取り入れられるところから取り入れなければ...
GENZITSU
commented
3 years ago 近年のvision transformerの研究動向がまとめられている。
この記事のテーマは以下の4つです。 • Transformerの急速な拡大と、その理由 • TransformerとCNNの視野や挙動の違い • TransformerにSelf-Attentionは必須なのか? • Vision Transformerの弱点と改善の方向性
この記事のまとめとしての私の見解は、以下の通りです。
Vison Transformer以来、Transformerはその適用範囲を急速に拡大した。その理由として、色々なデータに適用できること、異なるモーダル間で相関を取りやすいことがあると個人的に考えている。
TransformerとCNNの大きな違いとして視野の広さが挙げられる。それに起因してか、TransformerはAdversaial PatchのパターンがCNNと異なったり、テクスチャの変化に対してCNNより頑健であるという性質がある。
最近の研究によると、TransformerにおいてSelf-Attentionは必須ではないかもしれない。個人的な見解だが、エンコーダーブロック内に大域情報を扱う部分と局所的に伝播させる部分2つがあることが重要に思える。
Vision Transformerはメモリが多く必要であること、データが大量に必要であることが弱点だが、急速に改善が進みつつある。
帰納バイアスが弱いため、良い精度を得るためにImageNet(130万データセット)より大きなJFT-300M(3億データセット)を必要とする Self-Attentionの性質上、画像の辺の長さの4乗のメモリサイズを必要とする
最近のトレンドを知るのにとても勉強になる。
GENZITSU
commented
3 years ago pyminizipを用いることで、pdfの暗号化が可能になる。
import pyminizip
for j in range(len(x)):
pyminizip.compress(x[j], "", "zipped_"+x[j]+".zip", y[j], 0)
j=j+1大量のファイルをzip化するのは普通に面倒なので、割と便利そう。
と言っても、営業とかじゃないと使う機会ないかもしれないけど。
GENZITSU
commented
3 years ago ツイート先の動画を見て欲しい。
GPU使っても30秒の映像で10分くらいかかる 使っているのはYOLOv5x6にTest Time Augmentationを加えたもの。
フィールドの要所要所を青マニュアルでアノテーションして、座標変換することで鳥瞰図の作成も可能
マニュアルアノテーションによる座標変換が意外とうまくいってるのが驚き。
変換がうまくいけば、フィールド外のスタッフとかもフィルタリングできるし。
何FPSなのかわからないけど、10分ってのは結構長そう。TTAやってるから?
GENZITSU
commented
3 years ago lightlyを用いたSimSiam (2021年7月時点の自己教師あり学習のSOTA)の実装を紹介 (torch)
keras版もある模様 https://keras.io/examples/vision/simsiam/
美術品の画像っぽいけど結構うまくいってるように見える。
散布図

KNN


色々テクがあるようだ。
Batch Size の大きさが重要なんですかね 🤔 (resnet18 の中間特徴量の次元(512)に対して proj_hidden_dim, pred_hidden_dim, out_dim が大きめなのも効いている…?) 論文中だと LR Schedule しない方がいいみたいな表がありましたが、結局データ次第なんでしょうか。
自己教師あり学習の事例嬉しい。
ちなみに、似た事例でこういうのもある。
自己教師あり対照学習でpaletteから特徴ベクトルを得る
GENZITSU
commented
3 years ago もはや出典元スライドの分かりやさすが異常なので、そちらを参照するのが良い。
こっちは備忘録





結果はまぁすごいんだけど

stop gradientと予測レイヤーがないとお話にならないらしい。。
(これはやりすぎでしょ笑)


ちなみに、BYOLのmomentum moving averageよりも相互にstop gradientした方がいいんだなぁ。

SSLは毎年のように進化してるの怖いなぁ。
近いうちに、こいつら全員意味ないよ論文出てきそう。(それこそMoCov2とそんなに変わらんしねw)
GENZITSU
commented
3 years ago 最近のモデルも含まれているし、チュートリアルも豊富

使いやすそう。
# https://github.com/lightly-ai/lightly
mport torch
import torchvision
import lightly.models as models
import lightly.loss as loss
import lightly.data as data
# the collate function applies random transforms to the input images
collate_fn = data.ImageCollateFunction(input_size=32, cj_prob=0.5)
# create a dataset from your image folder
dataset = data.LightlyDataset(input_dir='./my/cute/cats/dataset/')
# build a PyTorch dataloader
dataloader = torch.utils.data.DataLoader(
dataset, # pass the dataset to the dataloader
batch_size=128, # a large batch size helps with the learning
shuffle=True, # shuffling is important!
collate_fn=collate_fn) # apply transformations to the input images
# use a resnet backbone
resnet = torchvision.models.resnet.resnet18()
resnet = nn.Sequential(*list(resnet.children())[:-1])
# build the simclr model
model = models.SimCLR(resnet, num_ftrs=512)
# use a criterion for self-supervised learning
criterion = loss.NTXentLoss(temperature=0.5)
# get a PyTorch optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=1e-0, weight_decay=1e-5)SSL用のライブラリがあったとはなぁ。 ここまで簡単になると気軽に試せていいですね。
GENZITSU
commented
3 years ago # https://qiita.com/fumifumitaro/items/c613d033ebc94c5e608d
def preprocess(df):
excerpt_processed=[]
for e in progress_bar(df['excerpt']):
# find alphabets
e = re.sub("[^a-zA-Z]", " ", e)
# convert to lower case
e = e.lower()
# tokenize words
e = nltk.word_tokenize(e)
# remove stopwords
e = [word for word in e if not word in set(stopwords.words("english"))]
# lemmatization
lemma = nltk.WordNetLemmatizer()
e = [lemma.lemmatize(word) for word in e]
e=" ".join(e)
excerpt_processed.append(e)
return excerpt_processedBERTモデルなどは文章の前後、つまり文脈を判断するためにstopwordsを消したり語形をそろえることが返って予測を困難にしてしまう場合があります。 私が行った分析で、この前処理の後にBERTに通したのと、前処理を挟まなかった場合とで比べて前処理しないほうが誤差が少なく出たことがありました。 使いたいモデルに応じて、行うべき前処理を吟味する必要がありそうです。
関数化されていると便利。 stopwordsを消してしまうのは、やっぱりBERT系に悪影響なんだなぁ。
GENZITSU
commented
3 years ago 前後編あるが、自分の参考になったものだけ抜粋
この論文自体はよくわかっていないが、testデータに対してもactive learningする方法は良さげ。
ラベル付けが高コストな問題に対して,どのデータにラベル付けをするかを能動的に選択する能動学習がある. しかし,テストデータに対しては能動学習をせず,大量のデータで評価することが多いが現実はラベル付けが高コスト. そこで,テストデータの効率的なラベル付けのために,テストサンプルを能動的に選択するフレームワークをActive Testingとして提案. 具体的には,経験的リスク推定値の精度を最大化(分散最小化)するためにテストサンプルを選択する獲得関数を導出する. 回帰問題のテストサンプルに対する獲得関数は,二つの項の和で表現される. 1項目が,テストサンプルのラベルを予測する代理モデルの予測平均と学習モデルの予測の二乗和誤差,2項目が,代理モデルの予測分散. 代理モデルは,訓練データとテストデータで学習され,予測の不確実性を必要とするため,ベイジアンニューラルネットワークやガウス過程を用いる. 1項目を最大化する意味合いは,学習モデルの予測平均とテストデータも含めた代理モデルで誤差が大きいテストサンプルを選びやすくなる. 2項目を最大化する意味合いは,ラベルノイズである偶然誤差と今まで観測したことがない認識の誤差が大きいテストサンプルを選びやすくなる. 実験では,ランダムにテストデータを用意する方法より,テスト損失の分散を大幅に抑えた偏りのない推定値が得られた.

半教師あり学習には,ラベルなしデータに疑似ラベルをつけて学習するアプローチがある.ラベルなしデータに間違った疑似ラベルをつけると通常の教師あり学習と比べ予測性能が劣化することが知られている.したがって,どのラベルなしデータにいつ疑似ラベルをどうつけるかが重要な問題となる. 既存のFixMatchは,交差エントロピー損失を用いた分類タスクにおいて,予測確率の高い(例:0.95)ラベルなしデータに疑似ラベルをつけて学習している.しかし,固定の閾値では,モデル学習時に誤った疑似ラベルをつけてしまうこともある. そこで,提案手法は,各イテレーションおきに疑似ラベルをつけるサンプル数を動的に決定する閾値を導入した.最初は,閾値が高く徐々に減少する.既存手法に比べて,汎化性能が僅かに高かった.

身近な問題でこれがあるので、使いたい。
不均衡データに対する既存技術は,分類問題が多い中,回帰問題に対して,Deep Imbalanced Regression (DIR)を提案.ラベル空間が連続な不均衡データの例として,CVの顔画像から年齢推定タスクがある.このタスクは,年齢が連続的なターゲットであり,不均衡になる可能性がある.異なる年齢を別々のクラスとして扱うと,年齢が近い人の間の類似性を利用できないため,良い結果が得られない可能性がある. そこでラベル空間がカテゴリと連続で違う,ラベル値の近傍の類似性に着目し,ラベルと低次元特徴量の両方に対して,カーネル関数を用いた分布平滑化を行うことを提案.提案方法は,既存のFocal lossを用いた手法に付け加え拡張することも可能.また欠損のあるラベルに対しても補完することができる.実験では,CV,NLP,ヘルスケアにおける一般的なタスクから大規模なDIRデータセットを作成し実施した.結果,少数ラベルの予測性能(MAE)が既存手法より,0.2~3.0%改善した.

特に3番目のやつがに惹かれた。 カテゴリーとして処理するのもいいけど...みたいな場面結構あるし
GENZITSU
commented
3 years ago 表記列 → 素性 ではなではなく、いっぺんに表記列+素性を出力する

言いよどみを含む「ぴっちとすぺくとらすぺくとる」という発話に対する出力です。 従来法では、この2つの形態素をうまく分割できずに、読み・品詞がうまく推定できません。 一方、提案法は、テキストだけでなく音声の情報も用いることができるため、2つの形態素をうまく分割でき、読み・品詞を正しく推定できています。

(同型異音語(同じ表記でも読みが異なる語)を含む「そのごおんがくばんぐみが」という発話に対する出力です。 同型異音語の読みは従来法では一意に定めることが難しいという問題がありますが、音声の情報を使うことで正しい読みを付与できている

ただし、どうもCTCではうまくいかず、transformer+CTCを使う必要があるようだ。
ただ、この設定だと表記のみの方が誤り率が少ないのが気になるが...

とはいえ、読みと品詞に関しては提案法の方が精度が高い。

読みと品詞の読み取りはできるけど、音声認識の精度が低いってのはどういうことなんだろう...?
前段の誤りが後段に波及しているならわかるけれども...
実験設定がよくわからないが、Transformer+CTCの事前学習の仕方も悪さをしているのかもしれない...?
それかTransformerが読み誤りなどの修正までできてしまう的な...?








データ視覚化のデザインの話(その1)
1. データ視覚化のポイント3つ
![スクリーンショット 2021-07-06 22 25 33]()
円グラフを使わない
以下の理由で円グラフは適さないことの方が多い
3. 凡例は使わない
画像の通り
4. 軸ラベルは傾けない
5. コントラストに注意する
画像の通り
感想
matplotlibでこれらを再現するのは結構酷なのでパワポでやる感じかも。
matplotlibでの再現記事も見つけた。
その2,その3もある
出典
元記事