Open Victarry opened 3 years ago
In the original paper, the content adversarial loss is:
However, according to the code:
def backward_contentD(self, imageA, imageB): pred_fake = self.disContent.forward(imageA.detach()) pred_real = self.disContent.forward(imageB.detach()) for it, (out_a, out_b) in enumerate(zip(pred_fake, pred_real)): out_fake = nn.functional.sigmoid(out_a) out_real = nn.functional.sigmoid(out_b) all1 = torch.ones((out_real.size(0))).cuda(self.gpu) all0 = torch.zeros((out_fake.size(0))).cuda(self.gpu) ad_true_loss = nn.functional.binary_cross_entropy(out_real, all1) ad_fake_loss = nn.functional.binary_cross_entropy(out_fake, all0) loss_D = ad_true_loss + ad_fake_loss loss_D.backward() return loss_D
I think this formula should be written as: After all, the discriminator get optimal when it outputs 0.5 for all input in the situation of original formula
Duplicate Issue: #17
 Wolfybox
commented
3 years ago
Wolfybox
commented
3 years ago
In the original paper, the content adversarial loss is: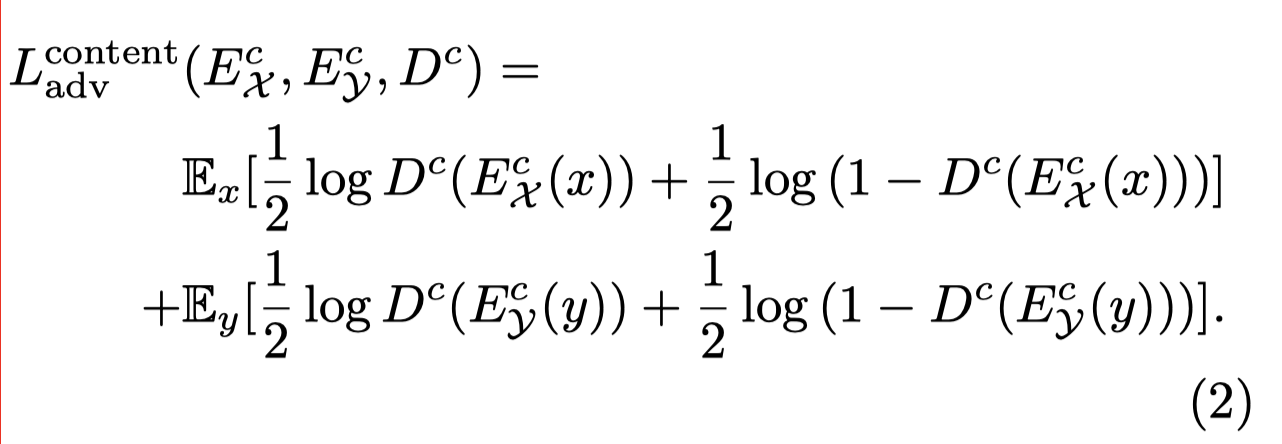
However, according to the code:
I think this formula should be written as: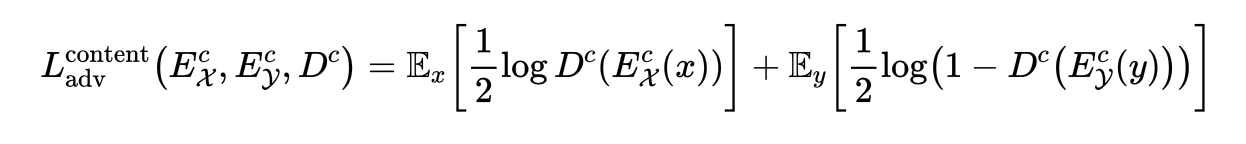 After all, the discriminator get optimal when it outputs 0.5 for all input in the situation of original formula
After all, the discriminator get optimal when it outputs 0.5 for all input in the situation of original formula