 GENZITSU
commented
3 years ago
GENZITSU
commented
3 years ago Lean AI 開発論: コードを書く前に機械学習プロジェクトを評価する方法
精度付加価値曲線の想像が必要 ① Max Value
一番考えやすいポイントは、「精度がmaxだったときにどれくらい嬉しいか」(=max valueの大きさ)である。
② MVA(Minimum Viable Accuracy)
次に考えるべきなのは、ミニマムでどのくらいの精度が出ると嬉しいのか、である。 特定精度を達成した時の結果のモックデータ、精度モックを作って気持ちを持つこともできる。 たとえば、xx%ぐらいの精度が達成された時の結果の画面を人為的に手で作ってみる
③ 人間の達成精度
人間の達成精度 < MVA」の時は要注意である。 人間にできないことを機械がやすやすとできる問題設定ももちろん中にはあるものの、あなたたちがいま機械学習で解こうとしている問題はそうではない可能性が高いのではないだろうか。
④ ベースラインモデルの精度
ここまできてからやっとコードを書き始めれば良い。今手元にあるデータセット、雑な手法で学習と評価のパイプラインを一周させるベースラインモデルの精度を測定してみる。これがMVAより高ければ万々歳だし、超えていなくても値が近ければ良いシグナルだ。
理想的なケース
MVA < ベースラインモデルの精度 <<<< 人間の精度 < 100%(max value) こんなケースはすごく筋が良さそうに見える
コメント
良 (語彙力)





















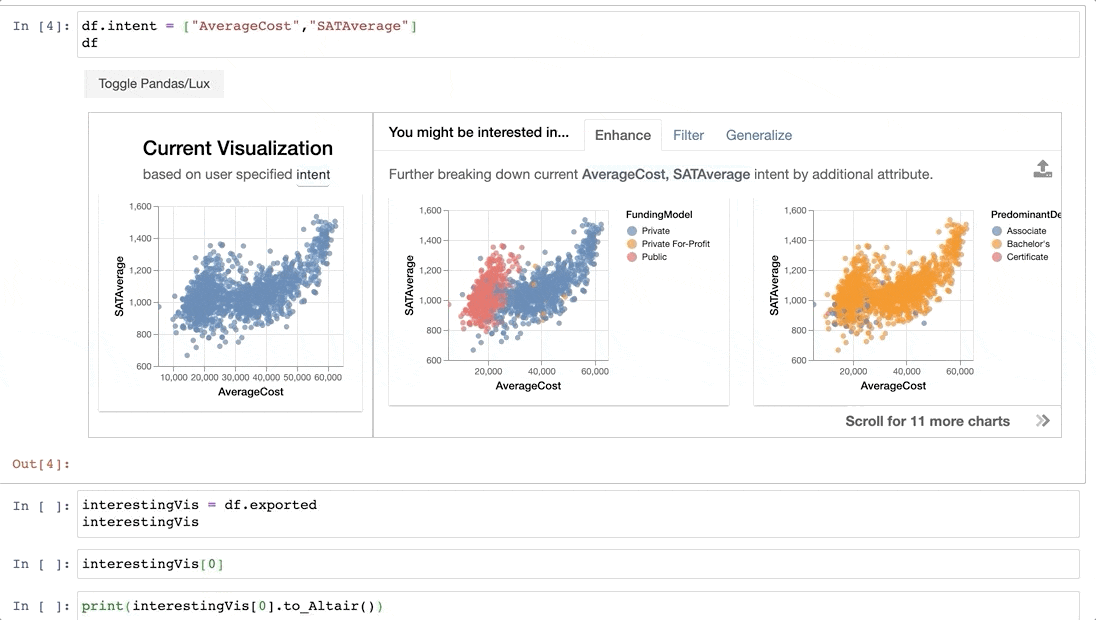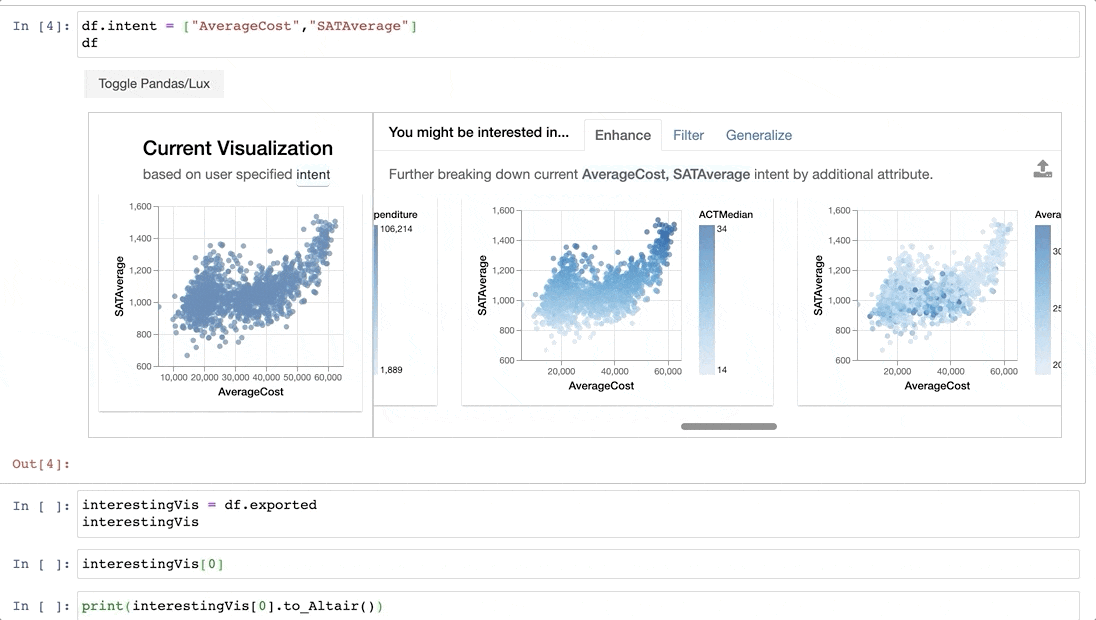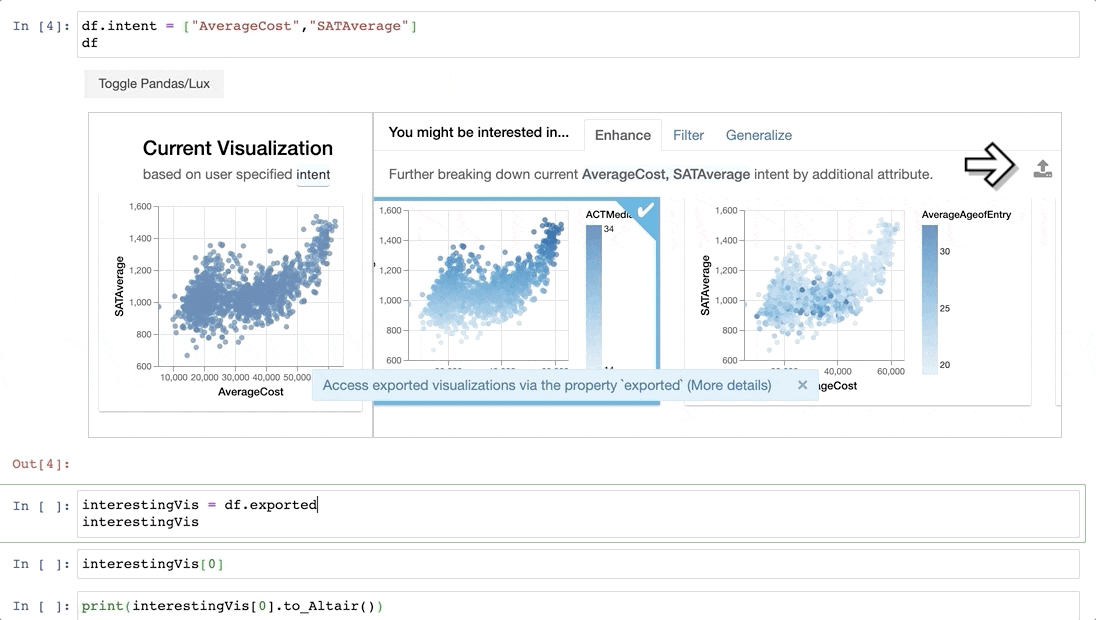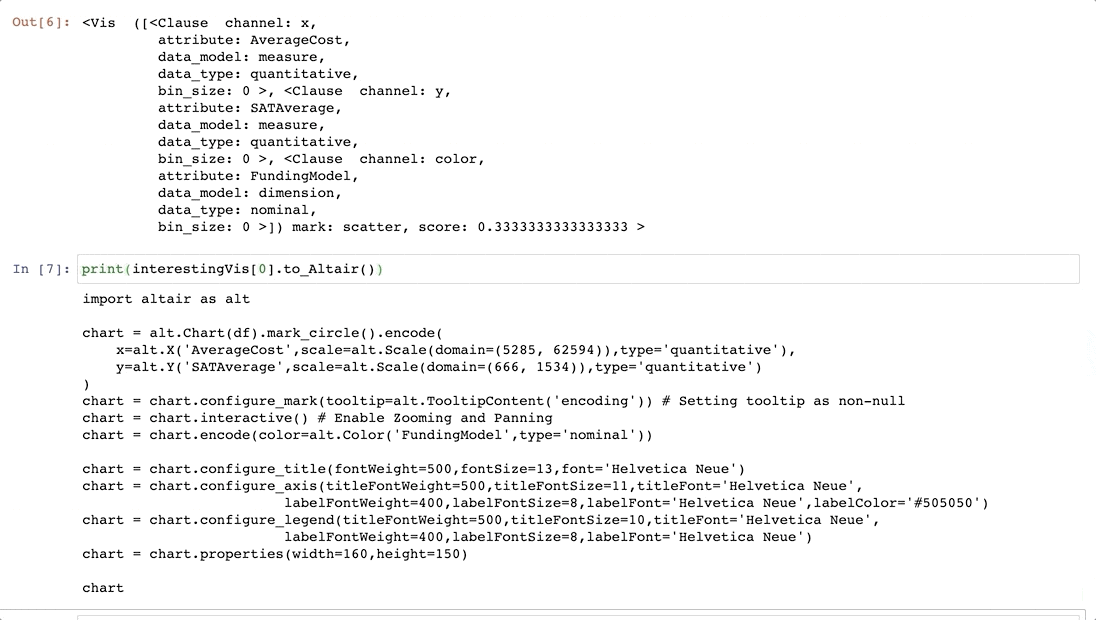









BERTで英検を解く
2021年第1回の英検の問題を各級から10問取得して、BERTでといてみた記事。
BERTによる
結果はこんなこんな感じで、peplexityが一番良い
コメント
perplexityの比較というアイデアは面白い。
コードも充実しているので、覗いてみたい。
出典
元記事
kernel
git